 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Put Ourselves in Sally's Shoes: Shoes-of-Others Prefixing Improves Theory of Mind in Large Language Models
Jun 06, 2025Recent studies have shown that Theory of Mind (ToM) in large language models (LLMs) has not reached human-level performance yet. Since fine-tuning LLMs on ToM datasets often degrades their generalization, several inference-time methods have been proposed to enhance ToM in LLMs. However, existing inference-time methods for ToM are specialized for inferring beliefs from contexts involving changes in the world state. In this study, we present a new inference-time method for ToM, Shoes-of-Others (SoO) prefixing, which makes fewer assumptions about contexts and is applicable to broader scenarios. SoO prefixing simply specifies the beginning of LLM outputs with ``Let's put ourselves in A's shoes.'', where A denotes the target character's name. We evaluate SoO prefixing on two benchmarks that assess ToM in conversational and narrative contexts without changes in the world state and find that it consistently improves ToM across five categories of mental states. Our analysis suggests that SoO prefixing elicits faithful thoughts, thereby improving the ToM performance.
Audio Visual Scene-Aware Dialog Generation with Transformer-based Video Representations
Feb 21, 2022
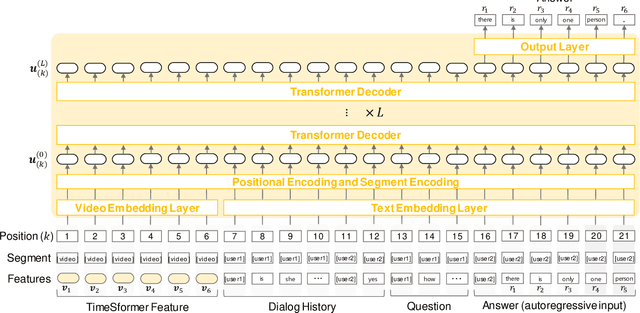
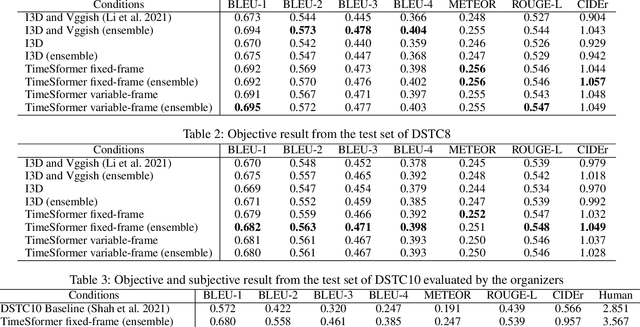
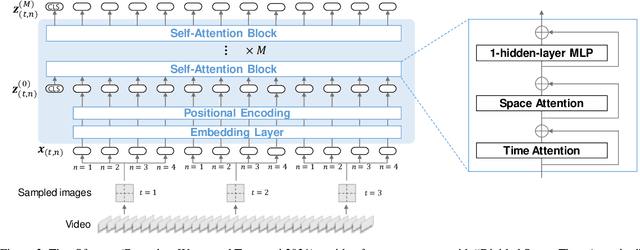
There have been many attempts to build multimodal dialog systems that can respond to a question about given audio-visual information, and the representative task for such systems is the Audio Visual Scene-Aware Dialog (AVSD). Most conventional AVSD models adopt the Convolutional Neural Network (CNN)-based video feature extractor to understand visual information. While a CNN tends to obtain both temporally and spatially local information, global information is also crucial for boosting video understanding because AVSD requires long-term temporal visual dependency and whole visual information. In this study, we apply the Transformer-based video feature that can capture both temporally and spatially global representations more efficiently than the CNN-based feature. Our AVSD model with its Transformer-based feature attains higher objective performance scores for answer generation. In addition, our model achieves a subjective score close to that of human answers in DSTC10. We observed that the Transformer-based visual feature is beneficial for the AVSD task because our model tends to correctly answer the questions that need a temporally and spatially broad range of visual information.
