 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Verification of Distribution Properties
Apr 12, 2026A recent line of work initiated by Chiesa and Gur and further developed by Herman and Rothblum investigates the sample and communication complexity of verifying properties of distributions with the assistance of a powerful, knowledgeable, but untrusted prover. In this work, we initiate the study of differentially private (DP) distribution property testing. After all, if we do not trust the prover to help us with verification, why should we trust it with our sensitive sample? We map a landscape of DP prover-aided proofs of properties of distributions. In the non-private case it is known that one-round (two message) private-coin protocols can have substantially lower complexity than public-coin AM protocols, but in the private case, the possibility for improvement depends on the parameter regime and privacy model. Drawing on connections to replicability and techniques for amplification, we show: (1) There exists a reduction from any one-round $(\varepsilon,δ)$-DP private-coin interactive proof to a one-round public-coin DP interactive proof with the same privacy parameters, for the parameter regime $\varepsilon=O(1/\sqrt{n})$ and $δ=O(1/n^{5/2})$, and with the same sample and communication complexities. (2) If the verifier's message in the private-coin interactive proof is $O(1/\sqrt{\log n})$ locally DP -- a far more relaxed privacy parameter regime in a different model -- then applying one additional transformation again yields a one-round public-coin protocol with the same privacy bound and the same sample and computational complexities. (3) However, when the privacy guarantee is very relaxed ($\varepsilon\inΩ(\log n)$), private coins indeed reduce complexity. We also obtain a Merlin-Arthur (one-message) proof for privately testing whether samples are drawn from a product distribution, and prove that its sample complexity is optimal.
Equitable Evaluation via Elicitation
Feb 24, 2026Individuals with similar qualifications and skills may vary in their demeanor, or outward manner: some tend toward self-promotion while others are modest to the point of omitting crucial information. Comparing the self-descriptions of equally qualified job-seekers with different self-presentation styles is therefore problematic. We build an interactive AI for skill elicitation that provides accurate determination of skills while simultaneously allowing individuals to speak in their own voice. Such a system can be deployed, for example, when a new user joins a professional networking platform, or when matching employees to needs during a company reorganization. To obtain sufficient training data, we train an LLM to act as synthetic humans. Elicitation mitigates endogenous bias arising from individuals' own self-reports. To address systematic model bias we enforce a mathematically rigorous notion of equitability ensuring that the covariance between self-presentation manner and skill evaluation error is small.
Efficient Testing Implies Structured Symmetry
Nov 05, 2025Given a small random sample of $n$-bit strings labeled by an unknown Boolean function, which properties of this function can be tested computationally efficiently? We show an equivalence between properties that are efficiently testable from few samples and properties with structured symmetry, which depend only on the function's average values on parts of a low-complexity partition of the domain. Without the efficiency constraint, a similar characterization in terms of unstructured symmetry was obtained by Blais and Yoshida (2019). Our main technical tool is supersimulation, which builds on methods from the algorithmic fairness literature to approximate arbitrarily complex functions by small-circuit simulators that fool significantly larger distinguishers. We extend the characterization along other axes as well. We show that allowing parts to overlap exponentially reduces their required number, broadening the scope of the construction from properties testable with $O(\log n)$ samples to properties testable with $O(n)$ samples. For larger sample sizes, we show that any efficient tester is essentially checking for indistinguishability from a bounded collection of small circuits, in the spirit of a characterization of testable graph properties. Finally, we show that our results for Boolean function testing generalize to high-entropy distribution testing on arbitrary domains.
From Fairness to Infinity: Outcome-Indistinguishable (Omni)Prediction in Evolving Graphs
Nov 26, 2024
Professional networks provide invaluable entree to opportunity through referrals and introductions. A rich literature shows they also serve to entrench and even exacerbate a status quo of privilege and disadvantage. Hiring platforms, equipped with the ability to nudge link formation, provide a tantalizing opening for beneficial structural change. We anticipate that key to this prospect will be the ability to estimate the likelihood of edge formation in an evolving graph. Outcome-indistinguishable prediction algorithms ensure that the modeled world is indistinguishable from the real world by a family of statistical tests. Omnipredictors ensure that predictions can be post-processed to yield loss minimization competitive with respect to a benchmark class of predictors for many losses simultaneously, with appropriate post-processing. We begin by observing that, by combining a slightly modified form of the online K29 star algorithm of Vovk (2007) with basic facts from the theory of reproducing kernel Hilbert spaces, one can derive simple and efficient online algorithms satisfying outcome indistinguishability and omniprediction, with guarantees that improve upon, or are complementary to, those currently known. This is of independent interest. We apply these techniques to evolving graphs, obtaining online outcome-indistinguishable omnipredictors for rich -- possibly infinite -- sets of distinguishers that capture properties of pairs of nodes, and their neighborhoods. This yields, inter alia, multicalibrated predictions of edge formation with respect to pairs of demographic groups, and the ability to simultaneously optimize loss as measured by a variety of social welfare functions.
