 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaFace: High Fidelity and Real-time Face Swapper Robust to Facial Pose
Jan 23, 2026Existing face-swapping methods often deliver competitive results in constrained settings but exhibit substantial quality degradation when handling extreme facial poses. To improve facial pose robustness, explicit geometric features are applied, but this approach remains problematic since it introduces additional dependencies and increases computational cost. Diffusion-based methods have achieved remarkable results; however, they are impractical for real-time processing. We introduce AlphaFace, which leverages an open-source vision-language model and CLIP image and text embeddings to apply novel visual and textual semantic contrastive losses. AlphaFace enables stronger identity representation and more precise attribute preservation, all while maintaining real-time performance. Comprehensive experiments across FF++, MPIE, and LPFF demonstrate that AlphaFace surpasses state-of-the-art methods in pose-challenging cases. The project is publicly available on `https://github.com/andrewyu90/Alphaface_Official.git'.
Regional Attention-Enhanced Swin Transformer for Clinically Relevant Medical Image Captioning
Nov 13, 2025Automated medical image captioning translates complex radiological images into diagnostic narratives that can support reporting workflows. We present a Swin-BART encoder-decoder system with a lightweight regional attention module that amplifies diagnostically salient regions before cross-attention. Trained and evaluated on ROCO, our model achieves state-of-the-art semantic fidelity while remaining compact and interpretable. We report results as mean$\pm$std over three seeds and include $95\%$ confidence intervals. Compared with baselines, our approach improves ROUGE (proposed 0.603, ResNet-CNN 0.356, BLIP2-OPT 0.255) and BERTScore (proposed 0.807, BLIP2-OPT 0.645, ResNet-CNN 0.623), with competitive BLEU, CIDEr, and METEOR. We further provide ablations (regional attention on/off and token-count sweep), per-modality analysis (CT/MRI/X-ray), paired significance tests, and qualitative heatmaps that visualize the regions driving each description. Decoding uses beam search (beam size $=4$), length penalty $=1.1$, $no\_repeat\_ngram\_size$ $=3$, and max length $=128$. The proposed design yields accurate, clinically phrased captions and transparent regional attributions, supporting safe research use with a human in the loop.
Unlocking Robust Semantic Segmentation Performance via Label-only Elastic Deformations against Implicit Label Noise
Aug 14, 2025While previous studies on image segmentation focus on handling severe (or explicit) label noise, real-world datasets also exhibit subtle (or implicit) label imperfections. These arise from inherent challenges, such as ambiguous object boundaries and annotator variability. Although not explicitly present, such mild and latent noise can still impair model performance. Typical data augmentation methods, which apply identical transformations to the image and its label, risk amplifying these subtle imperfections and limiting the model's generalization capacity. In this paper, we introduce NSegment+, a novel augmentation framework that decouples image and label transformations to address such realistic noise for semantic segmentation. By introducing controlled elastic deformations only to segmentation labels while preserving the original images, our method encourages models to focus on learning robust representations of object structures despite minor label inconsistencies. Extensive experiments demonstrate that NSegment+ consistently improves performance, achieving mIoU gains of up to +2.29, +2.38, +1.75, and +3.39 in average on Vaihingen, LoveDA, Cityscapes, and PASCAL VOC, respectively-even without bells and whistles, highlighting the importance of addressing implicit label noise. These gains can be further amplified when combined with other training tricks, including CutMix and Label Smoothing.
Multispectral Detection Transformer with Infrared-Centric Sensor Fusion
May 21, 2025
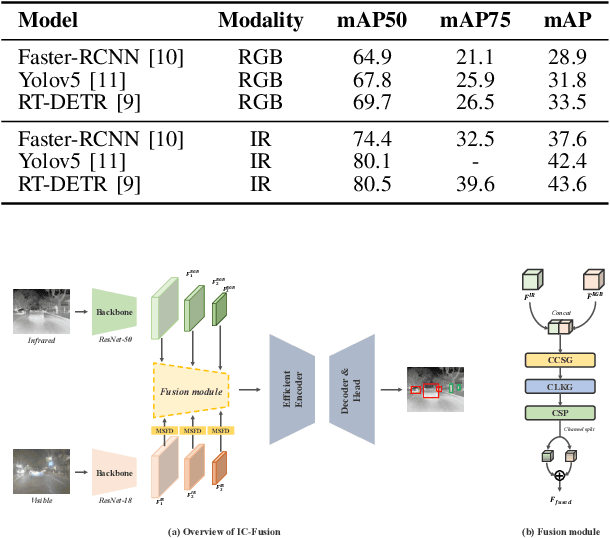


