 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Algorithm for Structured Bandits: A Sharp Characterization of Asymptotic Success / Failure
Mar 06, 2025We study the greedy (exploitation-only) algorithm in bandit problems with a known reward structure. We allow arbitrary finite reward structures, while prior work focused on a few specific ones. We fully characterize when the greedy algorithm asymptotically succeeds or fails, in the sense of sublinear vs. linear regret as a function of time. Our characterization identifies a partial identifiability property of the problem instance as the necessary and sufficient condition for the asymptotic success. Notably, once this property holds, the problem becomes easy -- any algorithm will succeed (in the same sense as above), provided it satisfies a mild non-degeneracy condition. We further extend our characterization to contextual bandits and interactive decision-making with arbitrary feedback, and demonstrate its broad applicability across various examples.
Exploration and Persuasion
Oct 22, 2024How to incentivize self-interested agents to explore when they prefer to exploit? Consider a population of self-interested agents that make decisions under uncertainty. They "explore" to acquire new information and "exploit" this information to make good decisions. Collectively they need to balance these two objectives, but their incentives are skewed toward exploitation. This is because exploration is costly, but its benefits are spread over many agents in the future. "Incentivized Exploration" addresses this issue via strategic communication. Consider a benign ``principal" which can communicate with the agents and make recommendations, but cannot force the agents to comply. Moreover, suppose the principal can observe the agents' decisions and the outcomes of these decisions. The goal is to design a communication and recommendation policy which (i) achieves a desirable balance between exploration and exploitation, and (ii) incentivizes the agents to follow recommendations. What makes it feasible is "information asymmetry": the principal knows more than any one agent, as it collects information from many. It is essential that the principal does not fully reveal all its knowledge to the agents. Incentivized exploration combines two important problems in, resp., machine learning and theoretical economics. First, if agents always follow recommendations, the principal faces a multi-armed bandit problem: essentially, design an algorithm that balances exploration and exploitation. Second, interaction with a single agent corresponds to "Bayesian persuasion", where a principal leverages information asymmetry to convince an agent to take a particular action. We provide a brief but self-contained introduction to each problem through the lens of incentivized exploration, solving a key special case of the former as a sub-problem of the latter.
* This is a chapter published in "Online and Matching-Based Markets", Cambridge University Press, 2023. It has been available from the author's website since 2021
Can large language models explore in-context?
Mar 22, 2024



We investigate the extent to which contemporary Large Language Models (LLMs) can engage in exploration, a core capability in reinforcement learning and decision making. We focus on native performance of existing LLMs, without training interventions. We deploy LLMs as agents in simple multi-armed bandit environments, specifying the environment description and interaction history entirely in-context, i.e., within the LLM prompt. We experiment with GPT-3.5, GPT-4, and Llama2, using a variety of prompt designs, and find that the models do not robustly engage in exploration without substantial interventions: i) Across all of our experiments, only one configuration resulted in satisfactory exploratory behavior: GPT-4 with chain-of-thought reasoning and an externally summarized interaction history, presented as sufficient statistics; ii) All other configurations did not result in robust exploratory behavior, including those with chain-of-thought reasoning but unsummarized history. Although these findings can be interpreted positively, they suggest that external summarization -- which may not be possible in more complex settings -- is important for obtaining desirable behavior from LLM agents. We conclude that non-trivial algorithmic interventions, such as fine-tuning or dataset curation, may be required to empower LLM-based decision making agents in complex settings.
Impact of Decentralized Learning on Player Utilities in Stackelberg Games
Feb 29, 2024
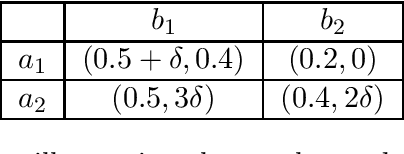


When deployed in the world, a learning agent such as a recommender system or a chatbot often repeatedly interacts with another learning agent (such as a user) over time. In many such two-agent systems, each agent learns separately and the rewards of the two agents are not perfectly aligned. To better understand such cases, we examine the learning dynamics of the two-agent system and the implications for each agent's objective. We model these systems as Stackelberg games with decentralized learning and show that standard regret benchmarks (such as Stackelberg equilibrium payoffs) result in worst-case linear regret for at least one player. To better capture these systems, we construct a relaxed regret benchmark that is tolerant to small learning errors by agents. We show that standard learning algorithms fail to provide sublinear regret, and we develop algorithms to achieve near-optimal $O(T^{2/3})$ regret for both players with respect to these benchmarks. We further design relaxed environments under which faster learning ($O(\sqrt{T})$) is possible. Altogether, our results take a step towards assessing how two-agent interactions in sequential and decentralized learning environments affect the utility of both agents.
