 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision Tree Learning on Product Spaces
May 13, 2026Decision tree learning has long been a central topic in theoretical computer science, driven by its practical importance. A fundamental and widely used method for decision tree construction is the top-down greedy heuristic, which recursively splits on the most influential variable. Despite its empirical success, theoretical analysis of this heuristic has been limited. A recent breakthrough by Blanc et al. (ITCS, 2020) provided the first rigorous theoretical guarantees for the greedy approach, but only under the uniform distribution. We extend this analysis to the more general and practically relevant setting of arbitrary product distributions. Our main result shows that for any function $f$ computable by an optimal decision tree of size $s$, maximum depth $D_{\text{opt}}$, and average depth $Δ_{\text{opt}}$, the greedy heuristic constructs an $ε$-approximating tree whose size grows at most with $\exp\bigl(Δ_{\text{opt}} D_{\text{opt}} \log(e/ε)\bigr)$. In the special case where the optimal tree is a full binary tree, this bound improves upon the bound of Blanc et al. and holds under a strictly broader class of distributions. Moreover, we present an algorithm based on the top-down greedy heuristic that is entirely parameter-free -- it requires no prior knowledge of the optimal tree's size or depth -- offering a practical advantage over Blanc et al.'s method.
Replicable Composition
Apr 12, 2026Replicability requires that algorithmic conclusions remain consistent when rerun on independently drawn data. A central structural question is composition: given $k$ problems each admitting a $ρ$-replicable algorithm with sample complexity $n$, how many samples are needed to solve all jointly while preserving replicability? The naive analysis yields $\widetilde{O}(nk^2)$ samples, and Bun et al. (STOC'23) observed that reductions through differential privacy give an alternative $\widetilde{O}(n^2k)$ bound, leaving open whether the optimal $\widetilde{O}(nk)$ scaling is achievable. We resolve this open problem and, more generally, show that problems with sample complexities $n_1,\ldots,n_k$ can be jointly solved with $\widetilde{O}(\sum_i n_i)$ samples while preserving constant replicability. Our approach converts each replicable algorithm into a perfectly generalizing one, composes them via a privacy-style analysis, and maps back via correlated sampling. This yields the first advanced composition theorem for replicability. En route, we obtain new bounds for the composition of perfectly generalizing algorithms with heterogeneous parameters. As part of our results, we provide a boosting theorem for the success probability of replicable algorithms. For a broad class of problems, the failure probability appears as a separate additive term independent of $ρ$, immediately yielding improved sample complexity bounds for several problems. Finally, we prove an $Ω(nk^2)$ lower bound for adaptive composition, establishing a quadratic separation from the non-adaptive setting. The key technique, which we call the phantom run, yields structural results of independent interest.
Active Learning for Decision Trees with Provable Guarantees
Jan 28, 2026This paper advances the theoretical understanding of active learning label complexity for decision trees as binary classifiers. We make two main contributions. First, we provide the first analysis of the disagreement coefficient for decision trees-a key parameter governing active learning label complexity. Our analysis holds under two natural assumptions required for achieving polylogarithmic label complexity, (i) each root-to-leaf path queries distinct feature dimensions, and (ii) the input data has a regular, grid-like structure. We show these assumptions are essential, as relaxing them leads to polynomial label complexity. Second, we present the first general active learning algorithm for binary classification that achieves a multiplicative error guarantee, producing a $(1+ε)$-approximate classifier. By combining these results, we design an active learning algorithm for decision trees that uses only a polylogarithmic number of label queries in the dataset size, under the stated assumptions. Finally, we establish a label complexity lower bound, showing our algorithm's dependence on the error tolerance $ε$ is close to optimal.
Less is More: Adaptive Coverage for Synthetic Training Data
Apr 20, 2025Synthetic training data generation with Large Language Models (LLMs) like Google's Gemma and OpenAI's GPT offer a promising solution to the challenge of obtaining large, labeled datasets for training classifiers. When rapid model deployment is critical, such as in classifying emerging social media trends or combating new forms of online abuse tied to current events, the ability to generate training data is invaluable. While prior research has examined the comparability of synthetic data to human-labeled data, this study introduces a novel sampling algorithm, based on the maximum coverage problem, to select a representative subset from a synthetically generated dataset. Our results demonstrate that training a classifier on this contextually sampled subset achieves superior performance compared to training on the entire dataset. This "less is more" approach not only improves accuracy but also reduces the volume of data required, leading to potentially more efficient model fine-tuning.
A Dynamic Algorithm for Weighted Submodular Cover Problem
Jul 13, 2024We initiate the study of the submodular cover problem in dynamic setting where the elements of the ground set are inserted and deleted. In the classical submodular cover problem, we are given a monotone submodular function $f : 2^{V} \to \mathbb{R}^{\ge 0}$ and the goal is to obtain a set $S \subseteq V$ that minimizes the cost subject to the constraint $f(S) = f(V)$. This is a classical problem in computer science and generalizes the Set Cover problem, 2-Set Cover, and dominating set problem among others. We consider this problem in a dynamic setting where there are updates to our set $V$, in the form of insertions and deletions of elements from a ground set $\mathcal{V}$, and the goal is to maintain an approximately optimal solution with low query complexity per update. For this problem, we propose a randomized algorithm that, in expectation, obtains a $(1-O(\epsilon), O(\epsilon^{-1}))$-bicriteria approximation using polylogarithmic query complexity per update.
Ad Auctions for LLMs via Retrieval Augmented Generation
Jun 12, 2024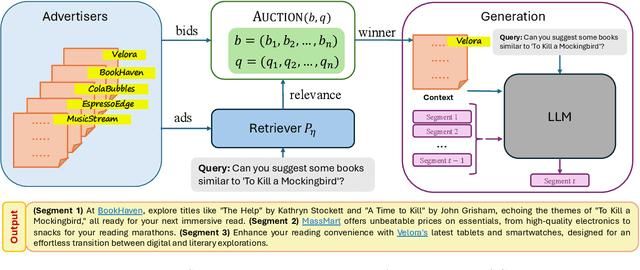



