 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Time-Series Training Dataset through Lens of Spectrum in Deep State Space Models
Aug 29, 2024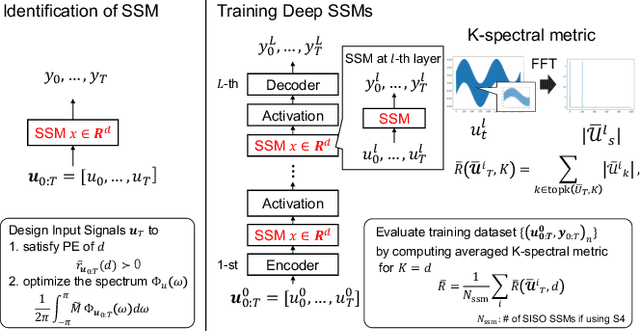

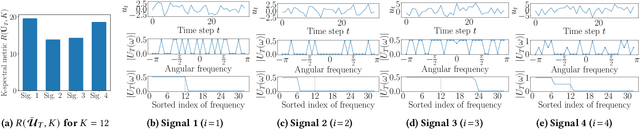
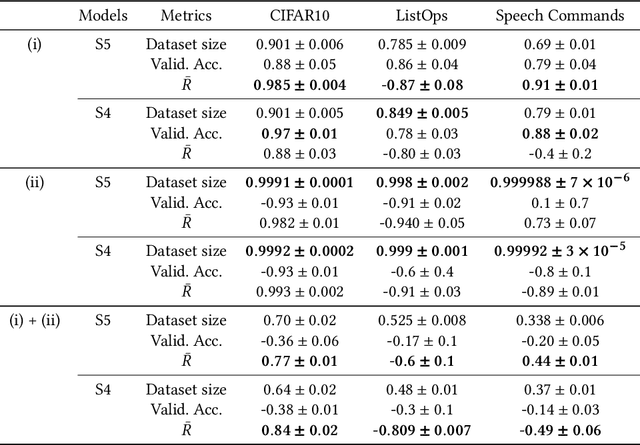
This study investigates a method to evaluate time-series datasets in terms of the performance of deep neural networks (DNNs) with state space models (deep SSMs) trained on the dataset. SSMs have attracted attention as components inside DNNs to address time-series data. Since deep SSMs have powerful representation capacities, training datasets play a crucial role in solving a new task. However, the effectiveness of training datasets cannot be known until deep SSMs are actually trained on them. This can increase the cost of data collection for new tasks, as a trial-and-error process of data collection and time-consuming training are needed to achieve the necessary performance. To advance the practical use of deep SSMs, the metric of datasets to estimate the performance early in the training can be one key element. To this end, we introduce the concept of data evaluation methods used in system identification. In system identification of linear dynamical systems, the effectiveness of datasets is evaluated by using the spectrum of input signals. We introduce this concept to deep SSMs, which are nonlinear dynamical systems. We propose the K-spectral metric, which is the sum of the top-K spectra of signals inside deep SSMs, by focusing on the fact that each layer of a deep SSM can be regarded as a linear dynamical system. Our experiments show that the K-spectral metric has a large absolute value of the correlation coefficient with the performance and can be used to evaluate the quality of training datasets.