Utilizing Resource-Rich Language Datasets for End-to-End Scene Text Recognition in Resource-Poor Languages
Nov 24, 2021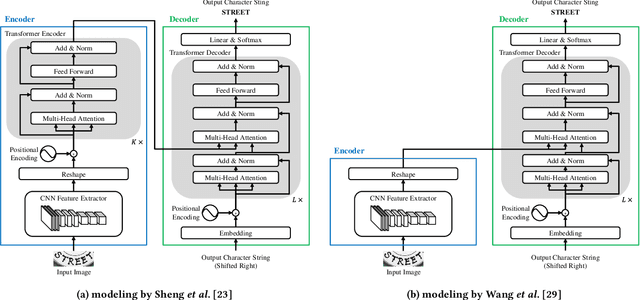
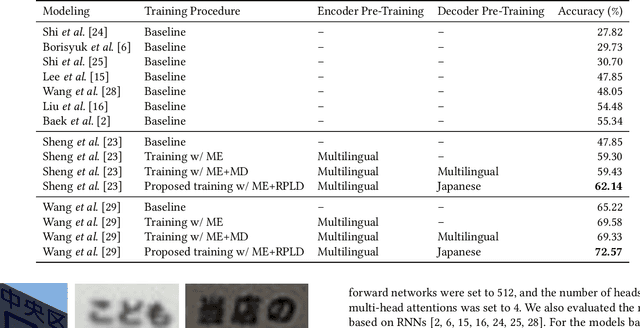
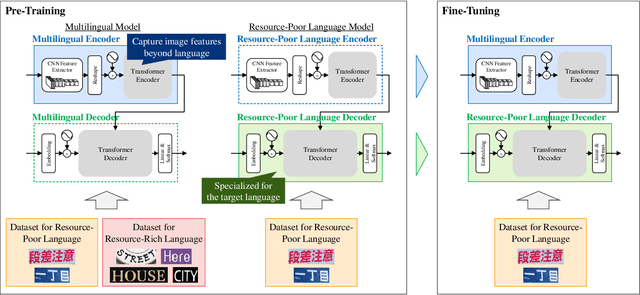
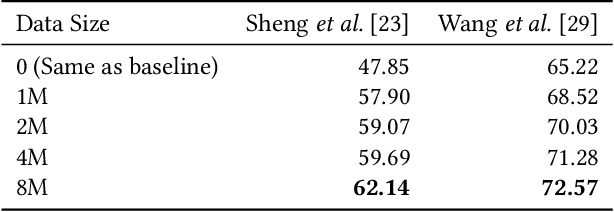
This paper presents a novel training method for end-to-end scene text recognition. End-to-end scene text recognition offers high recognition accuracy, especially when using the encoder-decoder model based on Transformer. To train a highly accurate end-to-end model, we need to prepare a large image-to-text paired dataset for the target language. However, it is difficult to collect this data, especially for resource-poor languages. To overcome this difficulty, our proposed method utilizes well-prepared large datasets in resource-rich languages such as English, to train the resource-poor encoder-decoder model. Our key idea is to build a model in which the encoder reflects knowledge of multiple languages while the decoder specializes in knowledge of just the resource-poor language. To this end, the proposed method pre-trains the encoder by using a multilingual dataset that combines the resource-poor language's dataset and the resource-rich language's dataset to learn language-invariant knowledge for scene text recognition. The proposed method also pre-trains the decoder by using the resource-poor language's dataset to make the decoder better suited to the resource-poor language. Experiments on Japanese scene text recognition using a small, publicly available dataset demonstrate the effectiveness of the proposed method.
Hierarchical Knowledge Distillation for Dialogue Sequence Labeling
Nov 22, 2021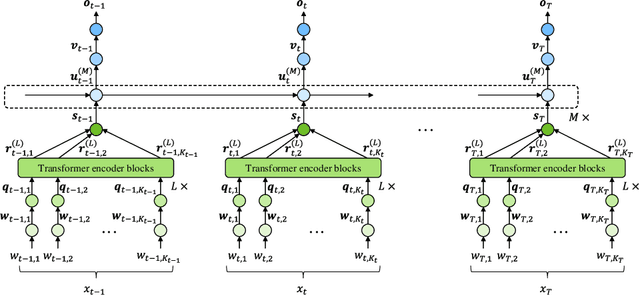
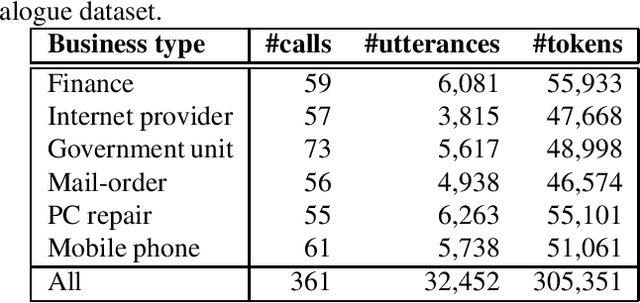
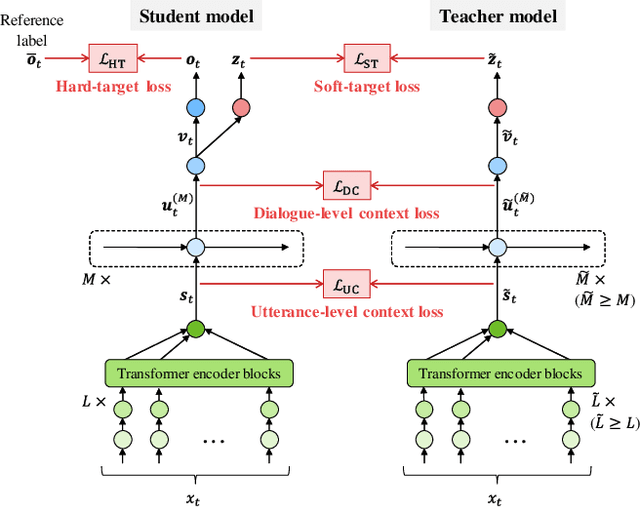
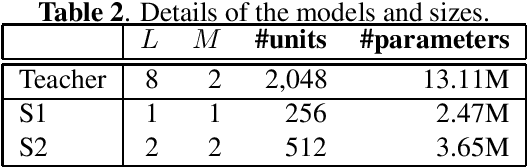