Differentially Private Learning Beyond the Classical Dimensionality Regime
Nov 20, 2024We initiate the study of differentially private learning in the proportional dimensionality regime, in which the number of data samples $n$ and problem dimension $d$ approach infinity at rates proportional to one another, meaning that $d / n \to \delta$ as $n \to \infty$ for an arbitrary, given constant $\delta \in (0, \infty)$. This setting is significantly more challenging than that of all prior theoretical work in high-dimensional differentially private learning, which, despite the name, has assumed that $\delta = 0$ or is sufficiently small for problems of sample complexity $O(d)$, a regime typically considered "low-dimensional" or "classical" by modern standards in high-dimensional statistics. We provide sharp theoretical estimates of the error of several well-studied differentially private algorithms for robust linear regression and logistic regression, including output perturbation, objective perturbation, and noisy stochastic gradient descent, in the proportional dimensionality regime. The $1 + o(1)$ factor precision of our error estimates enables a far more nuanced understanding of the price of privacy of these algorithms than that afforded by existing, coarser analyses, which are essentially vacuous in the regime we consider. We incorporate several probabilistic tools that have not previously been used to analyze differentially private learning algorithms, such as a modern Gaussian comparison inequality and recent universality laws with origins in statistical physics.
Set-Based Prompting: Provably Solving the Language Model Order Dependency Problem
Jun 12, 2024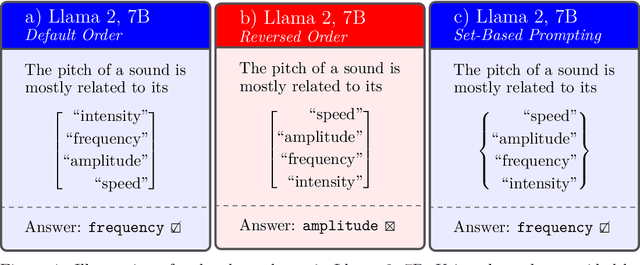


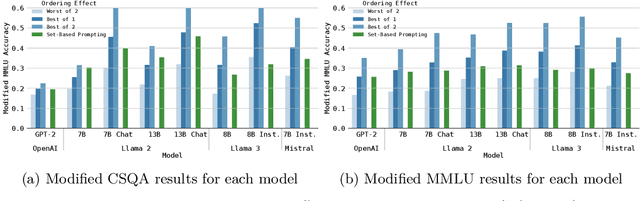
The development of generative language models that can create long and coherent textual outputs via autoregression has lead to a proliferation of uses and a corresponding sweep of analyses as researches work to determine the limitations of this new paradigm. Unlike humans, these 'Large Language Models' (LLMs) are highly sensitive to small changes in their inputs, leading to unwanted inconsistency in their behavior. One problematic inconsistency when LLMs are used to answer multiple-choice questions or analyze multiple inputs is order dependency: the output of an LLM can (and often does) change significantly when sub-sequences are swapped, despite both orderings being semantically identical. In this paper we present Set-Based Prompting, a technique that guarantees the output of an LLM will not have order dependence on a specified set of sub-sequences. We show that this method provably eliminates order dependency, and that it can be applied to any transformer-based LLM to enable text generation that is unaffected by re-orderings. Delving into the implications of our method, we show that, despite our inputs being out of distribution, the impact on expected accuracy is small, where the expectation is over the order of uniformly chosen shuffling of the candidate responses, and usually significantly less in practice. Thus, Set-Based Prompting can be used as a 'dropped-in' method on fully trained models. Finally, we discuss how our method's success suggests that other strong guarantees can be obtained on LLM performance via modifying the input representations.
