 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Question Answering with Generation of NQ-like Questions
Oct 12, 2022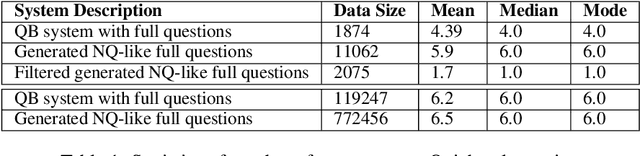
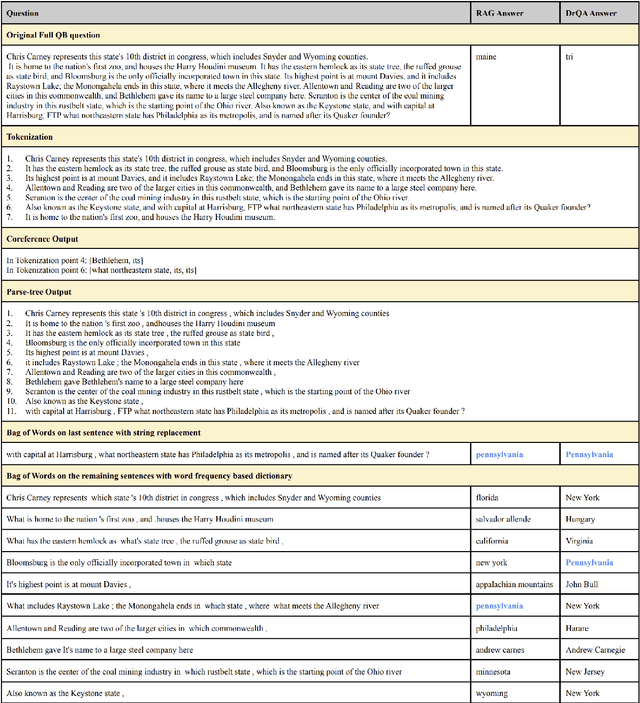
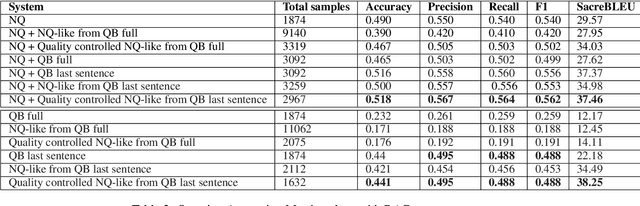
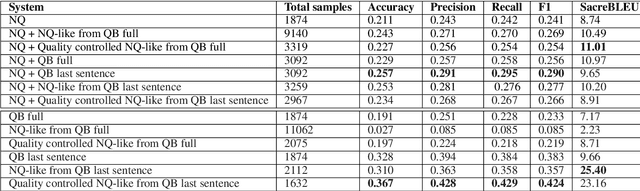
Question Answering (QA) systems require a large amount of annotated data which is costly and time-consuming to gather. Converting datasets of existing QA benchmarks are challenging due to different formats and complexities. To address these issues, we propose an algorithm to automatically generate shorter questions resembling day-to-day human communication in the Natural Questions (NQ) dataset from longer trivia questions in Quizbowl (QB) dataset by leveraging conversion in style among the datasets. This provides an automated way to generate more data for our QA systems. To ensure quality as well as quantity of data, we detect and remove ill-formed questions using a neural classifier. We demonstrate that in a low resource setting, using the generated data improves the QA performance over the baseline system on both NQ and QB data. Our algorithm improves the scalability of training data while maintaining quality of data for QA systems.
Server-Side Local Gradient Averaging and Learning Rate Acceleration for Scalable Split Learning
Dec 11, 2021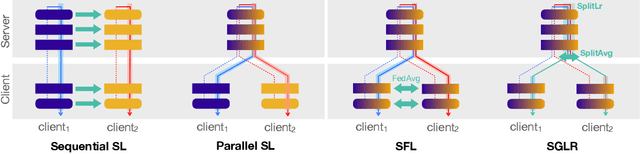
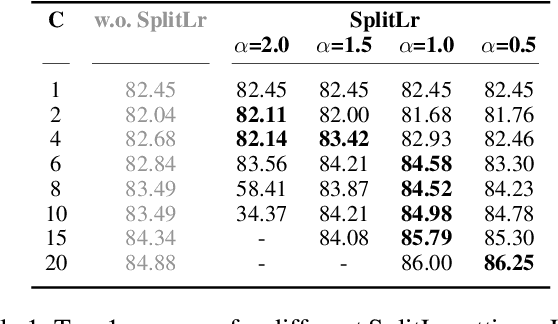
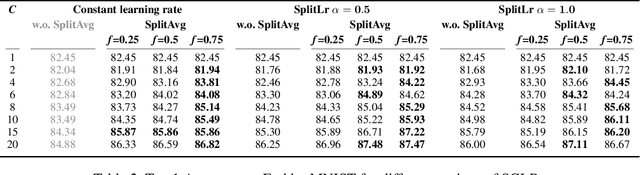

In recent years, there have been great advances in the field of decentralized learning with private data. Federated learning (FL) and split learning (SL) are two spearheads possessing their pros and cons, and are suited for many user clients and large models, respectively. To enjoy both benefits, hybrid approaches such as SplitFed have emerged of late, yet their fundamentals have still been illusive. In this work, we first identify the fundamental bottlenecks of SL, and thereby propose a scalable SL framework, coined SGLR. The server under SGLR broadcasts a common gradient averaged at the split-layer, emulating FL without any additional communication across clients as opposed to SplitFed. Meanwhile, SGLR splits the learning rate into its server-side and client-side rates, and separately adjusts them to support many clients in parallel. Simulation results corroborate that SGLR achieves higher accuracy than other baseline SL methods including SplitFed, which is even on par with FL consuming higher energy and communication costs. As a secondary result, we observe greater reduction in leakage of sensitive information via mutual information using SLGR over the baselines.