Multispectral object detection aims to leverage complementary information from visible (RGB) and infrared (IR) modalities to enable robust performance under diverse environmental conditions. In this letter, we propose IC-Fusion, a multispectral object detector that effectively fuses visible and infrared features through a lightweight and modalityaware design. Motivated by wavelet analysis and empirical observations, we find that IR images contain structurally rich high-frequency information critical for object localization, while RGB images provide complementary semantic context. To exploit this, we adopt a compact RGB backbone and design a novel fusion module comprising a Multi-Scale Feature Distillation (MSFD) block to enhance RGB features and a three-stage fusion block with Cross-Modal Channel Shuffle Gate (CCSG) and Cross-Modal Large Kernel Gate (CLKG) to facilitate effective cross-modal interaction. Experiments on the FLIR and LLVIP benchmarks demonstrate the effectiveness and efficiency of our IR-centric fusion strategy. Our code is available at https://github.com/smin-hwang/IC-Fusion.
NSegment : Noisy Segment Improves Remote Sensing Image Segmentation
Apr 28, 2025



Labeling errors in remote sensing (RS) image segmentation datasets often remain implicit and subtle due to ambiguous class boundaries, mixed pixels, shadows, complex terrain features, and subjective annotator bias. Furthermore, the scarcity of annotated RS data due to high image acquisition and labeling costs complicates training noise-robust models. While sophisticated mechanisms such as label selection or noise correction might address this issue, they tend to increase training time and add implementation complexity. In this letter, we propose NSegment-a simple yet effective data augmentation solution to mitigate this issue. Unlike traditional methods, it applies elastic transformations only to segmentation labels, varying deformation intensity per sample in each training epoch to address annotation inconsistencies. Experimental results demonstrate that our approach improves the performance of RS image segmentation on various state-of-the-art models.
DG-DETR: Toward Domain Generalized Detection Transformer
Apr 28, 2025
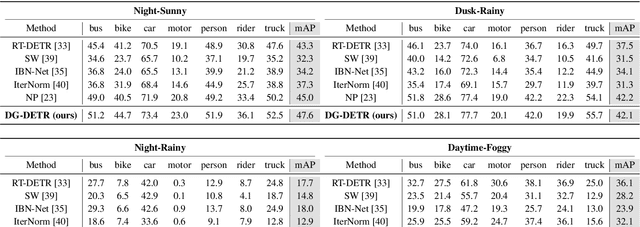


End-to-end Transformer-based detectors (DETRs) have demonstrated strong detection performance. However, domain generalization (DG) research has primarily focused on convolutional neural network (CNN)-based detectors, while paying little attention to enhancing the robustness of DETRs. In this letter, we introduce a Domain Generalized DEtection TRansformer (DG-DETR), a simple, effective, and plug-and-play method that improves out-of-distribution (OOD) robustness for DETRs. Specifically, we propose a novel domain-agnostic query selection strategy that removes domain-induced biases from object queries via orthogonal projection onto the instance-specific style space. Additionally, we leverage a wavelet decomposition to disentangle features into domain-invariant and domain-specific components, enabling synthesis of diverse latent styles while preserving the semantic features of objects. Experimental results validate the effectiveness of DG-DETR. Our code is available at https://github.com/sminhwang/DG-DETR.
3D Multi-Object Tracking Employing MS-GLMB Filter for Autonomous Driving
Oct 19, 2024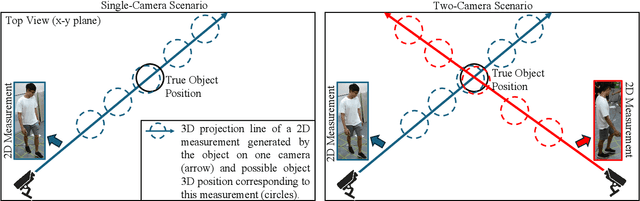
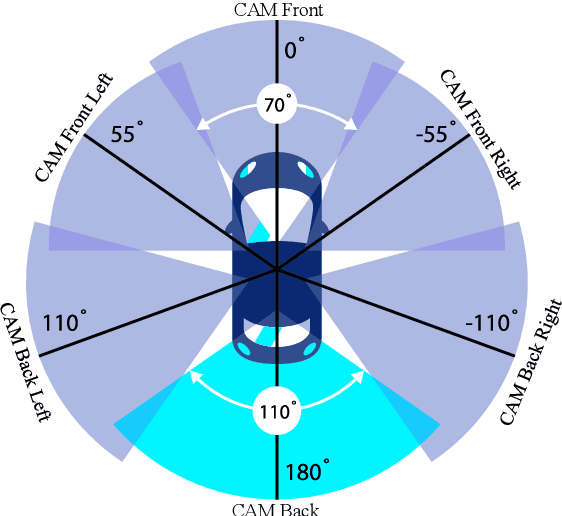
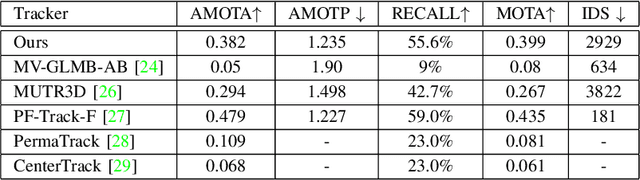
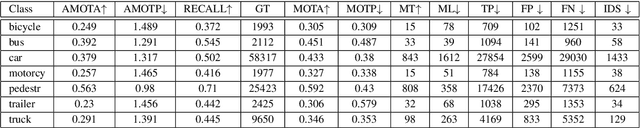
The MS-GLMB filter offers a robust framework for tracking multiple objects through the use of multi-sensor data. Building on this, the MV-GLMB and MV-GLMB-AB filters enhance the MS-GLMB capabilities by employing cameras for 3D multi-sensor multi-object tracking, effectively addressing occlusions. However, both filters depend on overlapping fields of view from the cameras to combine complementary information. In this paper, we introduce an improved approach that integrates an additional sensor, such as LiDAR, into the MS-GLMB framework for 3D multi-object tracking. Specifically, we present a new LiDAR measurement model, along with a multi-camera and LiDAR multi-object measurement model. Our experimental results demonstrate a significant improvement in tracking performance compared to existing MS-GLMB-based methods. Importantly, our method eliminates the need for overlapping fields of view, broadening the applicability of the MS-GLMB filter. Our source code for nuScenes dataset is available at https://github.com/linh-gist/ms-glmb-nuScenes.
NBBOX: Noisy Bounding Box Improves Remote Sensing Object Detection
Sep 14, 2024



