 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYETI (YET to Intervene) Proactive Interventions by Multimodal AI Agents in Augmented Reality Tasks
Jan 16, 2025



Multimodal AI Agents are AI models that have the capability of interactively and cooperatively assisting human users to solve day-to-day tasks. Augmented Reality (AR) head worn devices can uniquely improve the user experience of solving procedural day-to-day tasks by providing egocentric multimodal (audio and video) observational capabilities to AI Agents. Such AR capabilities can help AI Agents see and listen to actions that users take which can relate to multimodal capabilities of human users. Existing AI Agents, either Large Language Models (LLMs) or Multimodal Vision-Language Models (VLMs) are reactive in nature, which means that models cannot take an action without reading or listening to the human user's prompts. Proactivity of AI Agents on the other hand can help the human user detect and correct any mistakes in agent observed tasks, encourage users when they do tasks correctly or simply engage in conversation with the user - akin to a human teaching or assisting a user. Our proposed YET to Intervene (YETI) multimodal agent focuses on the research question of identifying circumstances that may require the agent to intervene proactively. This allows the agent to understand when it can intervene in a conversation with human users that can help the user correct mistakes on tasks, like cooking, using AR. Our YETI Agent learns scene understanding signals based on interpretable notions of Structural Similarity (SSIM) on consecutive video frames. We also define the alignment signal which the AI Agent can learn to identify if the video frames corresponding to the user's actions on the task are consistent with expected actions. These signals are used by our AI Agent to determine when it should proactively intervene. We compare our results on the instances of proactive intervention in the HoloAssist multimodal benchmark for an expert agent guiding a user to complete procedural tasks.
On the Complexity of Learning to Cooperate with Populations of Socially Rational Agents
Jun 29, 2024
Artificially intelligent agents deployed in the real-world will require the ability to reliably \textit{cooperate} with humans (as well as other, heterogeneous AI agents). To provide formal guarantees of successful cooperation, we must make some assumptions about how partner agents could plausibly behave. Any realistic set of assumptions must account for the fact that other agents may be just as adaptable as our agent is. In this work, we consider the problem of cooperating with a \textit{population} of agents in a finitely-repeated, two player general-sum matrix game with private utilities. Two natural assumptions in such settings are that: 1) all agents in the population are individually rational learners, and 2) when any two members of the population are paired together, with high-probability they will achieve at least the same utility as they would under some Pareto efficient equilibrium strategy. Our results first show that these assumptions alone are insufficient to ensure \textit{zero-shot} cooperation with members of the target population. We therefore consider the problem of \textit{learning} a strategy for cooperating with such a population using prior observations its members interacting with one another. We provide upper and lower bounds on the number of samples needed to learn an effective cooperation strategy. Most importantly, we show that these bounds can be much stronger than those arising from a "naive'' reduction of the problem to one of imitation learning.
JaxMARL: Multi-Agent RL Environments in JAX
Nov 20, 2023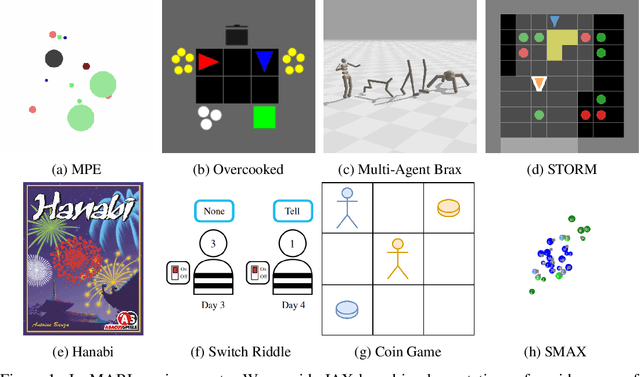

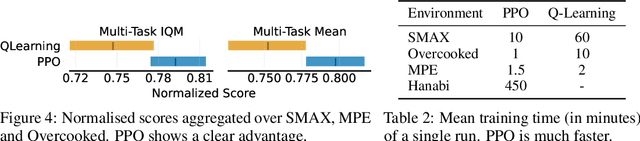
Benchmarks play an important role in the development of machine learning algorithms. For example, research in reinforcement learning (RL) has been heavily influenced by available environments and benchmarks. However, RL environments are traditionally run on the CPU, limiting their scalability with typical academic compute. Recent advancements in JAX have enabled the wider use of hardware acceleration to overcome these computational hurdles, enabling massively parallel RL training pipelines and environments. This is particularly useful for multi-agent reinforcement learning (MARL) research. First of all, multiple agents must be considered at each environment step, adding computational burden, and secondly, the sample complexity is increased due to non-stationarity, decentralised partial observability, or other MARL challenges. In this paper, we present JaxMARL, the first open-source code base that combines ease-of-use with GPU enabled efficiency, and supports a large number of commonly used MARL environments as well as popular baseline algorithms. When considering wall clock time, our experiments show that per-run our JAX-based training pipeline is up to 12500x faster than existing approaches. This enables efficient and thorough evaluations, with the potential to alleviate the evaluation crisis of the field. We also introduce and benchmark SMAX, a vectorised, simplified version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine. This not only enables GPU acceleration, but also provides a more flexible MARL environment, unlocking the potential for self-play, meta-learning, and other future applications in MARL. We provide code at https://github.com/flairox/jaxmarl.