Incentivized Exploration via Filtered Posterior Sampling
Feb 20, 2024We study "incentivized exploration" (IE) in social learning problems where the principal (a recommendation algorithm) can leverage information asymmetry to incentivize sequentially-arriving agents to take exploratory actions. We identify posterior sampling, an algorithmic approach that is well known in the multi-armed bandits literature, as a general-purpose solution for IE. In particular, we expand the existing scope of IE in several practically-relevant dimensions, from private agent types to informative recommendations to correlated Bayesian priors. We obtain a general analysis of posterior sampling in IE which allows us to subsume these extended settings as corollaries, while also recovering existing results as special cases.
Robust and Performance Incentivizing Algorithms for Multi-Armed Bandits with Strategic Agents
Dec 13, 2023
We consider a variant of the stochastic multi-armed bandit problem. Specifically, the arms are strategic agents who can improve their rewards or absorb them. The utility of an agent increases if she is pulled more or absorbs more of her rewards but decreases if she spends more effort improving her rewards. Agents have heterogeneous properties, specifically having different means and able to improve their rewards up to different levels. Further, a non-empty subset of agents are ''honest'' and in the worst case always give their rewards without absorbing any part. The principal wishes to obtain a high revenue (cumulative reward) by designing a mechanism that incentives top level performance at equilibrium. At the same time, the principal wishes to be robust and obtain revenue at least at the level of the honest agent with the highest mean in case of non-equilibrium behaviour. We identify a class of MAB algorithms which we call performance incentivizing which satisfy a collection of properties and show that they lead to mechanisms that incentivize top level performance at equilibrium and are robust under any strategy profile. Interestingly, we show that UCB is an example of such a MAB algorithm. Further, in the case where the top performance level is unknown we show that combining second price auction ideas with performance incentivizing algorithms achieves performance at least at the second top level while also being robust.
Algorithmic Persuasion Through Simulation: Information Design in the Age of Generative AI
Nov 29, 2023



How can an informed sender persuade a receiver, having only limited information about the receiver's beliefs? Motivated by research showing generative AI can simulate economic agents, we initiate the study of information design with an oracle. We assume the sender can learn more about the receiver by querying this oracle, e.g., by simulating the receiver's behavior. Aside from AI motivations such as general-purpose Large Language Models (LLMs) and problem-specific machine learning models, alternate motivations include customer surveys and querying a small pool of live users. Specifically, we study Bayesian Persuasion where the sender has a second-order prior over the receiver's beliefs. After a fixed number of queries to an oracle to refine this prior, the sender commits to an information structure. Upon receiving the message, the receiver takes a payoff-relevant action maximizing her expected utility given her posterior beliefs. We design polynomial-time querying algorithms that optimize the sender's expected utility in this Bayesian Persuasion game. As a technical contribution, we show that queries form partitions of the space of receiver beliefs that can be used to quantify the sender's knowledge.
Oracle-Efficient Pessimism: Offline Policy Optimization in Contextual Bandits
Jun 13, 2023



We consider policy optimization in contextual bandits, where one is given a fixed dataset of logged interactions. While pessimistic regularizers are typically used to mitigate distribution shift, prior implementations thereof are not computationally efficient. We present the first oracle-efficient algorithm for pessimistic policy optimization: it reduces to supervised learning, leading to broad applicability. We also obtain best-effort statistical guarantees analogous to those for pessimistic approaches in prior work. We instantiate our approach for both discrete and continuous actions. We perform extensive experiments in both settings, showing advantage over unregularized policy optimization across a wide range of configurations.
