 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcological mapping with geospatial foundation models
Feb 11, 2026Geospatial foundation models (GFMs) are a fast-emerging paradigm for various geospatial tasks, such as ecological mapping. However, the utility of GFMs has not been fully explored for high-value use cases. This study aims to explore the utility, challenges and opportunities associated with the application of GFMs for ecological uses. In this regard, we fine-tune several pretrained AI models, namely, Prithvi-E0-2.0 and TerraMind, across three use cases, and compare this with a baseline ResNet-101 model. Firstly, we demonstrate TerraMind's LULC generation capabilities. Lastly, we explore the utility of the GFMs in forest functional trait mapping and peatlands detection. In all experiments, the GFMs outperform the baseline ResNet models. In general TerraMind marginally outperforms Prithvi. However, with additional modalities TerraMind significantly outperforms the baseline ResNet and Prithvi models. Nonetheless, consideration should be given to the divergence of input data from pretrained modalities. We note that these models would benefit from higher resolution and more accurate labels, especially for use cases where pixel-level dynamics need to be mapped.
Fine-tuning of Geospatial Foundation Models for Aboveground Biomass Estimation
Jun 28, 2024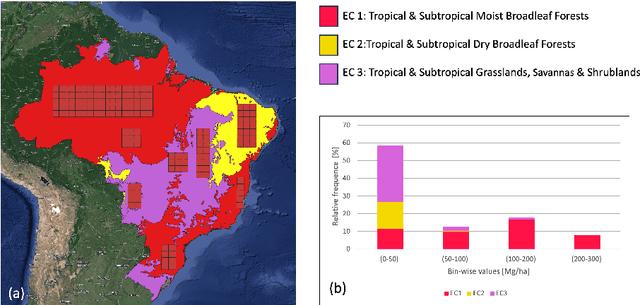

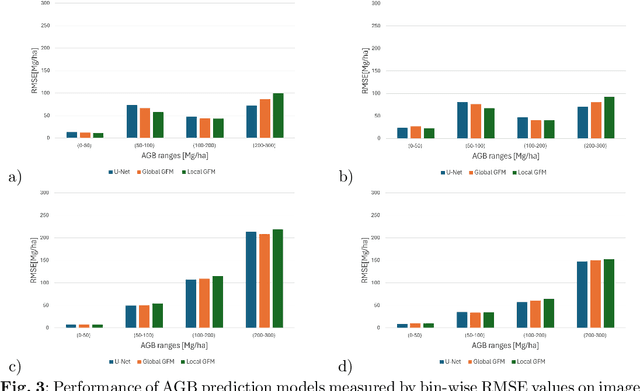
Global vegetation structure mapping is critical for understanding the global carbon cycle and maximizing the efficacy of nature-based carbon sequestration initiatives. Moreover, vegetation structure mapping can help reduce the impacts of climate change by, for example, guiding actions to improve water security, increase biodiversity and reduce flood risk. Global satellite measurements provide an important set of observations for monitoring and managing deforestation and degradation of existing forests, natural forest regeneration, reforestation, biodiversity restoration, and the implementation of sustainable agricultural practices. In this paper, we explore the effectiveness of fine-tuning of a geospatial foundation model to estimate above-ground biomass (AGB) using space-borne data collected across different eco-regions in Brazil. The fine-tuned model architecture consisted of a Swin-B transformer as the encoder (i.e., backbone) and a single convolutional layer for the decoder head. All results were compared to a U-Net which was trained as the baseline model Experimental results of this sparse-label prediction task demonstrate that the fine-tuned geospatial foundation model with a frozen encoder has comparable performance to a U-Net trained from scratch. This is despite the fine-tuned model having 13 times less parameters requiring optimization, which saves both time and compute resources. Further, we explore the transfer-learning capabilities of the geospatial foundation models by fine-tuning on satellite imagery with sparse labels from different eco-regions in Brazil.
Foundation Models for Generalist Geospatial Artificial Intelligence
Nov 08, 2023Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.
Toward Foundation Models for Earth Monitoring: Generalizable Deep Learning Models for Natural Hazard Segmentation
Jan 23, 2023



Climate change results in an increased probability of extreme weather events that put societies and businesses at risk on a global scale. Therefore, near real-time mapping of natural hazards is an emerging priority for the support of natural disaster relief, risk management, and informing governmental policy decisions. Recent methods to achieve near real-time mapping increasingly leverage deep learning (DL). However, DL-based approaches are designed for one specific task in a single geographic region based on specific frequency bands of satellite data. Therefore, DL models used to map specific natural hazards struggle with their generalization to other types of natural hazards in unseen regions. In this work, we propose a methodology to significantly improve the generalizability of DL natural hazards mappers based on pre-training on a suitable pre-task. Without access to any data from the target domain, we demonstrate this improved generalizability across four U-Net architectures for the segmentation of unseen natural hazards. Importantly, our method is invariant to geographic differences and differences in the type of frequency bands of satellite data. By leveraging characteristics of unlabeled images from the target domain that are publicly available, our approach is able to further improve the generalization behavior without fine-tuning. Thereby, our approach supports the development of foundation models for earth monitoring with the objective of directly segmenting unseen natural hazards across novel geographic regions given different sources of satellite imagery.
