 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Put Ourselves in Sally's Shoes: Shoes-of-Others Prefixing Improves Theory of Mind in Large Language Models
Jun 06, 2025Recent studies have shown that Theory of Mind (ToM) in large language models (LLMs) has not reached human-level performance yet. Since fine-tuning LLMs on ToM datasets often degrades their generalization, several inference-time methods have been proposed to enhance ToM in LLMs. However, existing inference-time methods for ToM are specialized for inferring beliefs from contexts involving changes in the world state. In this study, we present a new inference-time method for ToM, Shoes-of-Others (SoO) prefixing, which makes fewer assumptions about contexts and is applicable to broader scenarios. SoO prefixing simply specifies the beginning of LLM outputs with ``Let's put ourselves in A's shoes.'', where A denotes the target character's name. We evaluate SoO prefixing on two benchmarks that assess ToM in conversational and narrative contexts without changes in the world state and find that it consistently improves ToM across five categories of mental states. Our analysis suggests that SoO prefixing elicits faithful thoughts, thereby improving the ToM performance.
Enhancing Impression Change Prediction in Speed Dating Simulations Based on Speakers' Personalities
Feb 07, 2025



This paper focuses on simulating text dialogues in which impressions between speakers improve during speed dating. This simulation involves selecting an utterance from multiple candidates generated by a text generation model that replicates a specific speaker's utterances, aiming to improve the impression of the speaker. Accurately selecting an utterance that improves the impression is crucial for the simulation. We believe that whether an utterance improves a dialogue partner's impression of the speaker may depend on the personalities of both parties. However, recent methods for utterance selection do not consider the impression per utterance or the personalities. To address this, we propose a method that predicts whether an utterance improves a partner's impression of the speaker, considering the personalities. The evaluation results showed that personalities are useful in predicting impression changes per utterance. Furthermore, we conducted a human evaluation of simulated dialogues using our method. The results showed that it could simulate dialogues more favorably received than those selected without considering personalities.
ToMATO: Verbalizing the Mental States of Role-Playing LLMs for Benchmarking Theory of Mind
Jan 15, 2025



Existing Theory of Mind (ToM) benchmarks diverge from real-world scenarios in three aspects: 1) they assess a limited range of mental states such as beliefs, 2) false beliefs are not comprehensively explored, and 3) the diverse personality traits of characters are overlooked. To address these challenges, we introduce ToMATO, a new ToM benchmark formulated as multiple-choice QA over conversations. ToMATO is generated via LLM-LLM conversations featuring information asymmetry. By employing a prompting method that requires role-playing LLMs to verbalize their thoughts before each utterance, we capture both first- and second-order mental states across five categories: belief, intention, desire, emotion, and knowledge. These verbalized thoughts serve as answers to questions designed to assess the mental states of characters within conversations. Furthermore, the information asymmetry introduced by hiding thoughts from others induces the generation of false beliefs about various mental states. Assigning distinct personality traits to LLMs further diversifies both utterances and thoughts. ToMATO consists of 5.4k questions, 753 conversations, and 15 personality trait patterns. Our analysis shows that this dataset construction approach frequently generates false beliefs due to the information asymmetry between role-playing LLMs, and effectively reflects diverse personalities. We evaluate nine LLMs on ToMATO and find that even GPT-4o mini lags behind human performance, especially in understanding false beliefs, and lacks robustness to various personality traits.
User-Specific Dialogue Generation with User Profile-Aware Pre-Training Model and Parameter-Efficient Fine-Tuning
Sep 02, 2024



