 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing One-run Privacy Auditing with Quantile Regression-Based Membership Inference
Jun 18, 2025Differential privacy (DP) auditing aims to provide empirical lower bounds on the privacy guarantees of DP mechanisms like DP-SGD. While some existing techniques require many training runs that are prohibitively costly, recent work introduces one-run auditing approaches that effectively audit DP-SGD in white-box settings while still being computationally efficient. However, in the more practical black-box setting where gradients cannot be manipulated during training and only the last model iterate is observed, prior work shows that there is still a large gap between the empirical lower bounds and theoretical upper bounds. Consequently, in this work, we study how incorporating approaches for stronger membership inference attacks (MIA) can improve one-run auditing in the black-box setting. Evaluating on image classification models trained on CIFAR-10 with DP-SGD, we demonstrate that our proposed approach, which utilizes quantile regression for MIA, achieves tighter bounds while crucially maintaining the computational efficiency of one-run methods.
Breaking the Gold Standard: Extracting Forgotten Data under Exact Unlearning in Large Language Models
May 30, 2025Large language models are typically trained on datasets collected from the web, which may inadvertently contain harmful or sensitive personal information. To address growing privacy concerns, unlearning methods have been proposed to remove the influence of specific data from trained models. Of these, exact unlearning -- which retrains the model from scratch without the target data -- is widely regarded the gold standard, believed to be robust against privacy-related attacks. In this paper, we challenge this assumption by introducing a novel data extraction attack that compromises even exact unlearning. Our method leverages both the pre- and post-unlearning models: by guiding the post-unlearning model using signals from the pre-unlearning model, we uncover patterns that reflect the removed data distribution. Combining model guidance with a token filtering strategy, our attack significantly improves extraction success rates -- doubling performance in some cases -- across common benchmarks such as MUSE, TOFU, and WMDP. Furthermore, we demonstrate our attack's effectiveness on a simulated medical diagnosis dataset to highlight real-world privacy risks associated with exact unlearning. In light of our findings, which suggest that unlearning may, in a contradictory way, increase the risk of privacy leakage, we advocate for evaluation of unlearning methods to consider broader threat models that account not only for post-unlearning models but also for adversarial access to prior checkpoints.
Calibrating LLMs for Text-to-SQL Parsing by Leveraging Sub-clause Frequencies
May 27, 2025While large language models (LLMs) achieve strong performance on text-to-SQL parsing, they sometimes exhibit unexpected failures in which they are confidently incorrect. Building trustworthy text-to-SQL systems thus requires eliciting reliable uncertainty measures from the LLM. In this paper, we study the problem of providing a calibrated confidence score that conveys the likelihood of an output query being correct. Our work is the first to establish a benchmark for post-hoc calibration of LLM-based text-to-SQL parsing. In particular, we show that Platt scaling, a canonical method for calibration, provides substantial improvements over directly using raw model output probabilities as confidence scores. Furthermore, we propose a method for text-to-SQL calibration that leverages the structured nature of SQL queries to provide more granular signals of correctness, named "sub-clause frequency" (SCF) scores. Using multivariate Platt scaling (MPS), our extension of the canonical Platt scaling technique, we combine individual SCF scores into an overall accurate and calibrated score. Empirical evaluation on two popular text-to-SQL datasets shows that our approach of combining MPS and SCF yields further improvements in calibration and the related task of error detection over traditional Platt scaling.