In the field of computational advertising, the integration of ads into the outputs of large language models (LLMs) presents an opportunity to support these services without compromising content integrity. This paper introduces novel auction mechanisms for ad allocation and pricing within the textual outputs of LLMs, leveraging retrieval-augmented generation (RAG). We propose a segment auction where an ad is probabilistically retrieved for each discourse segment (paragraph, section, or entire output) according to its bid and relevance, following the RAG framework, and priced according to competing bids. We show that our auction maximizes logarithmic social welfare, a new notion of welfare that balances allocation efficiency and fairness, and we characterize the associated incentive-compatible pricing rule. These results are extended to multi-ad allocation per segment. An empirical evaluation validates the feasibility and effectiveness of our approach over several ad auction scenarios, and exhibits inherent tradeoffs in metrics as we allow the LLM more flexibility to allocate ads.
Dueling Over Dessert, Mastering the Art of Repeated Cake Cutting
Feb 18, 2024



We consider the setting of repeated fair division between two players, denoted Alice and Bob, with private valuations over a cake. In each round, a new cake arrives, which is identical to the ones in previous rounds. Alice cuts the cake at a point of her choice, while Bob chooses the left piece or the right piece, leaving the remainder for Alice. We consider two versions: sequential, where Bob observes Alice's cut point before choosing left/right, and simultaneous, where he only observes her cut point after making his choice. The simultaneous version was first considered by Aumann and Maschler (1995). We observe that if Bob is almost myopic and chooses his favorite piece too often, then he can be systematically exploited by Alice through a strategy akin to a binary search. This strategy allows Alice to approximate Bob's preferences with increasing precision, thereby securing a disproportionate share of the resource over time. We analyze the limits of how much a player can exploit the other one and show that fair utility profiles are in fact achievable. Specifically, the players can enforce the equitable utility profile of $(1/2, 1/2)$ in the limit on every trajectory of play, by keeping the other player's utility to approximately $1/2$ on average while guaranteeing they themselves get at least approximately $1/2$ on average. We show this theorem using a connection with Blackwell approachability. Finally, we analyze a natural dynamic known as fictitious play, where players best respond to the empirical distribution of the other player. We show that fictitious play converges to the equitable utility profile of $(1/2, 1/2)$ at a rate of $O(1/\sqrt{T})$.
Replication-proof Bandit Mechanism Design
Dec 28, 2023
We study a problem of designing replication-proof bandit mechanisms when agents strategically register or replicate their own arms to maximize their payoff. We consider Bayesian agents who are unaware of ex-post realization of their own arms' mean rewards, which is the first to study Bayesian extension of Shin et al. (2022). This extension presents significant challenges in analyzing equilibrium, in contrast to the fully-informed setting by Shin et al. (2022) under which the problem simply reduces to a case where each agent only has a single arm. With Bayesian agents, even in a single-agent setting, analyzing the replication-proofness of an algorithm becomes complicated. Remarkably, we first show that the algorithm proposed by Shin et al. (2022), defined H-UCB, is no longer replication-proof for any exploration parameters. Then, we provide sufficient and necessary conditions for an algorithm to be replication-proof in the single-agent setting. These results centers around several analytical results in comparing the expected regret of multiple bandit instances, which might be of independent interest. We further prove that exploration-then-commit (ETC) algorithm satisfies these properties, whereas UCB does not, which in fact leads to the failure of being replication-proof. We expand this result to multi-agent setting, and provide a replication-proof algorithm for any problem instance. The proof mainly relies on the single-agent result, as well as some structural properties of ETC and the novel introduction of a restarting round, which largely simplifies the analysis while maintaining the regret unchanged (up to polylogarithmic factor). We finalize our result by proving its sublinear regret upper bound, which matches that of H-UCB.
Fair Polylog-Approximate Low-Cost Hierarchical Clustering
Nov 21, 2023



Research in fair machine learning, and particularly clustering, has been crucial in recent years given the many ethical controversies that modern intelligent systems have posed. Ahmadian et al. [2020] established the study of fairness in \textit{hierarchical} clustering, a stronger, more structured variant of its well-known flat counterpart, though their proposed algorithm that optimizes for Dasgupta's [2016] famous cost function was highly theoretical. Knittel et al. [2023] then proposed the first practical fair approximation for cost, however they were unable to break the polynomial-approximate barrier they posed as a hurdle of interest. We break this barrier, proposing the first truly polylogarithmic-approximate low-cost fair hierarchical clustering, thus greatly bridging the gap between the best fair and vanilla hierarchical clustering approximations.
Online Advertisements with LLMs: Opportunities and Challenges
Nov 11, 2023


This paper explores the potential for leveraging Large Language Models (LLM) in the realm of online advertising systems. We delve into essential requirements including privacy, latency, reliability, users and advertisers' satisfaction, which such a system must fulfill. We further introduce a general framework for LLM advertisement, consisting of modification, bidding, prediction, and auction modules. Different design considerations for each module is presented, with an in-depth examination of their practicality and the technical challenges inherent to their implementation.