 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Baseline for Predicting Events with Auto-Regressive Tabular Transformers
Oct 14, 2024Many real-world applications of tabular data involve using historic events to predict properties of new ones, for example whether a credit card transaction is fraudulent or what rating a customer will assign a product on a retail platform. Existing approaches to event prediction include costly, brittle, and application-dependent techniques such as time-aware positional embeddings, learned row and field encodings, and oversampling methods for addressing class imbalance. Moreover, these approaches often assume specific use-cases, for example that we know the labels of all historic events or that we only predict a pre-specified label and not the data's features themselves. In this work, we propose a simple but flexible baseline using standard autoregressive LLM-style transformers with elementary positional embeddings and a causal language modeling objective. Our baseline outperforms existing approaches across popular datasets and can be employed for various use-cases. We demonstrate that the same model can predict labels, impute missing values, or model event sequences.
Fair Clustering: Critique, Caveats, and Future Directions
Jun 22, 2024Clustering is a fundamental problem in machine learning and operations research. Therefore, given the fact that fairness considerations have become of paramount importance in algorithm design, fairness in clustering has received significant attention from the research community. The literature on fair clustering has resulted in a collection of interesting fairness notions and elaborate algorithms. In this paper, we take a critical view of fair clustering, identifying a collection of ignored issues such as the lack of a clear utility characterization and the difficulty in accounting for the downstream effects of a fair clustering algorithm in machine learning settings. In some cases, we demonstrate examples where the application of a fair clustering algorithm can have significant negative impacts on social welfare. We end by identifying a collection of steps that would lead towards more impactful research in fair clustering.
Fair Polylog-Approximate Low-Cost Hierarchical Clustering
Nov 21, 2023



Research in fair machine learning, and particularly clustering, has been crucial in recent years given the many ethical controversies that modern intelligent systems have posed. Ahmadian et al. [2020] established the study of fairness in \textit{hierarchical} clustering, a stronger, more structured variant of its well-known flat counterpart, though their proposed algorithm that optimizes for Dasgupta's [2016] famous cost function was highly theoretical. Knittel et al. [2023] then proposed the first practical fair approximation for cost, however they were unable to break the polynomial-approximate barrier they posed as a hurdle of interest. We break this barrier, proposing the first truly polylogarithmic-approximate low-cost fair hierarchical clustering, thus greatly bridging the gap between the best fair and vanilla hierarchical clustering approximations.
Doubly Constrained Fair Clustering
May 31, 2023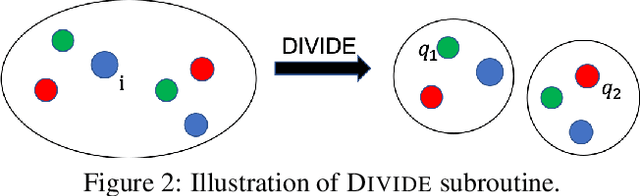
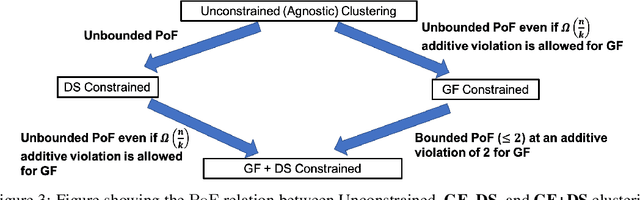
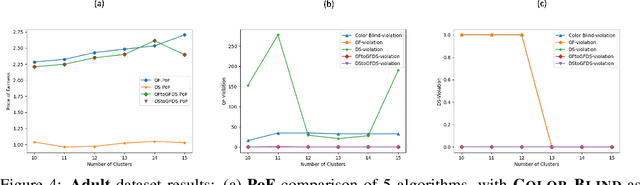
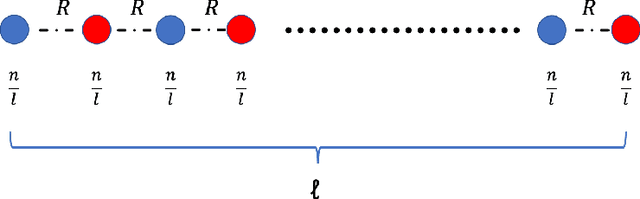
The remarkable attention which fair clustering has received in the last few years has resulted in a significant number of different notions of fairness. Despite the fact that these notions are well-justified, they are often motivated and studied in a disjoint manner where one fairness desideratum is considered exclusively in isolation from the others. This leaves the understanding of the relations between different fairness notions as an important open problem in fair clustering. In this paper, we take the first step in this direction. Specifically, we consider the two most prominent demographic representation fairness notions in clustering: (1) Group Fairness (GF), where the different demographic groups are supposed to have close to population-level representation in each cluster and (2) Diversity in Center Selection (DS), where the selected centers are supposed to have close to population-level representation of each group. We show that given a constant approximation algorithm for one constraint (GF or DS only) we can obtain a constant approximation solution that satisfies both constraints simultaneously. Interestingly, we prove that any given solution that satisfies the GF constraint can always be post-processed at a bounded degradation to the clustering cost to additionally satisfy the DS constraint while the reverse is not true. Furthermore, we show that both GF and DS are incompatible (having an empty feasibility set in the worst case) with a collection of other distance-based fairness notions. Finally, we carry experiments to validate our theoretical findings.
Artificial Intelligence/Operations Research Workshop 2 Report Out
Apr 10, 2023



