 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Impression Change Prediction in Speed Dating Simulations Based on Speakers' Personalities
Feb 07, 2025



This paper focuses on simulating text dialogues in which impressions between speakers improve during speed dating. This simulation involves selecting an utterance from multiple candidates generated by a text generation model that replicates a specific speaker's utterances, aiming to improve the impression of the speaker. Accurately selecting an utterance that improves the impression is crucial for the simulation. We believe that whether an utterance improves a dialogue partner's impression of the speaker may depend on the personalities of both parties. However, recent methods for utterance selection do not consider the impression per utterance or the personalities. To address this, we propose a method that predicts whether an utterance improves a partner's impression of the speaker, considering the personalities. The evaluation results showed that personalities are useful in predicting impression changes per utterance. Furthermore, we conducted a human evaluation of simulated dialogues using our method. The results showed that it could simulate dialogues more favorably received than those selected without considering personalities.
Investigating Role of Big Five Personality Traits in Audio-Visual Rapport Estimation
Oct 07, 2024Automatic rapport estimation in social interactions is a central component of affective computing. Recent reports have shown that the estimation performance of rapport in initial interactions can be improved by using the participant's personality traits as the model's input. In this study, we investigate whether this findings applies to interactions between friends by developing rapport estimation models that utilize nonverbal cues (audio and facial expressions) as inputs. Our experimental results show that adding Big Five features (BFFs) to nonverbal features can improve the estimation performance of self-reported rapport in dyadic interactions between friends. Next, we demystify how BFFs improve the estimation performance of rapport through a comparative analysis between models with and without BFFs. We decompose rapport ratings into perceiver effects (people's tendency to rate other people), target effects (people's tendency to be rated by other people), and relationship effects (people's unique ratings for a specific person) using the social relations model. We then analyze the extent to which BFFs contribute to capturing each effect. Our analysis demonstrates that the perceiver's and the target's BFFs lead estimation models to capture the perceiver and the target effects, respectively. Furthermore, our experimental results indicate that the combinations of facial expression features and BFFs achieve best estimation performances not only in estimating rapport ratings, but also in estimating three effects. Our study is the first step toward understanding why personality-aware estimation models of interpersonal perception accomplish high estimation performance.
User-Specific Dialogue Generation with User Profile-Aware Pre-Training Model and Parameter-Efficient Fine-Tuning
Sep 02, 2024



This paper addresses user-specific dialogs. In contrast to previous research on personalized dialogue focused on achieving virtual user dialogue as defined by persona descriptions, user-specific dialogue aims to reproduce real-user dialogue beyond persona-based dialogue. Fine-tuning using the target user's dialogue history is an efficient learning method for a user-specific model. However, it is prone to overfitting and model destruction due to the small amount of data. Therefore, we propose a learning method for user-specific models by combining parameter-efficient fine-tuning with a pre-trained dialogue model that includes user profiles. Parameter-efficient fine-tuning adds a small number of parameters to the entire model, so even small amounts of training data can be trained efficiently and are robust to model destruction. In addition, the pre-trained model, which is learned by adding simple prompts for automatically inferred user profiles, can generate speech with enhanced knowledge of the user's profile, even when there is little training data during fine-tuning. In experiments, we compared the proposed model with large-language-model utterance generation using prompts containing users' personal information. Experiments reproducing real users' utterances revealed that the proposed model can generate utterances with higher reproducibility than the compared methods, even with a small model.