This paper presents a novel knowledge distillation method for dialogue sequence labeling. Dialogue sequence labeling is a supervised learning task that estimates labels for each utterance in the target dialogue document, and is useful for many applications such as dialogue act estimation. Accurate labeling is often realized by a hierarchically-structured large model consisting of utterance-level and dialogue-level networks that capture the contexts within an utterance and between utterances, respectively. However, due to its large model size, such a model cannot be deployed on resource-constrained devices. To overcome this difficulty, we focus on knowledge distillation which trains a small model by distilling the knowledge of a large and high performance teacher model. Our key idea is to distill the knowledge while keeping the complex contexts captured by the teacher model. To this end, the proposed method, hierarchical knowledge distillation, trains the small model by distilling not only the probability distribution of the label classification, but also the knowledge of utterance-level and dialogue-level contexts trained in the teacher model by training the model to mimic the teacher model's output in each level. Experiments on dialogue act estimation and call scene segmentation demonstrate the effectiveness of the proposed method.
Network of two-Chinese-character compound words in Japanese language
Feb 24, 2009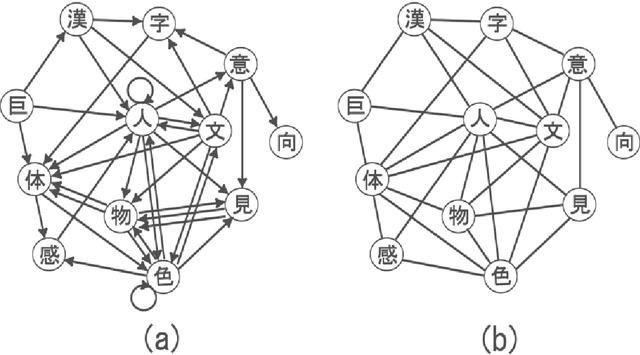

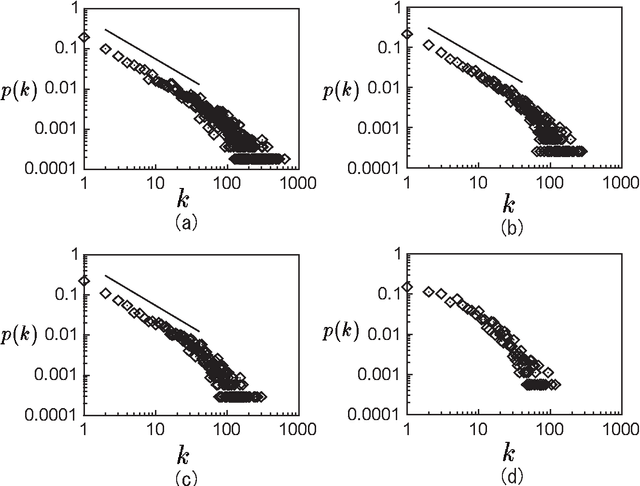

Some statistical properties of a network of two-Chinese-character compound words in Japanese language are reported. In this network, a node represents a Chinese character and an edge represents a two-Chinese-character compound word. It is found that this network has properties of "small-world" and "scale-free." A network formed by only Chinese characters for common use ({\it joyo-kanji} in Japanese), which is regarded as a subclass of the original network, also has small-world property. However, a degree distribution of the network exhibits no clear power law. In order to reproduce disappearance of the power-law property, a model for a selecting process of the Chinese characters for common use is proposed.