A reconfigurable integrated electronic tongue and its use in accelerated analysis of juices and wines
May 27, 2022
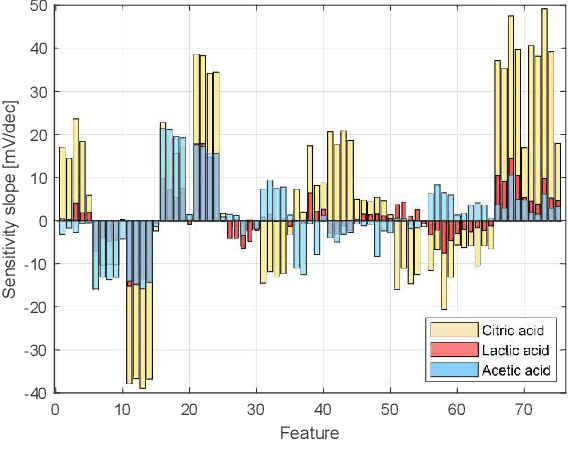
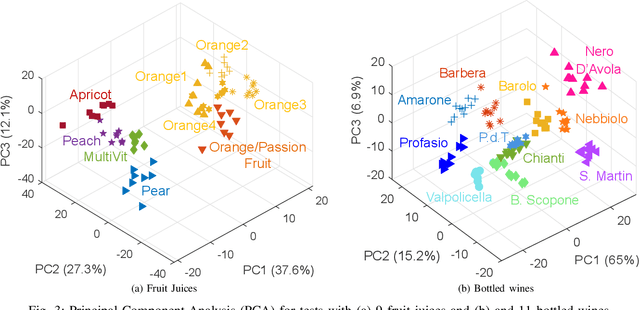
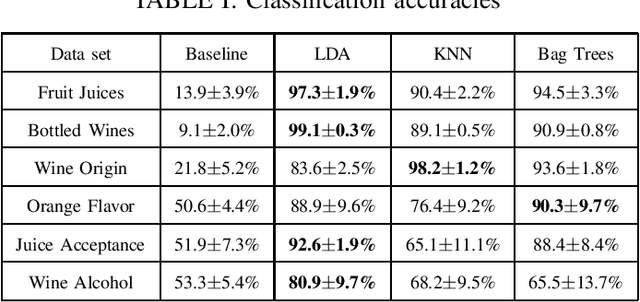
Potentiometric electronic tongues (ETs) leveraging trends in miniaturization and internet of things (IoT) bear promise for facile mobile chemical analysis of complex multicomponent liquids, such as beverages. In this work, hand-crafted feature extraction from the transient potentiometric response of an array of low-selective miniaturized polymeric sensors is combined with a data pipeline for deployment of trained machine learning models on a cloud back-end or edge device. The sensor array demonstrated sensitivity to different organic acids and exhibited interesting performance for the fingerprinting of fruit juices and wines, including differentiation of samples through supervised learning based on sensory descriptors and prediction of consumer acceptability of aged juice samples. Product authentication, quality control and support of sensory evaluation are some of the applications that are expected to benefit from integrated electronic tongues that facilitate the characterization of complex properties of multi-component liquids.
