 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactive User Information Acquisition via Chats on User-Favored Topics
Apr 10, 2025Chat-oriented dialogue systems designed to provide tangible benefits, such as sharing the latest news or preventing frailty in senior citizens, often require Proactive acquisition of specific user Information via chats on user-faVOred Topics (PIVOT). This study proposes the PIVOT task, designed to advance the technical foundation for these systems. In this task, a system needs to acquire the answers of a user to predefined questions without making the user feel abrupt while engaging in a chat on a predefined topic. We found that even recent large language models (LLMs) show a low success rate in the PIVOT task. We constructed a dataset suitable for the analysis to develop more effective systems. Finally, we developed a simple but effective system for this task by incorporating insights obtained through the analysis of this dataset.
User Willingness-aware Sales Talk Dataset
Dec 27, 2024User willingness is a crucial element in the sales talk process that affects the achievement of the salesperson's or sales system's objectives. Despite the importance of user willingness, to the best of our knowledge, no previous study has addressed the development of automated sales talk dialogue systems that explicitly consider user willingness. A major barrier is the lack of sales talk datasets with reliable user willingness data. Thus, in this study, we developed a user willingness-aware sales talk collection by leveraging the ecological validity concept, which is discussed in the field of human-computer interaction. Our approach focused on three types of user willingness essential in real sales interactions. We created a dialogue environment that closely resembles real-world scenarios to elicit natural user willingness, with participants evaluating their willingness at the utterance level from multiple perspectives. We analyzed the collected data to gain insights into practical user willingness-aware sales talk strategies. In addition, as a practical application of the constructed dataset, we developed and evaluated a sales dialogue system aimed at enhancing the user's intent to purchase.
A Large Collection of Model-generated Contradictory Responses for Consistency-aware Dialogue Systems
Mar 19, 2024Mitigating the generation of contradictory responses poses a substantial challenge in dialogue response generation. The quality and quantity of available contradictory response data play a vital role in suppressing these contradictions, offering two significant benefits. First, having access to large contradiction data enables a comprehensive examination of their characteristics. Second, data-driven methods to mitigate contradictions may be enhanced with large-scale contradiction data for training. Nevertheless, no attempt has been made to build an extensive collection of model-generated contradictory responses. In this paper, we build a large dataset of response generation models' contradictions for the first time. Then, we acquire valuable insights into the characteristics of model-generated contradictions through an extensive analysis of the collected responses. Lastly, we also demonstrate how this dataset substantially enhances the performance of data-driven contradiction suppression methods.
Bipartite-play Dialogue Collection for Practical Automatic Evaluation of Dialogue Systems
Nov 19, 2022Automation of dialogue system evaluation is a driving force for the efficient development of dialogue systems. This paper introduces the bipartite-play method, a dialogue collection method for automating dialogue system evaluation. It addresses the limitations of existing dialogue collection methods: (i) inability to compare with systems that are not publicly available, and (ii) vulnerability to cheating by intentionally selecting systems to be compared. Experimental results show that the automatic evaluation using the bipartite-play method mitigates these two drawbacks and correlates as strongly with human subjectivity as existing methods.
Target-Guided Open-Domain Conversation Planning
Sep 20, 2022
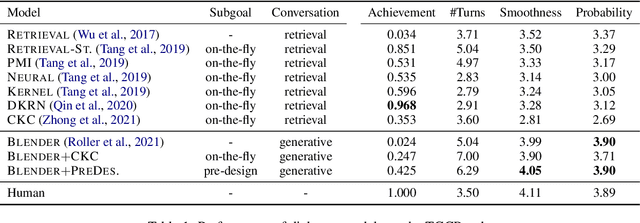