HappyMap: A Generalized Multi-calibration Method
Mar 08, 2023Multi-calibration is a powerful and evolving concept originating in the field of algorithmic fairness. For a predictor $f$ that estimates the outcome $y$ given covariates $x$, and for a function class $\mathcal{C}$, multi-calibration requires that the predictor $f(x)$ and outcome $y$ are indistinguishable under the class of auditors in $\mathcal{C}$. Fairness is captured by incorporating demographic subgroups into the class of functions~$\mathcal{C}$. Recent work has shown that, by enriching the class $\mathcal{C}$ to incorporate appropriate propensity re-weighting functions, multi-calibration also yields target-independent learning, wherein a model trained on a source domain performs well on unseen, future, target domains(approximately) captured by the re-weightings. Formally, multi-calibration with respect to $\mathcal{C}$ bounds $\big|\mathbb{E}_{(x,y)\sim \mathcal{D}}[c(f(x),x)\cdot(f(x)-y)]\big|$ for all $c \in \mathcal{C}$. In this work, we view the term $(f(x)-y)$ as just one specific mapping, and explore the power of an enriched class of mappings. We propose \textit{HappyMap}, a generalization of multi-calibration, which yields a wide range of new applications, including a new fairness notion for uncertainty quantification (conformal prediction), a novel technique for conformal prediction under covariate shift, and a different approach to analyzing missing data, while also yielding a unified understanding of several existing seemingly disparate algorithmic fairness notions and target-independent learning approaches. We give a single \textit{HappyMap} meta-algorithm that captures all these results, together with a sufficiency condition for its success.
New Insights into Multi-Calibration
Jan 21, 2023


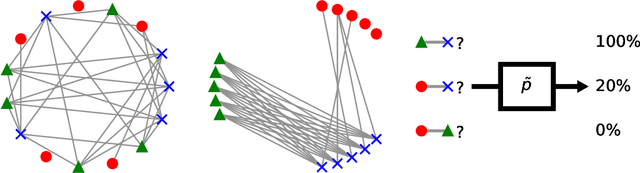
We identify a novel connection between the recent literature on multi-group fairness for prediction algorithms and well-established notions of graph regularity from extremal graph theory. We frame our investigation using new, statistical distance-based variants of multi-calibration that are closely related to the concept of outcome indistinguishability. Adopting this perspective leads us naturally not only to our graph theoretic results, but also to new multi-calibration algorithms with improved complexity in certain parameter regimes, and to a generalization of a state-of-the-art result on omniprediction. Along the way, we also unify several prior algorithms for achieving multi-group fairness, as well as their analyses, through the lens of no-regret learning.
Confidence-Ranked Reconstruction of Census Microdata from Published Statistics
Nov 06, 2022A reconstruction attack on a private dataset $D$ takes as input some publicly accessible information about the dataset and produces a list of candidate elements of $D$. We introduce a new class of data reconstruction attacks based on randomized methods for non-convex optimization. We empirically demonstrate that our attacks can not only reconstruct full rows of $D$ from aggregate query statistics $Q(D)\in \mathbb{R}^m$, but can do so in a way that reliably ranks reconstructed rows by their odds of appearing in the private data, providing a signature that could be used for prioritizing reconstructed rows for further actions such as identify theft or hate crime. We also design a sequence of baselines for evaluating reconstruction attacks. Our attacks significantly outperform those that are based only on access to a public distribution or population from which the private dataset $D$ was sampled, demonstrating that they are exploiting information in the aggregate statistics $Q(D)$, and not simply the overall structure of the distribution. In other words, the queries $Q(D)$ are permitting reconstruction of elements of this dataset, not the distribution from which $D$ was drawn. These findings are established both on 2010 U.S. decennial Census data and queries and Census-derived American Community Survey datasets. Taken together, our methods and experiments illustrate the risks in releasing numerically precise aggregate statistics of a large dataset, and provide further motivation for the careful application of provably private techniques such as differential privacy.
Improved Generalization Guarantees in Restricted Data Models
Jul 20, 2022Differential privacy is known to protect against threats to validity incurred due to adaptive, or exploratory, data analysis -- even when the analyst adversarially searches for a statistical estimate that diverges from the true value of the quantity of interest on the underlying population. The cost of this protection is the accuracy loss incurred by differential privacy. In this work, inspired by standard models in the genomics literature, we consider data models in which individuals are represented by a sequence of attributes with the property that where distant attributes are only weakly correlated. We show that, under this assumption, it is possible to "re-use" privacy budget on different portions of the data, significantly improving accuracy without increasing the risk of overfitting.
* 13 pages, published in FORC 2022