This workshop Report Out focuses on the foundational elements of trustworthy AI and OR technology, and how to ensure all AI and OR systems implement these elements in their system designs. Four sessions on various topics within Trustworthy AI were held, these being Fairness, Explainable AI/Causality, Robustness/Privacy, and Human Alignment and Human-Computer Interaction. Following discussions of each of these topics, workshop participants also brainstormed challenge problems which require the collaboration of AI and OR researchers and will result in the integration of basic techniques from both fields to eventually benefit societal needs.
Reckoning with the Disagreement Problem: Explanation Consensus as a Training Objective
Mar 23, 2023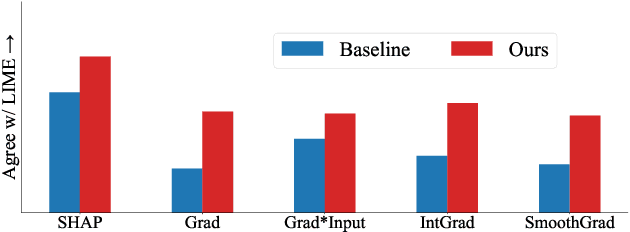

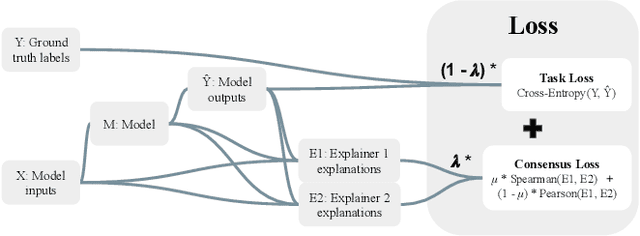
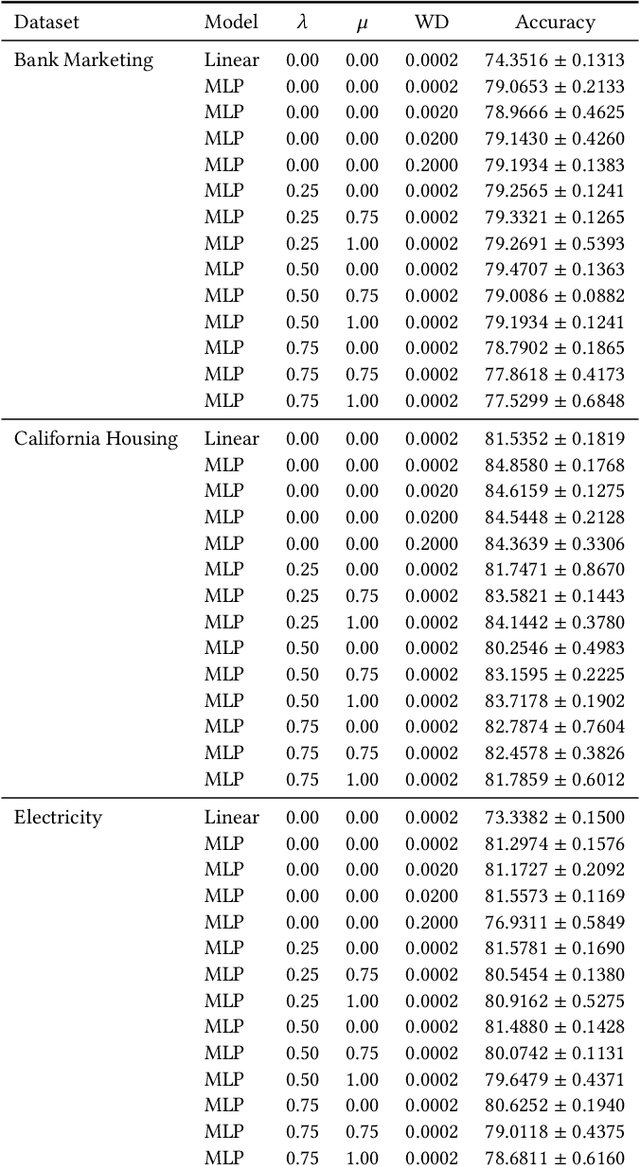
As neural networks increasingly make critical decisions in high-stakes settings, monitoring and explaining their behavior in an understandable and trustworthy manner is a necessity. One commonly used type of explainer is post hoc feature attribution, a family of methods for giving each feature in an input a score corresponding to its influence on a model's output. A major limitation of this family of explainers in practice is that they can disagree on which features are more important than others. Our contribution in this paper is a method of training models with this disagreement problem in mind. We do this by introducing a Post hoc Explainer Agreement Regularization (PEAR) loss term alongside the standard term corresponding to accuracy, an additional term that measures the difference in feature attribution between a pair of explainers. We observe on three datasets that we can train a model with this loss term to improve explanation consensus on unseen data, and see improved consensus between explainers other than those used in the loss term. We examine the trade-off between improved consensus and model performance. And finally, we study the influence our method has on feature attribution explanations.
Neural Auctions Compromise Bidder Information
Feb 28, 2023