Learning Language and Multimodal Privacy-Preserving Markers of Mood from Mobile Data
Jun 24, 2021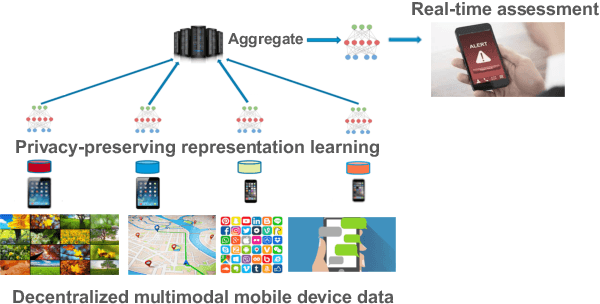
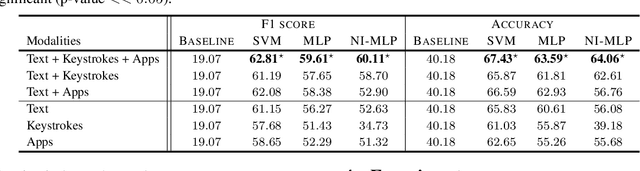
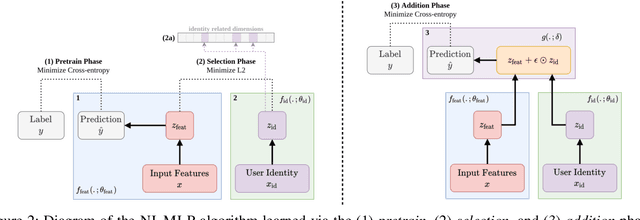
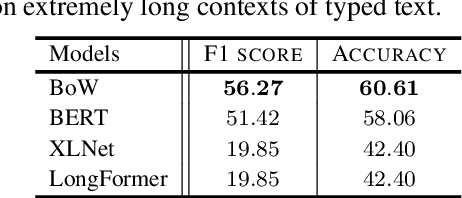
Mental health conditions remain underdiagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications for the early detection, intervention, and treatment of mental health disorders. One promising data source to help monitor human behavior is daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected (e.g., race, gender) attributes. In this paper, we study behavioral markers of daily mood using a recent dataset of mobile behaviors from adolescent populations at high risk of suicidal behaviors. Using computational models, we find that language and multimodal representations of mobile typed text (spanning typed characters, words, keystroke timings, and app usage) are predictive of daily mood. However, we find that models trained to predict mood often also capture private user identities in their intermediate representations. To tackle this problem, we evaluate approaches that obfuscate user identity while remaining predictive. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier.
Multimodal Privacy-preserving Mood Prediction from Mobile Data: A Preliminary Study
Dec 04, 2020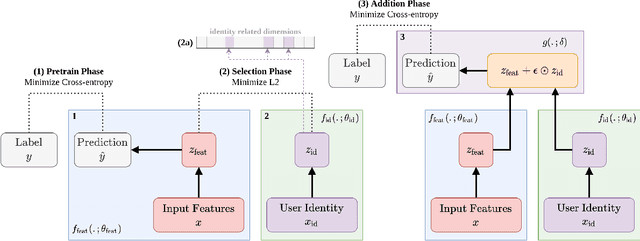
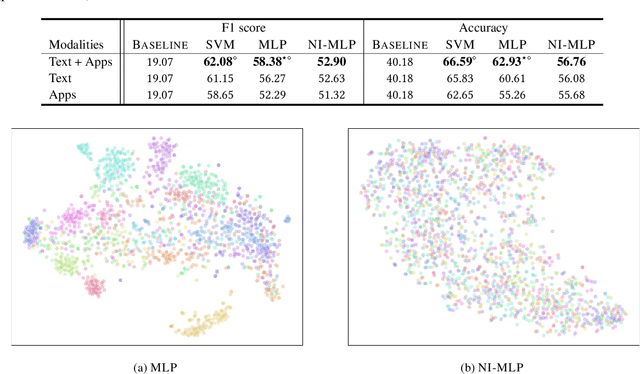
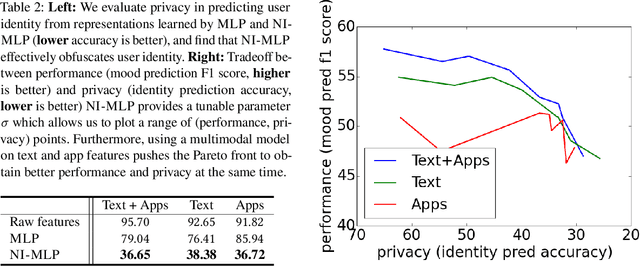
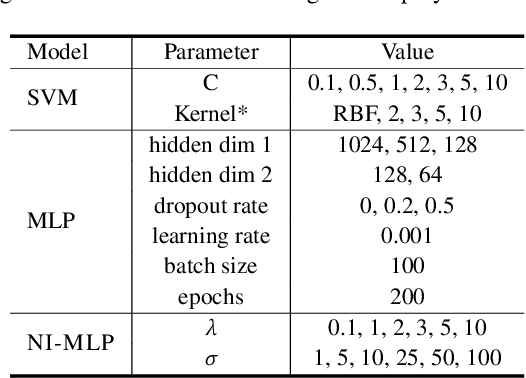
Mental health conditions remain under-diagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications towards the early detection and intervention of mental health disorders. One promising data source to help monitor human behavior is from daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected attributes (e.g., race, gender). In this paper, we study behavioral markers or daily mood using a recent dataset of mobile behaviors from high-risk adolescent populations. Using computational models, we find that multimodal modeling of both text and app usage features is highly predictive of daily mood over each modality alone. Furthermore, we evaluate approaches that reliably obfuscate user identity while remaining predictive of daily mood. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier as compared to unimodal approaches.