Generate-then-Verify: Reconstructing Data from Limited Published Statistics
Apr 29, 2025
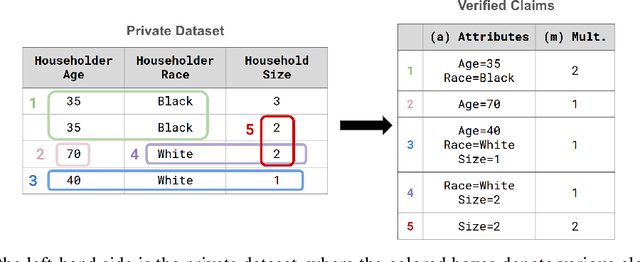
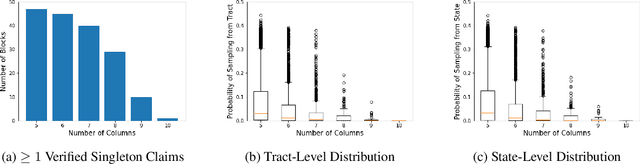
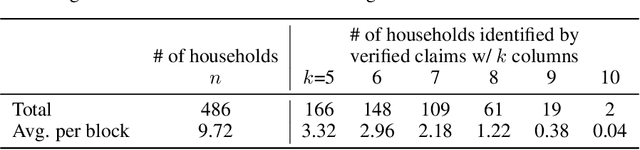
We study the problem of reconstructing tabular data from aggregate statistics, in which the attacker aims to identify interesting claims about the sensitive data that can be verified with 100% certainty given the aggregates. Successful attempts in prior work have conducted studies in settings where the set of published statistics is rich enough that entire datasets can be reconstructed with certainty. In our work, we instead focus on the regime where many possible datasets match the published statistics, making it impossible to reconstruct the entire private dataset perfectly (i.e., when approaches in prior work fail). We propose the problem of partial data reconstruction, in which the goal of the adversary is to instead output a $\textit{subset}$ of rows and/or columns that are $\textit{guaranteed to be correct}$. We introduce a novel integer programming approach that first $\textbf{generates}$ a set of claims and then $\textbf{verifies}$ whether each claim holds for all possible datasets consistent with the published aggregates. We evaluate our approach on the housing-level microdata from the U.S. Decennial Census release, demonstrating that privacy violations can still persist even when information published about such data is relatively sparse.
Winning the MIDST Challenge: New Membership Inference Attacks on Diffusion Models for Tabular Data Synthesis
Mar 15, 2025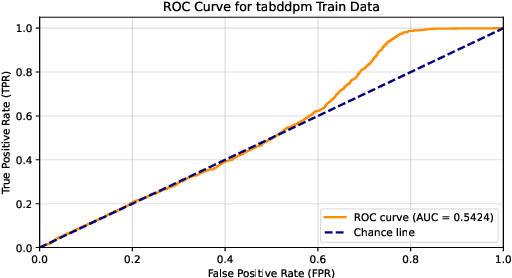

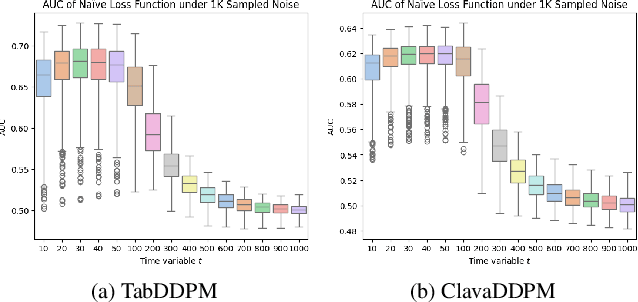
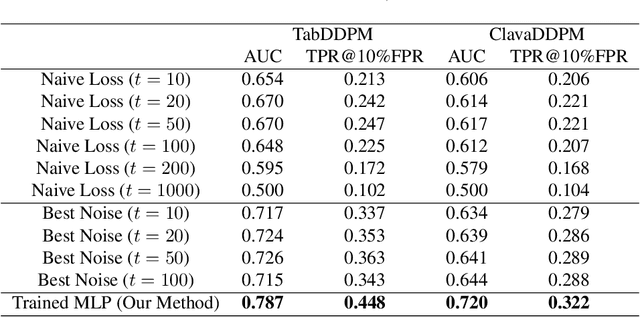
Tabular data synthesis using diffusion models has gained significant attention for its potential to balance data utility and privacy. However, existing privacy evaluations often rely on heuristic metrics or weak membership inference attacks (MIA), leaving privacy risks inadequately assessed. In this work, we conduct a rigorous MIA study on diffusion-based tabular synthesis, revealing that state-of-the-art attacks designed for image models fail in this setting. We identify noise initialization as a key factor influencing attack efficacy and propose a machine-learning-driven approach that leverages loss features across different noises and time steps. Our method, implemented with a lightweight MLP, effectively learns membership signals, eliminating the need for manual optimization. Experimental results from the MIDST Challenge @ SaTML 2025 demonstrate the effectiveness of our approach, securing first place across all tracks. Code is available at https://github.com/Nicholas0228/Tartan_Federer_MIDST.