Single-shot auctions are commonly used as a means to sell goods, for example when selling ad space or allocating radio frequencies, however devising mechanisms for auctions with multiple bidders and multiple items can be complicated. It has been shown that neural networks can be used to approximate optimal mechanisms while satisfying the constraints that an auction be strategyproof and individually rational. We show that despite such auctions maximizing revenue, they do so at the cost of revealing private bidder information. While randomness is often used to build in privacy, in this context it comes with complications if done without care. Specifically, it can violate rationality and feasibility constraints, fundamentally change the incentive structure of the mechanism, and/or harm top-level metrics such as revenue and social welfare. We propose a method that employs stochasticity to improve privacy while meeting the requirements for auction mechanisms with only a modest sacrifice in revenue. We analyze the cost to the auction house that comes with introducing varying degrees of privacy in common auction settings. Our results show that despite current neural auctions' ability to approximate optimal mechanisms, the resulting vulnerability that comes with relying on neural networks must be accounted for.
Targets in Reinforcement Learning to solve Stackelberg Security Games
Nov 30, 2022Reinforcement Learning (RL) algorithms have been successfully applied to real world situations like illegal smuggling, poaching, deforestation, climate change, airport security, etc. These scenarios can be framed as Stackelberg security games (SSGs) where defenders and attackers compete to control target resources. The algorithm's competency is assessed by which agent is controlling the targets. This review investigates modeling of SSGs in RL with a focus on possible improvements of target representations in RL algorithms.
Achieving Downstream Fairness with Geometric Repair
Mar 14, 2022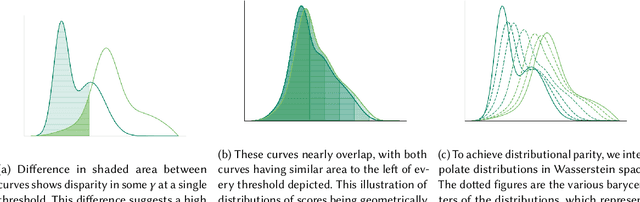
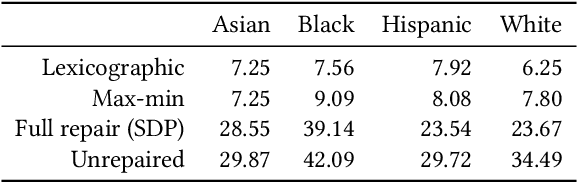
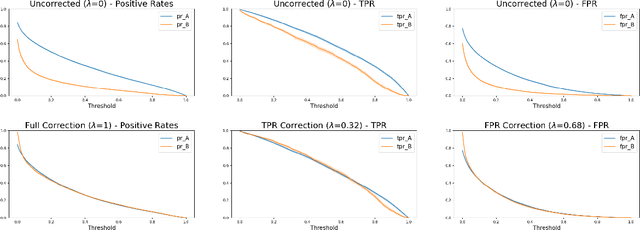

Consider a scenario where some upstream model developer must train a fair model, but is unaware of the fairness requirements of a downstream model user or stakeholder. In the context of fair classification, we present a technique that specifically addresses this setting, by post-processing a regressor's scores such they yield fair classifications for any downstream choice in decision threshold. To begin, we leverage ideas from optimal transport to show how this can be achieved for binary protected groups across a broad class of fairness metrics. Then, we extend our approach to address the setting where a protected attribute takes on multiple values, by re-recasting our technique as a convex optimization problem that leverages lexicographic fairness.
Differentiable Economics for Randomized Affine Maximizer Auctions
Feb 06, 2022



A recent approach to automated mechanism design, differentiable economics, represents auctions by rich function approximators and optimizes their performance by gradient descent. The ideal auction architecture for differentiable economics would be perfectly strategyproof, support multiple bidders and items, and be rich enough to represent the optimal (i.e. revenue-maximizing) mechanism. So far, such an architecture does not exist. There are single-bidder approaches (MenuNet, RochetNet) which are always strategyproof and can represent optimal mechanisms. RegretNet is multi-bidder and can approximate any mechanism, but is only approximately strategyproof. We present an architecture that supports multiple bidders and is perfectly strategyproof, but cannot necessarily represent the optimal mechanism. This architecture is the classic affine maximizer auction (AMA), modified to offer lotteries. By using the gradient-based optimization tools of differentiable economics, we can now train lottery AMAs, competing with or outperforming prior approaches in revenue.