 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShifting Work Patterns with Generative AI
Apr 15, 2025



We present evidence on how generative AI changes the work patterns of knowledge workers using data from a 6-month-long, cross-industry, randomized field experiment. Half of the 6,000 workers in the study received access to a generative AI tool integrated into the applications they already used for emails, document creation, and meetings. We find that access to the AI tool during the first year of its release primarily impacted behaviors that could be changed independently and not behaviors that required coordination to change: workers who used the tool spent 3 fewer hours, or 25% less time on email each week (intent to treat estimate is 1.4 hours) and seemed to complete documents moderately faster, but did not significantly change time spent in meetings.
Flattening Supply Chains: When do Technology Improvements lead to Disintermediation?
Feb 28, 2025In the digital economy, technological innovations make it cheaper to produce high-quality content. For example, generative AI tools reduce costs for creators who develop content to be distributed online, but can also reduce production costs for the users who consume that content. These innovations can thus lead to disintermediation, since consumers may choose to use these technologies directly, bypassing intermediaries. To investigate when technological improvements lead to disintermediation, we study a game with an intermediary, suppliers of a production technology, and consumers. First, we show disintermediation occurs whenever production costs are too high or too low. We then investigate the consequences of disintermediation for welfare and content quality at equilibrium. While the intermediary is welfare-improving, the intermediary extracts all gains to social welfare and its presence can raise or lower content quality. We further analyze how disintermediation is affected by the level of competition between suppliers and the intermediary's fee structure. More broadly, our results take a step towards assessing how production technology innovations affect the survival of intermediaries and impact the digital economy.
From Fairness to Infinity: Outcome-Indistinguishable (Omni)Prediction in Evolving Graphs
Nov 26, 2024
Professional networks provide invaluable entree to opportunity through referrals and introductions. A rich literature shows they also serve to entrench and even exacerbate a status quo of privilege and disadvantage. Hiring platforms, equipped with the ability to nudge link formation, provide a tantalizing opening for beneficial structural change. We anticipate that key to this prospect will be the ability to estimate the likelihood of edge formation in an evolving graph. Outcome-indistinguishable prediction algorithms ensure that the modeled world is indistinguishable from the real world by a family of statistical tests. Omnipredictors ensure that predictions can be post-processed to yield loss minimization competitive with respect to a benchmark class of predictors for many losses simultaneously, with appropriate post-processing. We begin by observing that, by combining a slightly modified form of the online K29 star algorithm of Vovk (2007) with basic facts from the theory of reproducing kernel Hilbert spaces, one can derive simple and efficient online algorithms satisfying outcome indistinguishability and omniprediction, with guarantees that improve upon, or are complementary to, those currently known. This is of independent interest. We apply these techniques to evolving graphs, obtaining online outcome-indistinguishable omnipredictors for rich -- possibly infinite -- sets of distinguishers that capture properties of pairs of nodes, and their neighborhoods. This yields, inter alia, multicalibrated predictions of edge formation with respect to pairs of demographic groups, and the ability to simultaneously optimize loss as measured by a variety of social welfare functions.
Online Algorithms with Limited Data Retention
Apr 17, 2024We introduce a model of online algorithms subject to strict constraints on data retention. An online learning algorithm encounters a stream of data points, one per round, generated by some stationary process. Crucially, each data point can request that it be removed from memory $m$ rounds after it arrives. To model the impact of removal, we do not allow the algorithm to store any information or calculations between rounds other than a subset of the data points (subject to the retention constraints). At the conclusion of the stream, the algorithm answers a statistical query about the full dataset. We ask: what level of performance can be guaranteed as a function of $m$? We illustrate this framework for multidimensional mean estimation and linear regression problems. We show it is possible to obtain an exponential improvement over a baseline algorithm that retains all data as long as possible. Specifically, we show that $m = \textsc{Poly}(d, \log(1/\epsilon))$ retention suffices to achieve mean squared error $\epsilon$ after observing $O(1/\epsilon)$ $d$-dimensional data points. This matches the error bound of the optimal, yet infeasible, algorithm that retains all data forever. We also show a nearly matching lower bound on the retention required to guarantee error $\epsilon$. One implication of our results is that data retention laws are insufficient to guarantee the right to be forgotten even in a non-adversarial world in which firms merely strive to (approximately) optimize the performance of their algorithms. Our approach makes use of recent developments in the multidimensional random subset sum problem to simulate the progression of stochastic gradient descent under a model of adversarial noise, which may be of independent interest.
Impact of Decentralized Learning on Player Utilities in Stackelberg Games
Feb 29, 2024
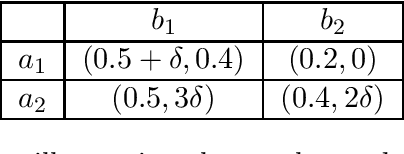


When deployed in the world, a learning agent such as a recommender system or a chatbot often repeatedly interacts with another learning agent (such as a user) over time. In many such two-agent systems, each agent learns separately and the rewards of the two agents are not perfectly aligned. To better understand such cases, we examine the learning dynamics of the two-agent system and the implications for each agent's objective. We model these systems as Stackelberg games with decentralized learning and show that standard regret benchmarks (such as Stackelberg equilibrium payoffs) result in worst-case linear regret for at least one player. To better capture these systems, we construct a relaxed regret benchmark that is tolerant to small learning errors by agents. We show that standard learning algorithms fail to provide sublinear regret, and we develop algorithms to achieve near-optimal $O(T^{2/3})$ regret for both players with respect to these benchmarks. We further design relaxed environments under which faster learning ($O(\sqrt{T})$) is possible. Altogether, our results take a step towards assessing how two-agent interactions in sequential and decentralized learning environments affect the utility of both agents.
Clickbait vs. Quality: How Engagement-Based Optimization Shapes the Content Landscape in Online Platforms
Jan 18, 2024