End-to-End Joint Target and Non-Target Speakers ASR
Jun 04, 2023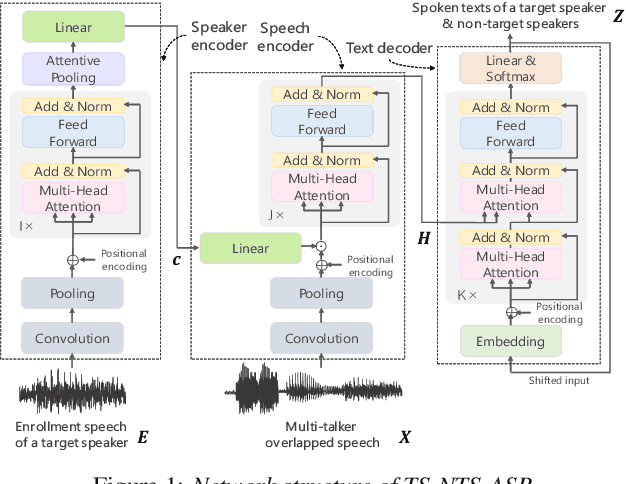


This paper proposes a novel automatic speech recognition (ASR) system that can transcribe individual speaker's speech while identifying whether they are target or non-target speakers from multi-talker overlapped speech. Target-speaker ASR systems are a promising way to only transcribe a target speaker's speech by enrolling the target speaker's information. However, in conversational ASR applications, transcribing both the target speaker's speech and non-target speakers' ones is often required to understand interactive information. To naturally consider both target and non-target speakers in a single ASR model, our idea is to extend autoregressive modeling-based multi-talker ASR systems to utilize the enrollment speech of the target speaker. Our proposed ASR is performed by recursively generating both textual tokens and tokens that represent target or non-target speakers. Our experiments demonstrate the effectiveness of our proposed method.
Audio Visual Scene-Aware Dialog Generation with Transformer-based Video Representations
Feb 21, 2022
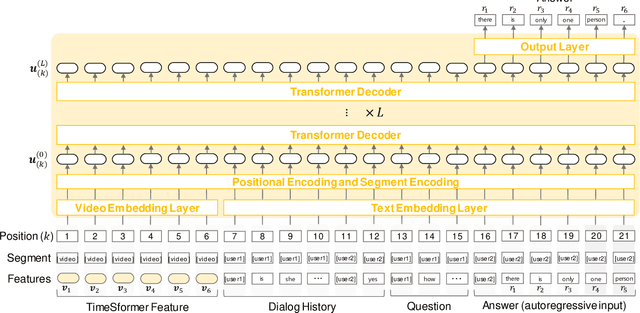
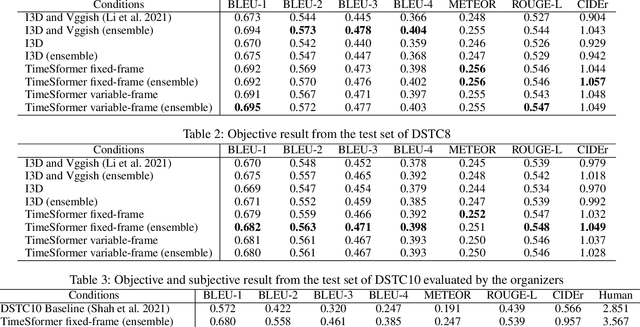
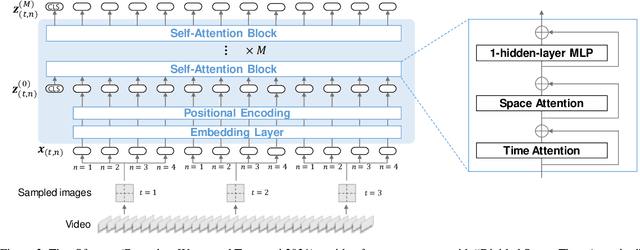
There have been many attempts to build multimodal dialog systems that can respond to a question about given audio-visual information, and the representative task for such systems is the Audio Visual Scene-Aware Dialog (AVSD). Most conventional AVSD models adopt the Convolutional Neural Network (CNN)-based video feature extractor to understand visual information. While a CNN tends to obtain both temporally and spatially local information, global information is also crucial for boosting video understanding because AVSD requires long-term temporal visual dependency and whole visual information. In this study, we apply the Transformer-based video feature that can capture both temporally and spatially global representations more efficiently than the CNN-based feature. Our AVSD model with its Transformer-based feature attains higher objective performance scores for answer generation. In addition, our model achieves a subjective score close to that of human answers in DSTC10. We observed that the Transformer-based visual feature is beneficial for the AVSD task because our model tends to correctly answer the questions that need a temporally and spatially broad range of visual information.