Targets in Reinforcement Learning to solve Stackelberg Security Games
Nov 30, 2022Reinforcement Learning (RL) algorithms have been successfully applied to real world situations like illegal smuggling, poaching, deforestation, climate change, airport security, etc. These scenarios can be framed as Stackelberg security games (SSGs) where defenders and attackers compete to control target resources. The algorithm's competency is assessed by which agent is controlling the targets. This review investigates modeling of SSGs in RL with a focus on possible improvements of target representations in RL algorithms.
Improving Question Answering with Generation of NQ-like Questions
Oct 12, 2022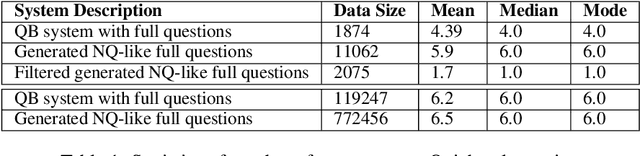
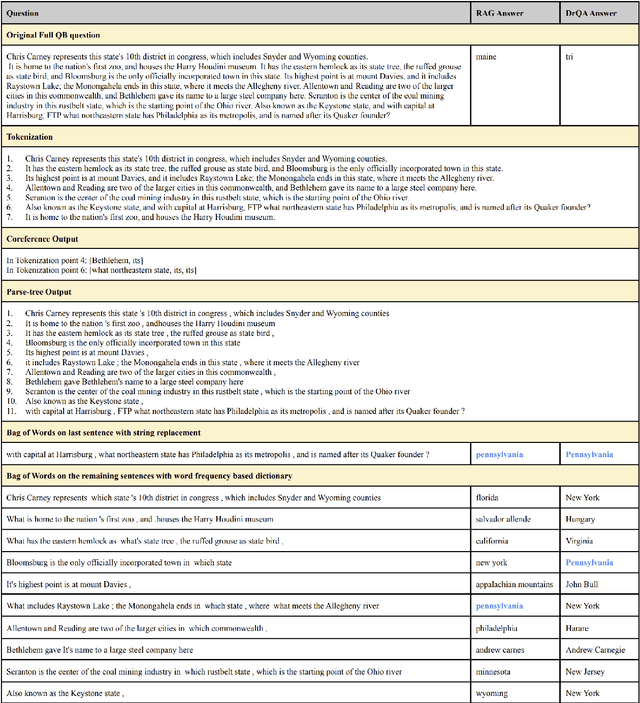
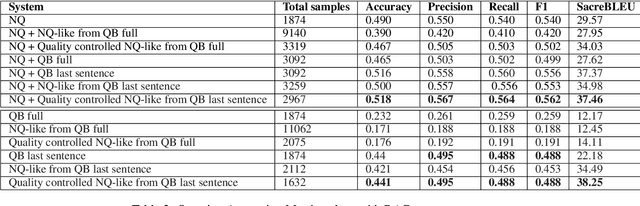
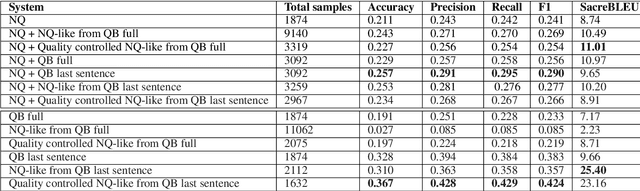
Question Answering (QA) systems require a large amount of annotated data which is costly and time-consuming to gather. Converting datasets of existing QA benchmarks are challenging due to different formats and complexities. To address these issues, we propose an algorithm to automatically generate shorter questions resembling day-to-day human communication in the Natural Questions (NQ) dataset from longer trivia questions in Quizbowl (QB) dataset by leveraging conversion in style among the datasets. This provides an automated way to generate more data for our QA systems. To ensure quality as well as quantity of data, we detect and remove ill-formed questions using a neural classifier. We demonstrate that in a low resource setting, using the generated data improves the QA performance over the baseline system on both NQ and QB data. Our algorithm improves the scalability of training data while maintaining quality of data for QA systems.
