 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Question Answering with Generation of NQ-like Questions
Paper and Code
Oct 12, 2022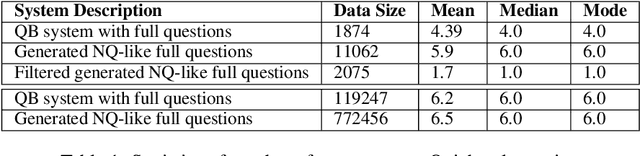
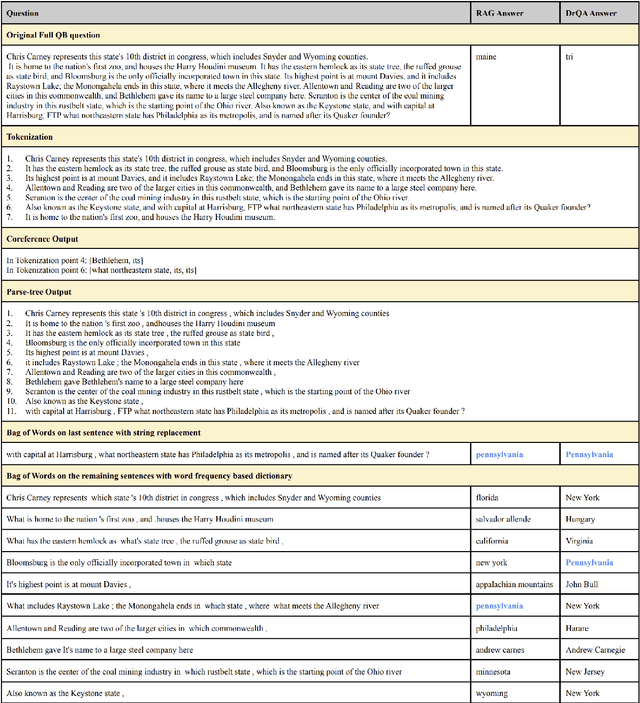
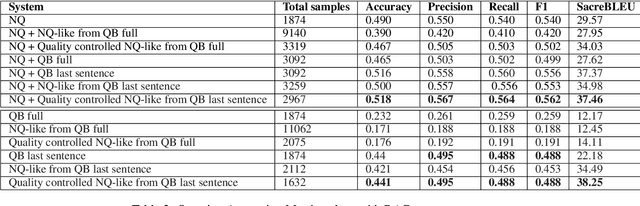
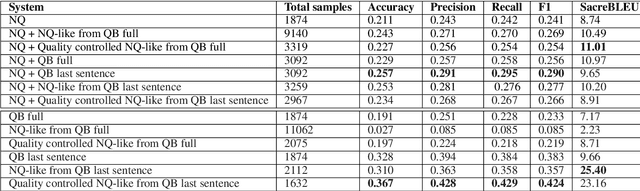
Question Answering (QA) systems require a large amount of annotated data which is costly and time-consuming to gather. Converting datasets of existing QA benchmarks are challenging due to different formats and complexities. To address these issues, we propose an algorithm to automatically generate shorter questions resembling day-to-day human communication in the Natural Questions (NQ) dataset from longer trivia questions in Quizbowl (QB) dataset by leveraging conversion in style among the datasets. This provides an automated way to generate more data for our QA systems. To ensure quality as well as quantity of data, we detect and remove ill-formed questions using a neural classifier. We demonstrate that in a low resource setting, using the generated data improves the QA performance over the baseline system on both NQ and QB data. Our algorithm improves the scalability of training data while maintaining quality of data for QA systems.