Leveraging recent advances in Pre-Trained Language Models forEye-Tracking Prediction
Oct 09, 2021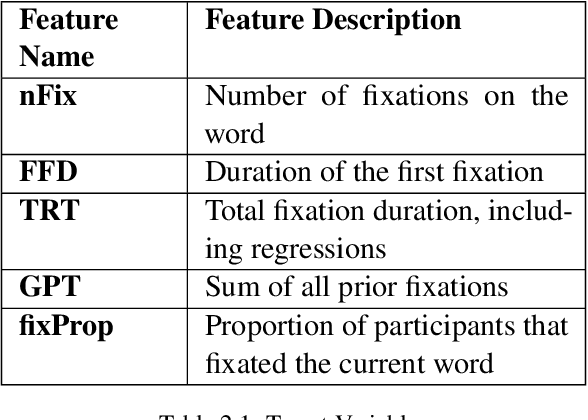
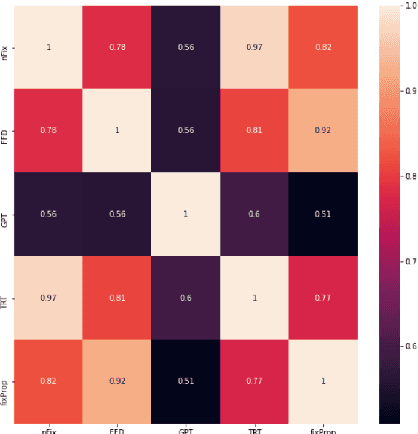
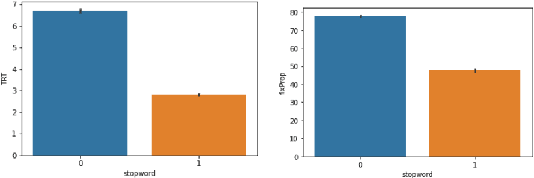
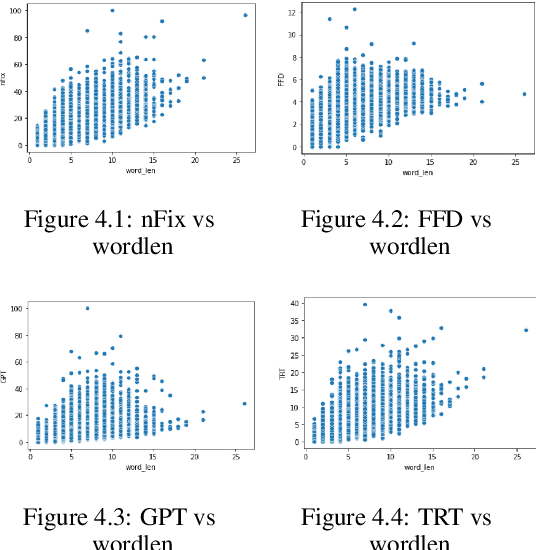
Cognitively inspired Natural Language Pro-cessing uses human-derived behavioral datalike eye-tracking data, which reflect the seman-tic representations of language in the humanbrain to augment the neural nets to solve arange of tasks spanning syntax and semanticswith the aim of teaching machines about lan-guage processing mechanisms. In this paper,we use the ZuCo 1.0 and ZuCo 2.0 dataset con-taining the eye-gaze features to explore differ-ent linguistic models to directly predict thesegaze features for each word with respect to itssentence. We tried different neural networkmodels with the words as inputs to predict thetargets. And after lots of experimentation andfeature engineering finally devised a novel ar-chitecture consisting of RoBERTa Token Clas-sifier with a dense layer on top for languagemodeling and a stand-alone model consistingof dense layers followed by a transformer layerfor the extra features we engineered. Finally,we took the mean of the outputs of both thesemodels to make the final predictions. We eval-uated the models using mean absolute error(MAE) and the R2 score for each target.