Read, Highlight and Summarize: A Hierarchical Neural Semantic Encoder-based Approach
Nov 01, 2019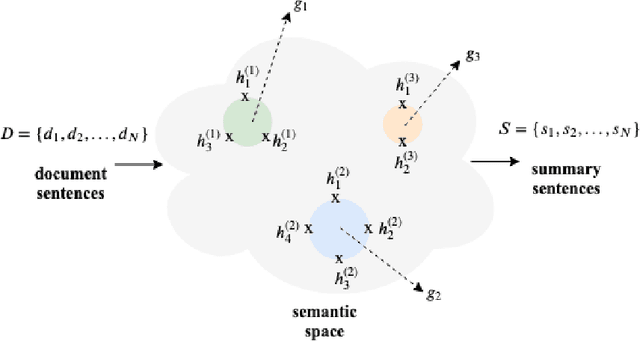
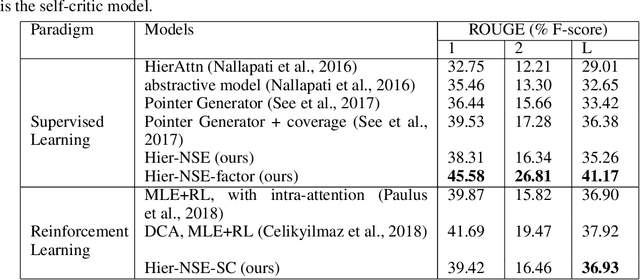
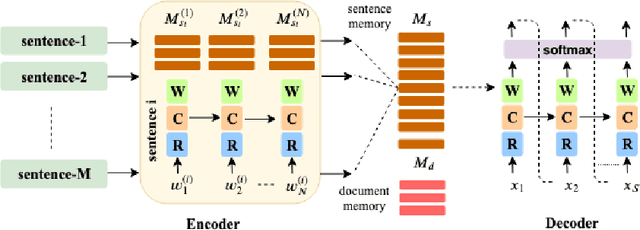
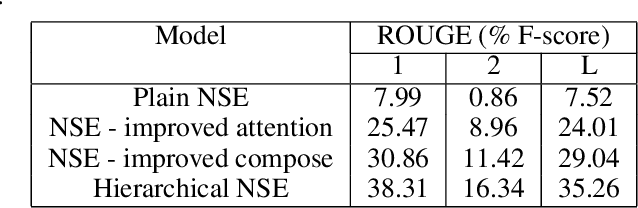
Traditional sequence-to-sequence (seq2seq) models and other variations of the attention-mechanism such as hierarchical attention have been applied to the text summarization problem. Though there is a hierarchy in the way humans use language by forming paragraphs from sentences and sentences from words, hierarchical models have usually not worked that much better than their traditional seq2seq counterparts. This effect is mainly because either the hierarchical attention mechanisms are too sparse using hard attention or noisy using soft attention. In this paper, we propose a method based on extracting the highlights of a document; a key concept that is conveyed in a few sentences. In a typical text summarization dataset consisting of documents that are 800 tokens in length (average), capturing long-term dependencies is very important, e.g., the last sentence can be grouped with the first sentence of a document to form a summary. LSTMs (Long Short-Term Memory) proved useful for machine translation. However, they often fail to capture long-term dependencies while modeling long sequences. To address these issues, we have adapted Neural Semantic Encoders (NSE) to text summarization, a class of memory-augmented neural networks by improving its functionalities and proposed a novel hierarchical NSE that outperforms similar previous models significantly. The quality of summarization was improved by augmenting linguistic factors, namely lemma, and Part-of-Speech (PoS) tags, to each word in the dataset for improved vocabulary coverage and generalization. The hierarchical NSE model on factored dataset outperformed the state-of-the-art by nearly 4 ROUGE points. We further designed and used the first GPU-based self-critical Reinforcement Learning model.