Multi-group Uncertainty Quantification for Long-form Text Generation
Jul 25, 2024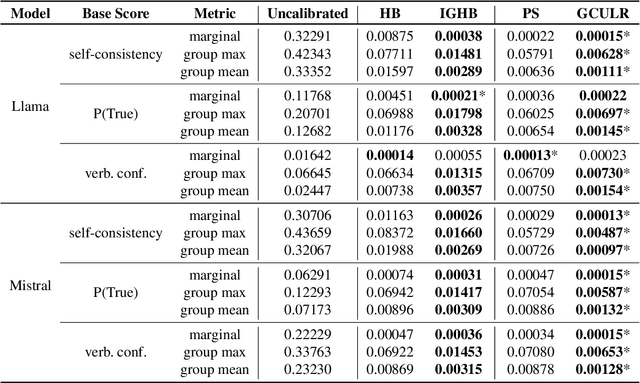
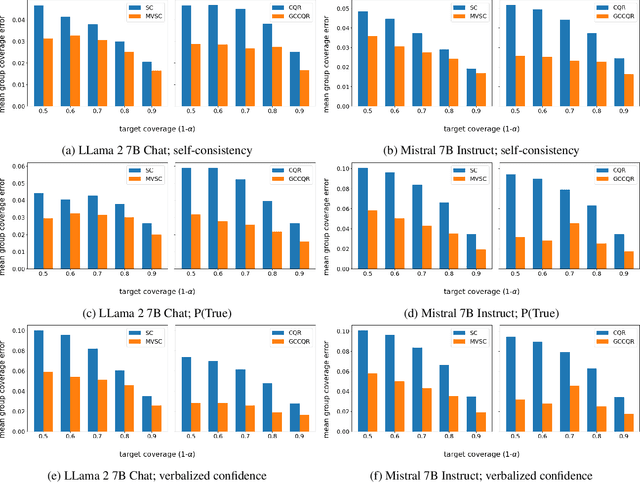
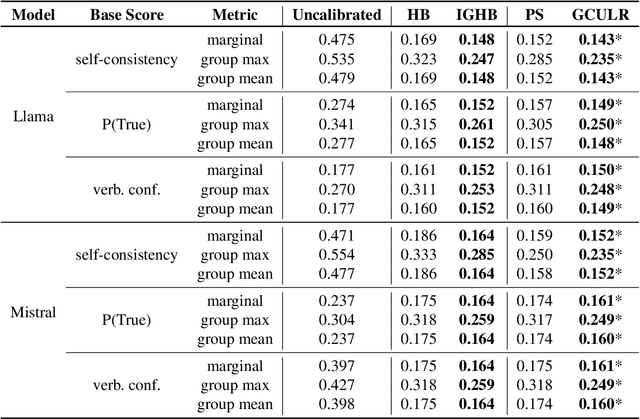
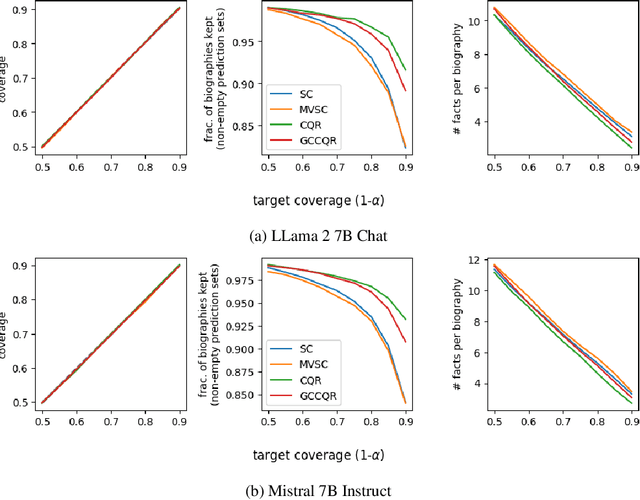
While large language models are rapidly moving towards consumer-facing applications, they are often still prone to factual errors and hallucinations. In order to reduce the potential harms that may come from these errors, it is important for users to know to what extent they can trust an LLM when it makes a factual claim. To this end, we study the problem of uncertainty quantification of factual correctness in long-form natural language generation. Given some output from a large language model, we study both uncertainty at the level of individual claims contained within the output (via calibration) and uncertainty across the entire output itself (via conformal prediction). Moreover, we invoke multicalibration and multivalid conformal prediction to ensure that such uncertainty guarantees are valid both marginally and across distinct groups of prompts. Using the task of biography generation, we demonstrate empirically that having access to and making use of additional group attributes for each prompt improves both overall and group-wise performance. As the problems of calibration, conformal prediction, and their multi-group counterparts have not been extensively explored previously in the context of long-form text generation, we consider these empirical results to form a benchmark for this setting.