Bandit Social Learning: Exploration under Myopic Behavior
Feb 15, 2023We study social learning dynamics where the agents collectively follow a simple multi-armed bandit protocol. Agents arrive sequentially, choose arms and receive associated rewards. Each agent observes the full history (arms and rewards) of the previous agents, and there are no private signals. While collectively the agents face exploration-exploitation tradeoff, each agent acts myopically, without regards to exploration. Motivating scenarios concern reviews and ratings on online platforms. We allow a wide range of myopic behaviors that are consistent with (parameterized) confidence intervals, including the "unbiased" behavior as well as various behaviorial biases. While extreme versions of these behaviors correspond to well-known bandit algorithms, we prove that more moderate versions lead to stark exploration failures, and consequently to regret rates that are linear in the number of agents. We provide matching upper bounds on regret by analyzing "moderately optimistic" agents. As a special case of independent interest, we obtain a general result on failure of the greedy algorithm in multi-armed bandits. This is the first such result in the literature, to the best of our knowledge
Autobidders with Budget and ROI Constraints: Efficiency, Regret, and Pacing Dynamics
Jan 30, 2023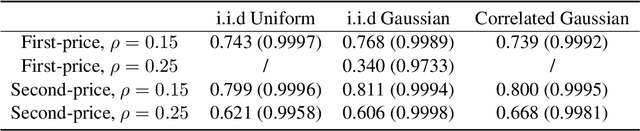
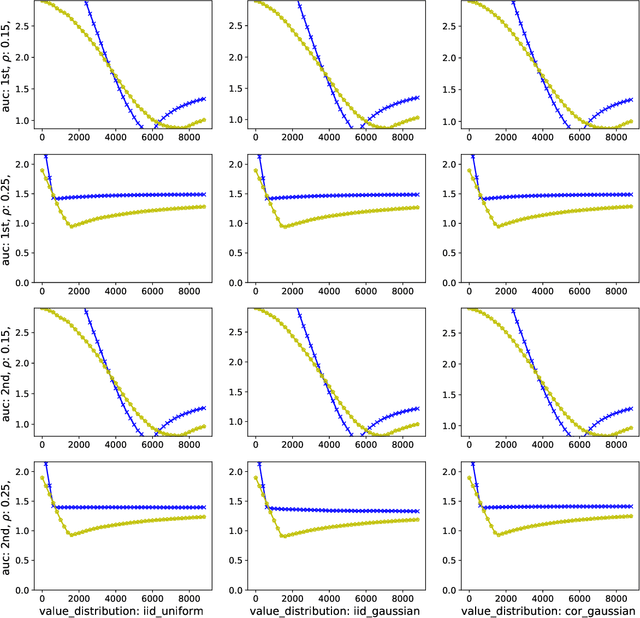
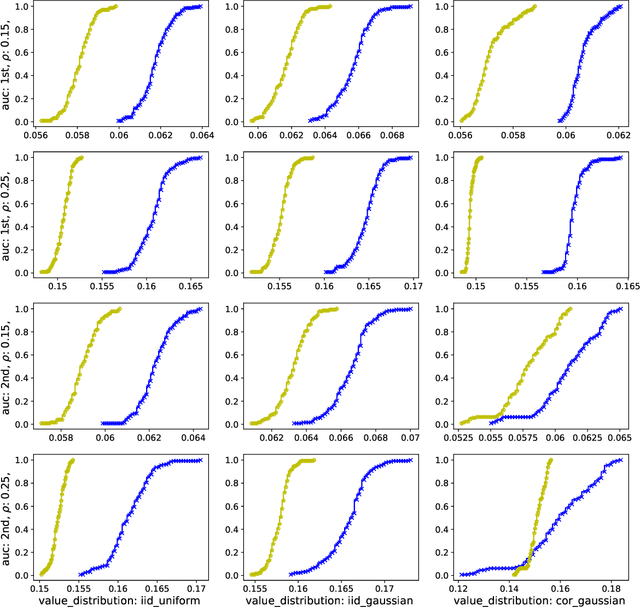
We study a game between autobidding algorithms that compete in an online advertising platform. Each autobidder is tasked with maximizing its advertiser's total value over multiple rounds of a repeated auction, subject to budget and/or return-on-investment constraints. We propose a gradient-based learning algorithm that is guaranteed to satisfy all constraints and achieves vanishing individual regret. Our algorithm uses only bandit feedback and can be used with the first- or second-price auction, as well as with any "intermediate" auction format. Our main result is that when these autobidders play against each other, the resulting expected liquid welfare over all rounds is at least half of the expected optimal liquid welfare achieved by any allocation. This holds whether or not the bidding dynamics converges to an equilibrium and regardless of the correlation structure between advertiser valuations.