Prior studies addressing target-oriented conversational tasks lack a crucial notion that has been intensively studied in the context of goal-oriented artificial intelligence agents, namely, planning. In this study, we propose the task of Target-Guided Open-Domain Conversation Planning (TGCP) task to evaluate whether neural conversational agents have goal-oriented conversation planning abilities. Using the TGCP task, we investigate the conversation planning abilities of existing retrieval models and recent strong generative models. The experimental results reveal the challenges facing current technology.
N-best Response-based Analysis of Contradiction-awareness in Neural Response Generation Models
Aug 04, 2022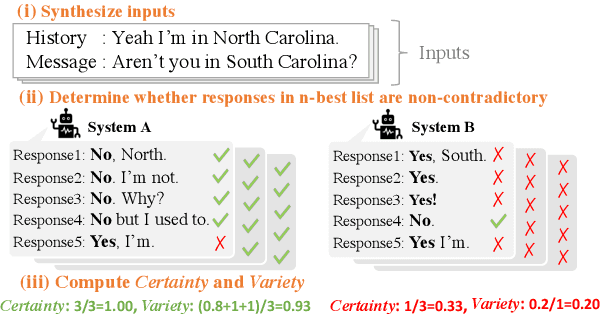

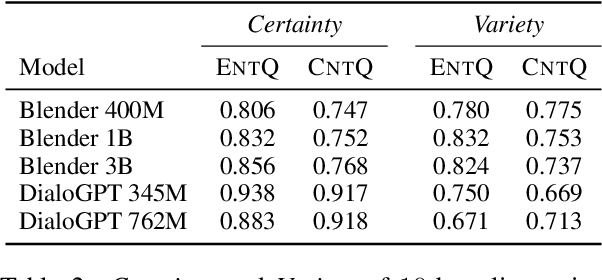
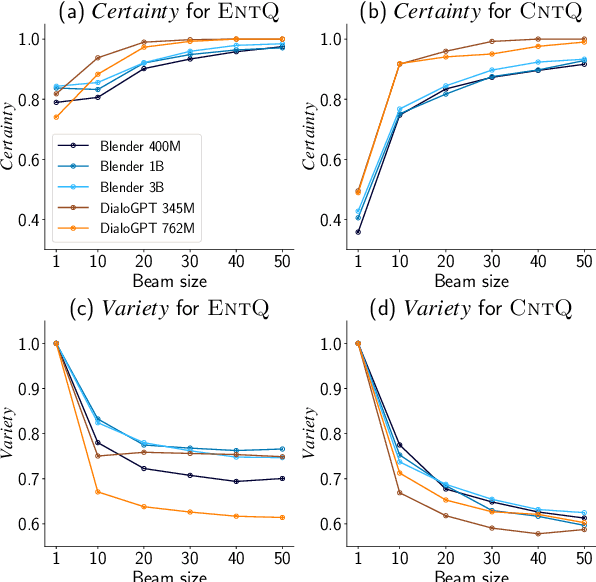
Avoiding the generation of responses that contradict the preceding context is a significant challenge in dialogue response generation. One feasible method is post-processing, such as filtering out contradicting responses from a resulting n-best response list. In this scenario, the quality of the n-best list considerably affects the occurrence of contradictions because the final response is chosen from this n-best list. This study quantitatively analyzes the contextual contradiction-awareness of neural response generation models using the consistency of the n-best lists. Particularly, we used polar questions as stimulus inputs for concise and quantitative analyses. Our tests illustrate the contradiction-awareness of recent neural response generation models and methodologies, followed by a discussion of their properties and limitations.
Evaluating Dialogue Generation Systems via Response Selection
Apr 29, 2020



Existing automatic evaluation metrics for open-domain dialogue response generation systems correlate poorly with human evaluation. We focus on evaluating response generation systems via response selection. To evaluate systems properly via response selection, we propose the method to construct response selection test sets with well-chosen false candidates. Specifically, we propose to construct test sets filtering out some types of false candidates: (i) those unrelated to the ground-truth response and (ii) those acceptable as appropriate responses. Through experiments, we demonstrate that evaluating systems via response selection with the test sets developed by our method correlates more strongly with human evaluation, compared with widely used automatic evaluation metrics such as BLEU.