 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToMATO: Verbalizing the Mental States of Role-Playing LLMs for Benchmarking Theory of Mind
Jan 15, 2025



Existing Theory of Mind (ToM) benchmarks diverge from real-world scenarios in three aspects: 1) they assess a limited range of mental states such as beliefs, 2) false beliefs are not comprehensively explored, and 3) the diverse personality traits of characters are overlooked. To address these challenges, we introduce ToMATO, a new ToM benchmark formulated as multiple-choice QA over conversations. ToMATO is generated via LLM-LLM conversations featuring information asymmetry. By employing a prompting method that requires role-playing LLMs to verbalize their thoughts before each utterance, we capture both first- and second-order mental states across five categories: belief, intention, desire, emotion, and knowledge. These verbalized thoughts serve as answers to questions designed to assess the mental states of characters within conversations. Furthermore, the information asymmetry introduced by hiding thoughts from others induces the generation of false beliefs about various mental states. Assigning distinct personality traits to LLMs further diversifies both utterances and thoughts. ToMATO consists of 5.4k questions, 753 conversations, and 15 personality trait patterns. Our analysis shows that this dataset construction approach frequently generates false beliefs due to the information asymmetry between role-playing LLMs, and effectively reflects diverse personalities. We evaluate nine LLMs on ToMATO and find that even GPT-4o mini lags behind human performance, especially in understanding false beliefs, and lacks robustness to various personality traits.
End-to-End Joint Target and Non-Target Speakers ASR
Jun 04, 2023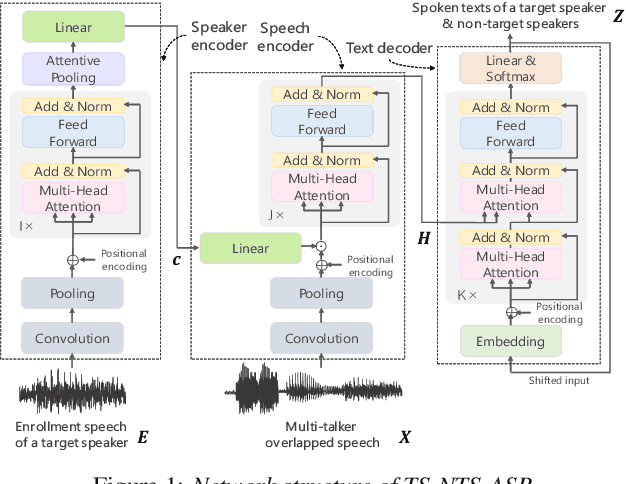


This paper proposes a novel automatic speech recognition (ASR) system that can transcribe individual speaker's speech while identifying whether they are target or non-target speakers from multi-talker overlapped speech. Target-speaker ASR systems are a promising way to only transcribe a target speaker's speech by enrolling the target speaker's information. However, in conversational ASR applications, transcribing both the target speaker's speech and non-target speakers' ones is often required to understand interactive information. To naturally consider both target and non-target speakers in a single ASR model, our idea is to extend autoregressive modeling-based multi-talker ASR systems to utilize the enrollment speech of the target speaker. Our proposed ASR is performed by recursively generating both textual tokens and tokens that represent target or non-target speakers. Our experiments demonstrate the effectiveness of our proposed method.
Downstream Task Agnostic Speech Enhancement with Self-Supervised Representation Loss
May 24, 2023



Self-supervised learning (SSL) is the latest breakthrough in speech processing, especially for label-scarce downstream tasks by leveraging massive unlabeled audio data. The noise robustness of the SSL is one of the important challenges to expanding its application. We can use speech enhancement (SE) to tackle this issue. However, the mismatch between the SE model and SSL models potentially limits its effect. In this work, we propose a new SE training criterion that minimizes the distance between clean and enhanced signals in the feature representation of the SSL model to alleviate the mismatch. We expect that the loss in the SSL domain could guide SE training to preserve or enhance various levels of characteristics of the speech signals that may be required for high-level downstream tasks. Experiments show that our proposal improves the performance of an SE and SSL pipeline on five downstream tasks with noisy input while maintaining the SE performance.