Generating Private Synthetic Data with Genetic Algorithms
Jun 05, 2023



We study the problem of efficiently generating differentially private synthetic data that approximate the statistical properties of an underlying sensitive dataset. In recent years, there has been a growing line of work that approaches this problem using first-order optimization techniques. However, such techniques are restricted to optimizing differentiable objectives only, severely limiting the types of analyses that can be conducted. For example, first-order mechanisms have been primarily successful in approximating statistical queries only in the form of marginals for discrete data domains. In some cases, one can circumvent such issues by relaxing the task's objective to maintain differentiability. However, even when possible, these approaches impose a fundamental limitation in which modifications to the minimization problem become additional sources of error. Therefore, we propose Private-GSD, a private genetic algorithm based on zeroth-order optimization heuristics that do not require modifying the original objective. As a result, it avoids the aforementioned limitations of first-order optimization. We empirically evaluate Private-GSD against baseline algorithms on data derived from the American Community Survey across a variety of statistics--otherwise known as statistical queries--both for discrete and real-valued attributes. We show that Private-GSD outperforms the state-of-the-art methods on non-differential queries while matching accuracy in approximating differentiable ones.
Confidence-Ranked Reconstruction of Census Microdata from Published Statistics
Nov 06, 2022A reconstruction attack on a private dataset $D$ takes as input some publicly accessible information about the dataset and produces a list of candidate elements of $D$. We introduce a new class of data reconstruction attacks based on randomized methods for non-convex optimization. We empirically demonstrate that our attacks can not only reconstruct full rows of $D$ from aggregate query statistics $Q(D)\in \mathbb{R}^m$, but can do so in a way that reliably ranks reconstructed rows by their odds of appearing in the private data, providing a signature that could be used for prioritizing reconstructed rows for further actions such as identify theft or hate crime. We also design a sequence of baselines for evaluating reconstruction attacks. Our attacks significantly outperform those that are based only on access to a public distribution or population from which the private dataset $D$ was sampled, demonstrating that they are exploiting information in the aggregate statistics $Q(D)$, and not simply the overall structure of the distribution. In other words, the queries $Q(D)$ are permitting reconstruction of elements of this dataset, not the distribution from which $D$ was drawn. These findings are established both on 2010 U.S. decennial Census data and queries and Census-derived American Community Survey datasets. Taken together, our methods and experiments illustrate the risks in releasing numerically precise aggregate statistics of a large dataset, and provide further motivation for the careful application of provably private techniques such as differential privacy.