Data augmentation has seen significant advancements in computer vision to improve model performance over the years, particularly in scenarios with limited and insufficient data. Currently, most studies focus on adjusting the image or its features to expand the size, quality, and variety of samples during training in various tasks including object detection. However, we argue that it is necessary to investigate bounding box transformations as a model regularization technique rather than image-level transformations, especially in aerial imagery due to potentially inconsistent bounding box annotations. Hence, this letter presents a thorough investigation of bounding box transformation in terms of scaling, rotation, and translation for remote sensing object detection. We call this augmentation strategy NBBOX (Noise Injection into Bounding Box). We conduct extensive experiments on DOTA and DIOR-R, both well-known datasets that include a variety of rotated generic objects in aerial images. Experimental results show that our approach significantly improves remote sensing object detection without whistles and bells and it is more time-efficient than other state-of-the-art augmentation strategies.
Rethinking Feature Backbone Fine-tuning for Remote Sensing Object Detection
Jul 21, 2024Recently, numerous methods have achieved impressive performance in remote sensing object detection, relying on convolution or transformer architectures. Such detectors typically have a feature backbone to extract useful features from raw input images. For the remote sensing domain, a common practice among current detectors is to initialize the backbone with pre-training on ImageNet consisting of natural scenes. Fine-tuning the backbone is typically required to generate features suitable for remote-sensing images. However, this could hinder the extraction of basic visual features in long-term training, thus restricting performance improvement. To mitigate this issue, we propose a novel method named DBF (Dynamic Backbone Freezing) for feature backbone fine-tuning on remote sensing object detection. Our method aims to handle the dilemma of whether the backbone should extract low-level generic features or possess specific knowledge of the remote sensing domain, by introducing a module called 'Freezing Scheduler' to dynamically manage the update of backbone features during training. Extensive experiments on DOTA and DIOR-R show that our approach enables more accurate model learning while substantially reducing computational costs. Our method can be seamlessly adopted without additional effort due to its straightforward design.
Visual Multi-Object Tracking with Re-Identification and Occlusion Handling using Labeled Random Finite Sets
Jul 11, 2024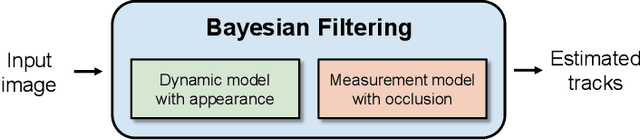


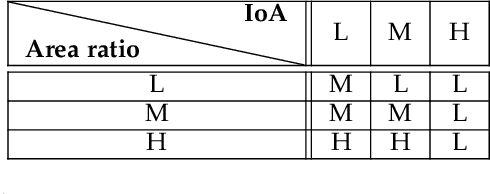
This paper proposes an online visual multi-object tracking (MOT) algorithm that resolves object appearance-reappearance and occlusion. Our solution is based on the labeled random finite set (LRFS) filtering approach, which in principle, addresses disappearance, appearance, reappearance, and occlusion via a single Bayesian recursion. However, in practice, existing numerical approximations cause reappearing objects to be initialized as new tracks, especially after long periods of being undetected. In occlusion handling, the filter's efficacy is dictated by trade-offs between the sophistication of the occlusion model and computational demand. Our contribution is a novel modeling method that exploits object features to address reappearing objects whilst maintaining a linear complexity in the number of detections. Moreover, to improve the filter's occlusion handling, we propose a fuzzy detection model that takes into consideration the overlapping areas between tracks and their sizes. We also develop a fast version of the filter to further reduce the computational time.