Online content platforms commonly use engagement-based optimization when making recommendations. This encourages content creators to invest in quality, but also rewards gaming tricks such as clickbait. To understand the total impact on the content landscape, we study a game between content creators competing on the basis of engagement metrics and analyze the equilibrium decisions about investment in quality and gaming. First, we show the content created at equilibrium exhibits a positive correlation between quality and gaming, and we empirically validate this finding on a Twitter dataset. Using the equilibrium structure of the content landscape, we then examine the downstream performance of engagement-based optimization along several axes. Perhaps counterintuitively, the average quality of content consumed by users can decrease at equilibrium as gaming tricks become more costly for content creators to employ. Moreover, engagement-based optimization can perform worse in terms of user utility than a baseline with random recommendations, and engagement-based optimization is also suboptimal in terms of realized engagement relative to quality-based optimization. Altogether, our results highlight the need to consider content creator incentives when evaluating a platform's choice of optimization metric.
Algorithmic Persuasion Through Simulation: Information Design in the Age of Generative AI
Nov 29, 2023



How can an informed sender persuade a receiver, having only limited information about the receiver's beliefs? Motivated by research showing generative AI can simulate economic agents, we initiate the study of information design with an oracle. We assume the sender can learn more about the receiver by querying this oracle, e.g., by simulating the receiver's behavior. Aside from AI motivations such as general-purpose Large Language Models (LLMs) and problem-specific machine learning models, alternate motivations include customer surveys and querying a small pool of live users. Specifically, we study Bayesian Persuasion where the sender has a second-order prior over the receiver's beliefs. After a fixed number of queries to an oracle to refine this prior, the sender commits to an information structure. Upon receiving the message, the receiver takes a payoff-relevant action maximizing her expected utility given her posterior beliefs. We design polynomial-time querying algorithms that optimize the sender's expected utility in this Bayesian Persuasion game. As a technical contribution, we show that queries form partitions of the space of receiver beliefs that can be used to quantify the sender's knowledge.
Maximizing Welfare with Incentive-Aware Evaluation Mechanisms
Nov 03, 2020
Motivated by applications such as college admission and insurance rate determination, we propose an evaluation problem where the inputs are controlled by strategic individuals who can modify their features at a cost. A learner can only partially observe the features, and aims to classify individuals with respect to a quality score. The goal is to design an evaluation mechanism that maximizes the overall quality score, i.e., welfare, in the population, taking any strategic updating into account. We further study the algorithmic aspect of finding the welfare maximizing evaluation mechanism under two specific settings in our model. When scores are linear and mechanisms use linear scoring rules on the observable features, we show that the optimal evaluation mechanism is an appropriate projection of the quality score. When mechanisms must use linear thresholds, we design a polynomial time algorithm with a (1/4)-approximation guarantee when the underlying feature distribution is sufficiently smooth and admits an oracle for finding dense regions. We extend our results to settings where the prior distribution is unknown and must be learned from samples.
Bayesian Exploration with Heterogeneous Agents
Feb 19, 2019
It is common in recommendation systems that users both consume and produce information as they make strategic choices under uncertainty. While a social planner would balance "exploration" and "exploitation" using a multi-armed bandit algorithm, users' incentives may tilt this balance in favor of exploitation. We consider Bayesian Exploration: a simple model in which the recommendation system (the "principal") controls the information flow to the users (the "agents") and strives to incentivize exploration via information asymmetry. A single round of this model is a version of a well-known "Bayesian Persuasion game" from [Kamenica and Gentzkow]. We allow heterogeneous users, relaxing a major assumption from prior work that users have the same preferences from one time step to another. The goal is now to learn the best personalized recommendations. One particular challenge is that it may be impossible to incentivize some of the user types to take some of the actions, no matter what the principal does or how much time she has. We consider several versions of the model, depending on whether and when the user types are reported to the principal, and design a near-optimal "recommendation policy" for each version. We also investigate how the model choice and the diversity of user types impact the set of actions that can possibly be "explored" by each type.
Adversarial Bandits with Knapsacks
Nov 28, 2018
We consider Bandits with Knapsacks (henceforth, BwK), a general model for multi-armed bandits under supply/budget constraints. In particular, a bandit algorithm needs to solve a well-known knapsack problem: find an optimal packing of items into a limited-size knapsack. The BwK problem is a common generalization of numerous motivating examples, which range from dynamic pricing to repeated auctions to dynamic ad allocation to network routing and scheduling. While the prior work on BwK focused on the stochastic version, we pioneer the other extreme in which the outcomes can be chosen adversarially. This is a considerably harder problem, compared to both the stochastic version and the "classic" adversarial bandits, in that regret minimization is no longer feasible. Instead, the objective is to minimize the competitive ratio: the ratio of the benchmark reward to the algorithm's reward. We design an algorithm with competitive ratio O(log T) relative to the best fixed distribution over actions, where T is the time horizon; we also prove a matching lower bound. The key conceptual contribution is a new perspective on the stochastic version of the problem. We suggest a new algorithm for the stochastic version, which builds on the framework of regret minimization in repeated games and admits a substantially simpler analysis compared to prior work. We then analyze this algorithm for the adversarial version and use it as a subroutine to solve the latter.