Learning Language and Multimodal Privacy-Preserving Markers of Mood from Mobile Data
Jun 24, 2021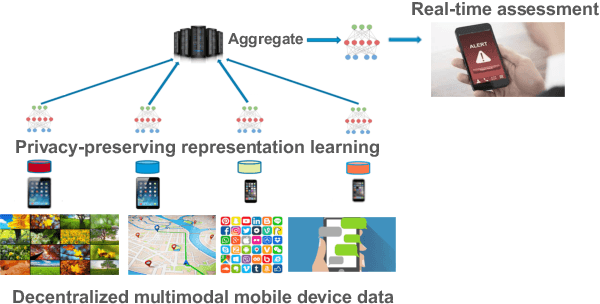
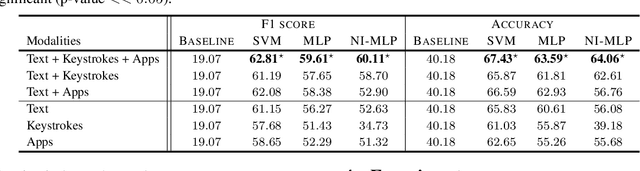
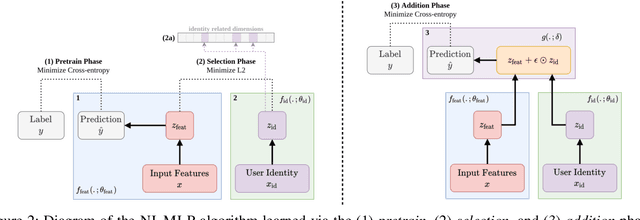
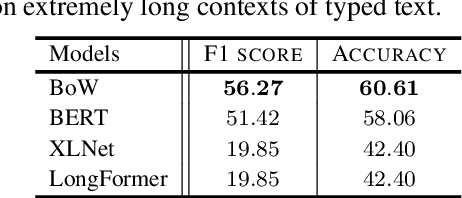
Mental health conditions remain underdiagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications for the early detection, intervention, and treatment of mental health disorders. One promising data source to help monitor human behavior is daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected (e.g., race, gender) attributes. In this paper, we study behavioral markers of daily mood using a recent dataset of mobile behaviors from adolescent populations at high risk of suicidal behaviors. Using computational models, we find that language and multimodal representations of mobile typed text (spanning typed characters, words, keystroke timings, and app usage) are predictive of daily mood. However, we find that models trained to predict mood often also capture private user identities in their intermediate representations. To tackle this problem, we evaluate approaches that obfuscate user identity while remaining predictive. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier.
Multimodal Privacy-preserving Mood Prediction from Mobile Data: A Preliminary Study
Dec 04, 2020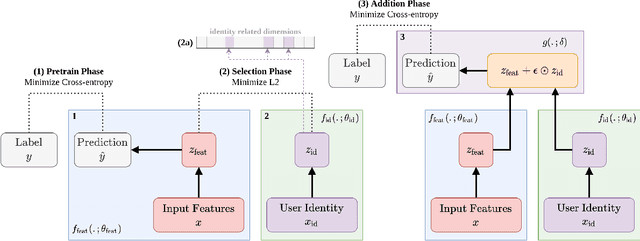
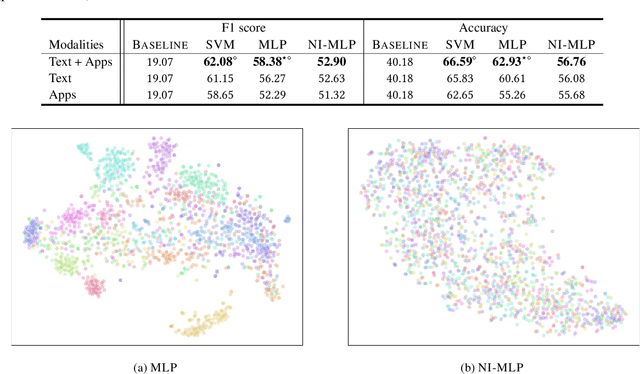
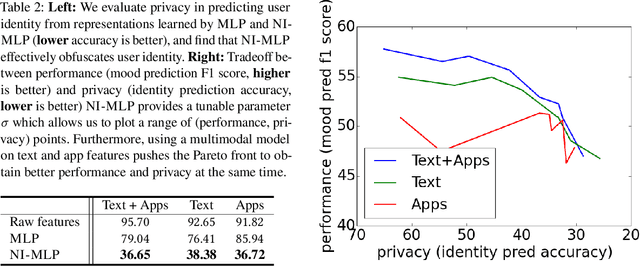
Mental health conditions remain under-diagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications towards the early detection and intervention of mental health disorders. One promising data source to help monitor human behavior is from daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected attributes (e.g., race, gender). In this paper, we study behavioral markers or daily mood using a recent dataset of mobile behaviors from high-risk adolescent populations. Using computational models, we find that multimodal modeling of both text and app usage features is highly predictive of daily mood over each modality alone. Furthermore, we evaluate approaches that reliably obfuscate user identity while remaining predictive of daily mood. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier as compared to unimodal approaches.