This paper addresses user-specific dialogs. In contrast to previous research on personalized dialogue focused on achieving virtual user dialogue as defined by persona descriptions, user-specific dialogue aims to reproduce real-user dialogue beyond persona-based dialogue. Fine-tuning using the target user's dialogue history is an efficient learning method for a user-specific model. However, it is prone to overfitting and model destruction due to the small amount of data. Therefore, we propose a learning method for user-specific models by combining parameter-efficient fine-tuning with a pre-trained dialogue model that includes user profiles. Parameter-efficient fine-tuning adds a small number of parameters to the entire model, so even small amounts of training data can be trained efficiently and are robust to model destruction. In addition, the pre-trained model, which is learned by adding simple prompts for automatically inferred user profiles, can generate speech with enhanced knowledge of the user's profile, even when there is little training data during fine-tuning. In experiments, we compared the proposed model with large-language-model utterance generation using prompts containing users' personal information. Experiments reproducing real users' utterances revealed that the proposed model can generate utterances with higher reproducibility than the compared methods, even with a small model.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Bipartite-play Dialogue Collection for Practical Automatic Evaluation of Dialogue Systems
Nov 19, 2022Automation of dialogue system evaluation is a driving force for the efficient development of dialogue systems. This paper introduces the bipartite-play method, a dialogue collection method for automating dialogue system evaluation. It addresses the limitations of existing dialogue collection methods: (i) inability to compare with systems that are not publicly available, and (ii) vulnerability to cheating by intentionally selecting systems to be compared. Experimental results show that the automatic evaluation using the bipartite-play method mitigates these two drawbacks and correlates as strongly with human subjectivity as existing methods.
Spoken Dialogue Strategy Focusing on Asymmetric Communication with Android Robots
Oct 18, 2022
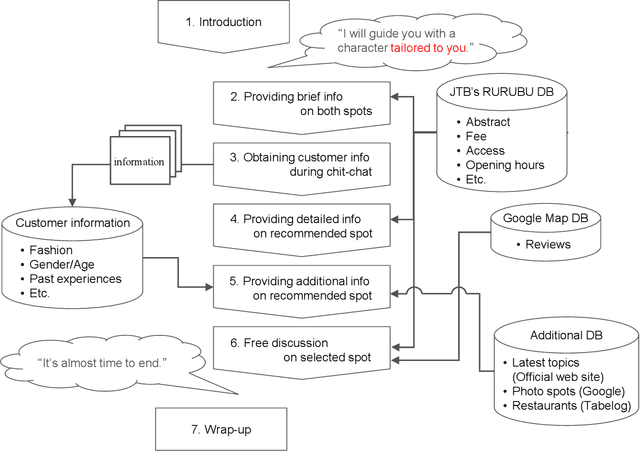
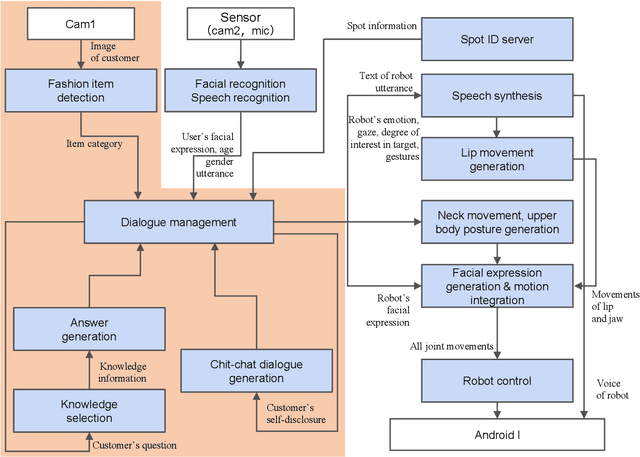
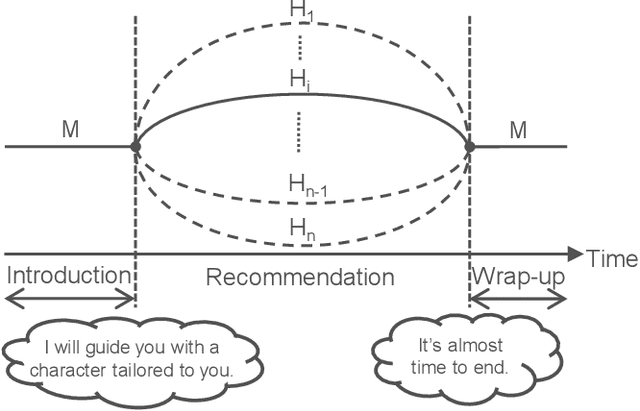
Humans are easily conscious of small differences in an android robot's (AR's) behaviors and utterances, resulting in treating the AR as not-human, while ARs treat us as humans. Thus, there exists asymmetric communication between ARs and humans. In our system at Dialogue Robot Competition 2022, this asymmetry was a considerable research target in our dialogue strategy. For example, tricky phrases such as questions related to personal matters and forceful requests for agreement were experimentally used in AR's utterances. We assumed that these AR phrases would have a reasonable chance of success, although humans would likely hesitate to use the phrases. Additionally, during a five-minute dialogue, our AR's character, such as its voice tones and sentence expressions, changed from mechanical to human-like type in order to pretend to tailor to customers. The characteristics of the AR developed by our team, DSML-TDU, are introduced in this paper.
Empirical Analysis of Training Strategies of Transformer-based Japanese Chit-chat Systems
Sep 11, 2021

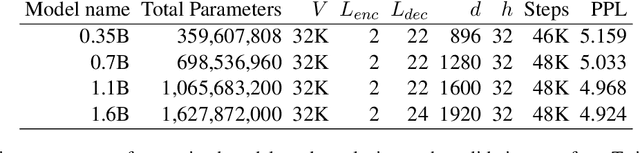
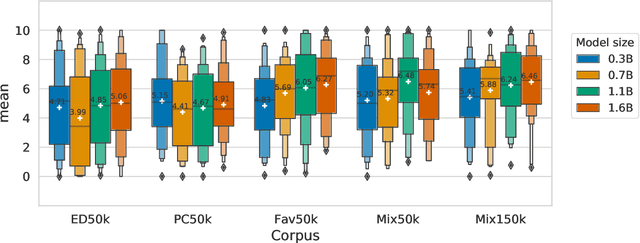
In recent years, several high-performance conversational systems have been proposed based on the Transformer encoder-decoder model. Although previous studies analyzed the effects of the model parameters and the decoding method on subjective dialogue evaluations with overall metrics, they did not analyze how the differences of fine-tuning datasets affect on user's detailed impression. In addition, the Transformer-based approach has only been verified for English, not for such languages with large inter-language distances as Japanese. In this study, we develop large-scale Transformer-based Japanese dialogue models and Japanese chit-chat datasets to examine the effectiveness of the Transformer-based approach for building chit-chat dialogue systems. We evaluated and analyzed the impressions of human dialogues in different fine-tuning datasets, model parameters, and the use of additional information.