Private Synthetic Data with Hierarchical Structure
Jun 13, 2022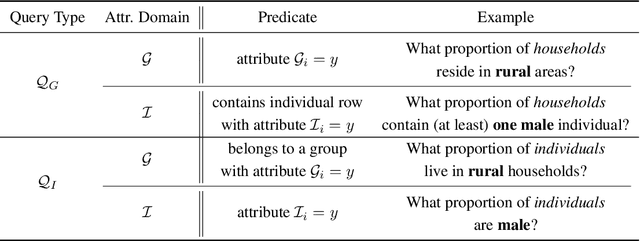
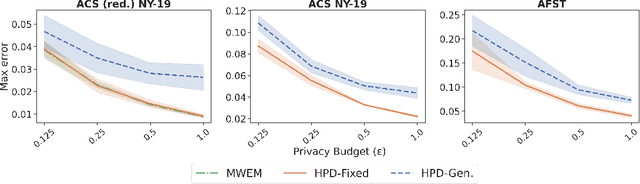

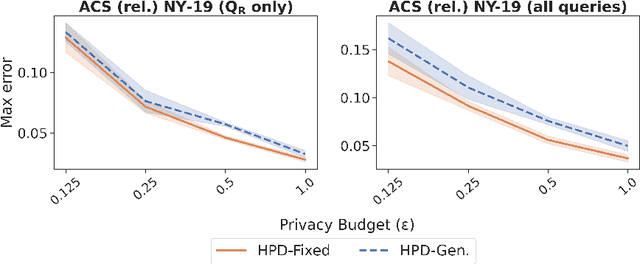
We study the problem of differentially private synthetic data generation for hierarchical datasets in which individual data points are grouped together (e.g., people within households). In particular, to measure the similarity between the synthetic dataset and the underlying private one, we frame our objective under the problem of private query release, generating a synthetic dataset that preserves answers for some collection of queries (i.e., statistics like mean aggregate counts). However, while the application of private synthetic data to the problem of query release has been well studied, such research is restricted to non-hierarchical data domains, raising the initial question -- what queries are important when considering data of this form? Moreover, it has not yet been established how one can generate synthetic data at both the group and individual-level while capturing such statistics. In light of these challenges, we first formalize the problem of hierarchical query release, in which the goal is to release a collection of statistics for some hierarchical dataset. Specifically, we provide a general set of statistical queries that captures relationships between attributes at both the group and individual-level. Subsequently, we introduce private synthetic data algorithms for hierarchical query release and evaluate them on hierarchical datasets derived from the American Community Survey and Allegheny Family Screening Tool data. Finally, we look to the American Community Survey, whose inherent hierarchical structure gives rise to another set of domain-specific queries that we run experiments with.
Learning Language and Multimodal Privacy-Preserving Markers of Mood from Mobile Data
Jun 24, 2021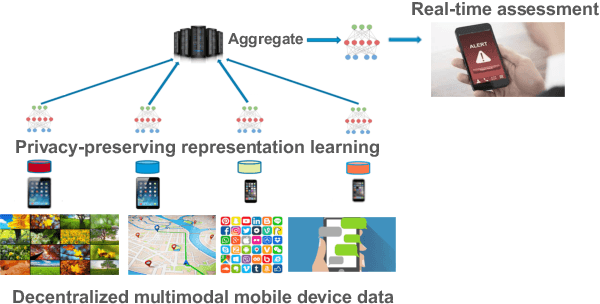
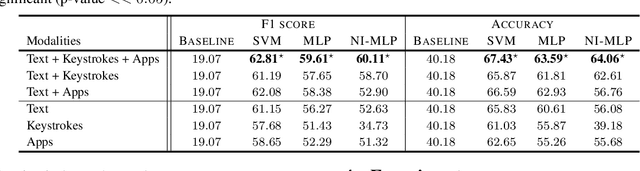
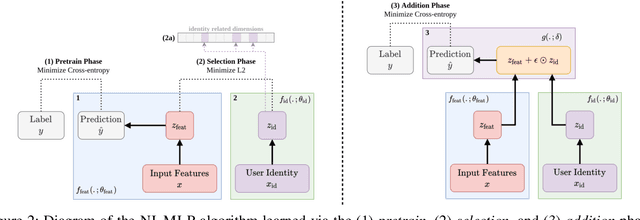
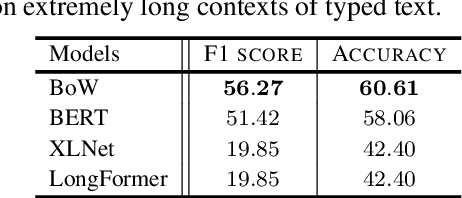
Mental health conditions remain underdiagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications for the early detection, intervention, and treatment of mental health disorders. One promising data source to help monitor human behavior is daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected (e.g., race, gender) attributes. In this paper, we study behavioral markers of daily mood using a recent dataset of mobile behaviors from adolescent populations at high risk of suicidal behaviors. Using computational models, we find that language and multimodal representations of mobile typed text (spanning typed characters, words, keystroke timings, and app usage) are predictive of daily mood. However, we find that models trained to predict mood often also capture private user identities in their intermediate representations. To tackle this problem, we evaluate approaches that obfuscate user identity while remaining predictive. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier.