 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChernoff fusion of Bernoulli Gaussian max filters
Oct 30, 2024Statistical dependencies between information sources are rarely known, yet in practical distributed tracking schemes, they must be taken into account in order to prevent track divergences. Chernoff fusion is well-known and universally accepted method that can address the problem of track fusion when the statistical dependence between the fusing sources is unknown. In this paper we derive the exact Chernoff fusion equations for Bernoulli Gaussian max filters. These filters have been recently derived in the framework of possibility theory, as the analog of the Bernoulli Gaussian sum filters. The main motivation for the possibilistic approach is that it effectively deals with imprecise mathematical models (e.g. dynamics, measurements) used in tracking algorithms. The paper also demonstrates the proposed possibilistic fusion scheme in the absence of knowledge about statistical dependence.
Visual Multi-Object Tracking with Re-Identification and Occlusion Handling using Labeled Random Finite Sets
Jul 11, 2024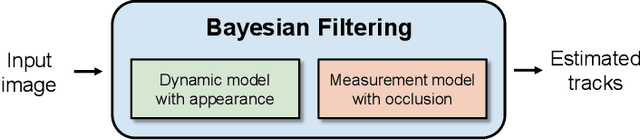


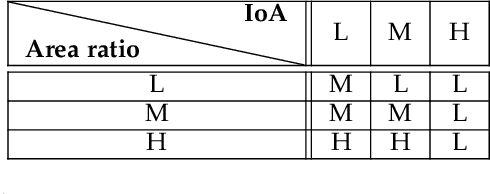
This paper proposes an online visual multi-object tracking (MOT) algorithm that resolves object appearance-reappearance and occlusion. Our solution is based on the labeled random finite set (LRFS) filtering approach, which in principle, addresses disappearance, appearance, reappearance, and occlusion via a single Bayesian recursion. However, in practice, existing numerical approximations cause reappearing objects to be initialized as new tracks, especially after long periods of being undetected. In occlusion handling, the filter's efficacy is dictated by trade-offs between the sophistication of the occlusion model and computational demand. Our contribution is a novel modeling method that exploits object features to address reappearing objects whilst maintaining a linear complexity in the number of detections. Moreover, to improve the filter's occlusion handling, we propose a fuzzy detection model that takes into consideration the overlapping areas between tracks and their sizes. We also develop a fast version of the filter to further reduce the computational time.
GCCN: Global Context Convolutional Network
Oct 22, 2021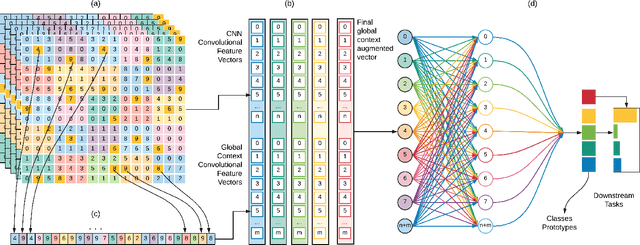
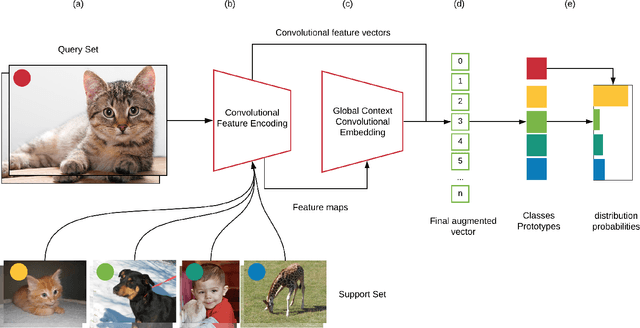
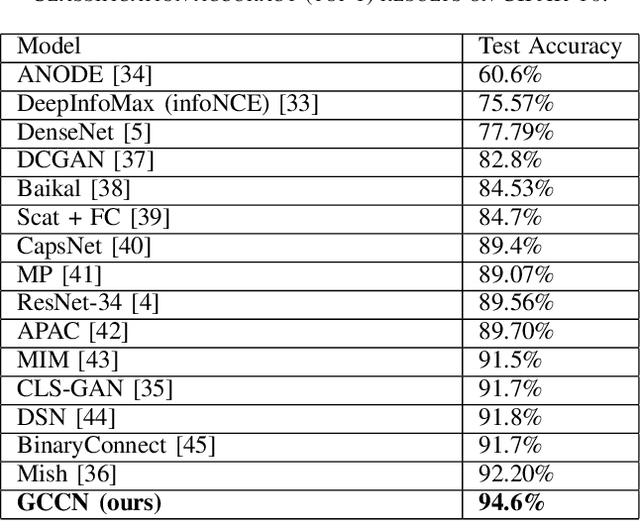
In this paper, we propose Global Context Convolutional Network (GCCN) for visual recognition. GCCN computes global features representing contextual information across image patches. These global contextual features are defined as local maxima pixels with high visual sharpness in each patch. These features are then concatenated and utilised to augment the convolutional features. The learnt feature vector is normalised using the global context features using Frobenius norm. This straightforward approach achieves high accuracy in compassion to the state-of-the-art methods with 94.6% and 95.41% on CIFAR-10 and STL-10 datasets, respectively. To explore potential impact of GCCN on other visual representation tasks, we implemented GCCN as a based model to few-shot image classification. We learn metric distances between the augmented feature vectors and their prototypes representations, similar to Prototypical and Matching Networks. GCCN outperforms state-of-the-art few-shot learning methods achieving 99.9%, 84.8% and 80.74% on Omniglot, MiniImageNet and CUB-200, respectively. GCCN has significantly improved on the accuracy of state-of-the-art prototypical and matching networks by up to 30% in different few-shot learning scenarios.
Signature-Graph Networks
Oct 22, 2021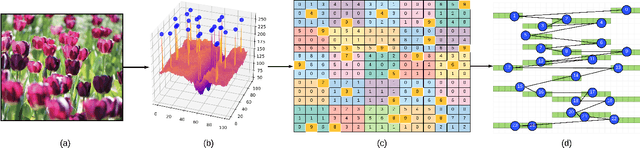
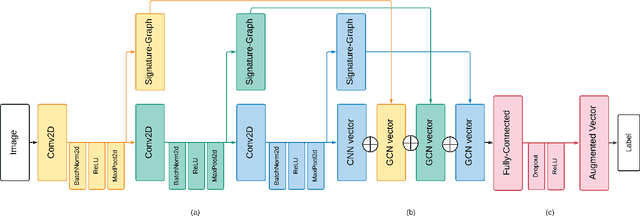
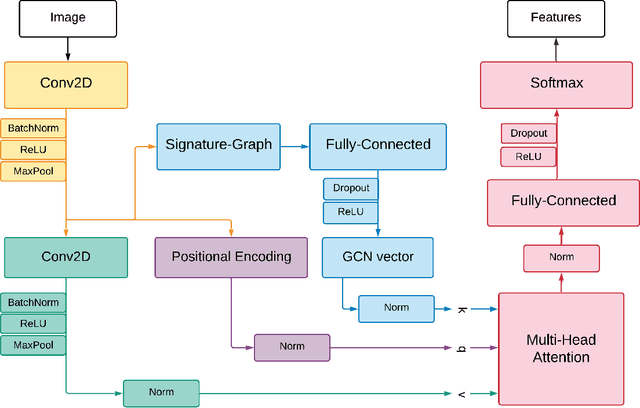
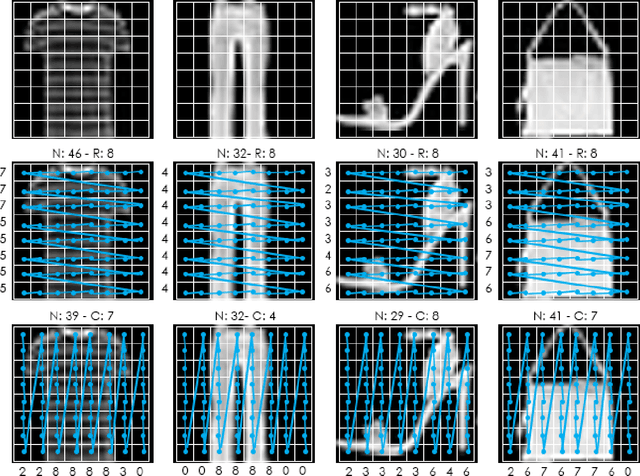
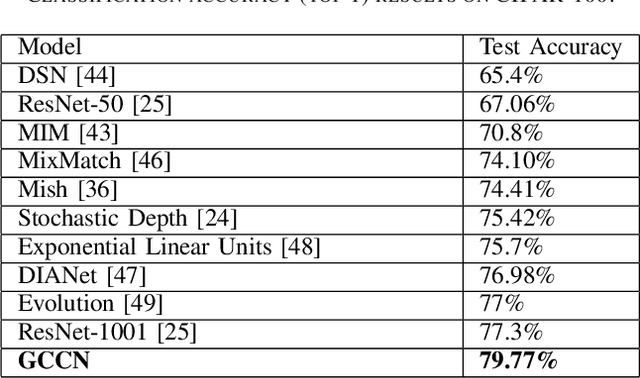
We propose a novel approach for visual representation learning called Signature-Graph Neural Networks (SGN). SGN learns latent global structures that augment the feature representation of Convolutional Neural Networks (CNN). SGN constructs unique undirected graphs for each image based on the CNN feature maps. The feature maps are partitioned into a set of equal and non-overlapping patches. The graph nodes are located on high-contrast sharp convolution features with the local maxima or minima in these patches. The node embeddings are aggregated through novel Signature-Graphs based on horizontal and vertical edge connections. The representation vectors are then computed based on the spectral Laplacian eigenvalues of the graphs. SGN outperforms existing methods of recent graph convolutional networks, generative adversarial networks, and auto-encoders with image classification accuracy of 99.65% on ASIRRA, 99.91% on MNIST, 98.55% on Fashion-MNIST, 96.18% on CIFAR-10, 84.71% on CIFAR-100, 94.36% on STL10, and 95.86% on SVHN datasets. We also introduce a novel implementation of the state-of-the-art multi-head attention (MHA) on top of the proposed SGN. Adding SGN to MHA improved the image classification accuracy from 86.92% to 94.36% on the STL10 dataset
Tracking Cells and their Lineages via Labeled Random Finite Sets
Apr 22, 2021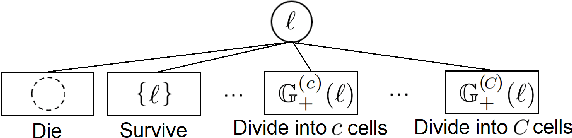
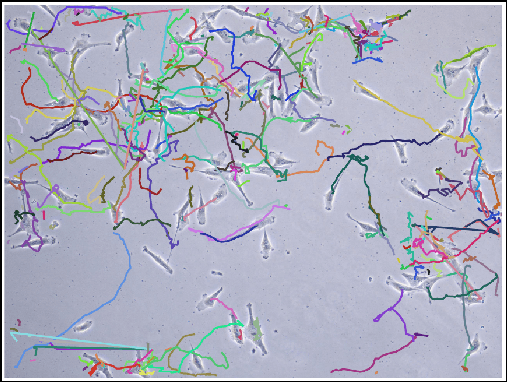
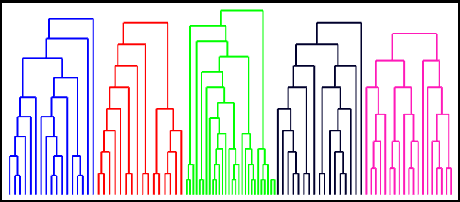
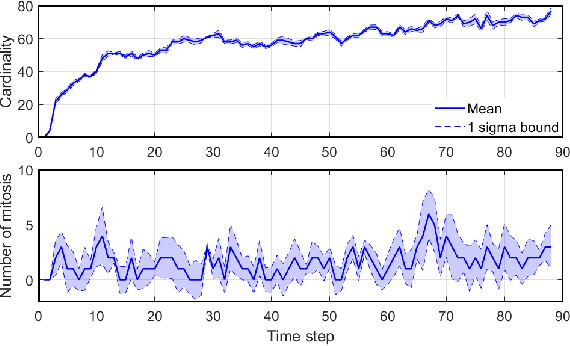
Determining the trajectories of cells and their lineages or ancestries in live-cell experiments are fundamental to the understanding of how cells behave and divide. This paper proposes novel online algorithms for jointly tracking and resolving lineages of an unknown and time-varying number of cells from time-lapse video data. Our approach involves modeling the cell ensemble as a labeled random finite set with labels representing cell identities and lineages. A spawning model is developed to take into account cell lineages and changes in cell appearance prior to division. We then derive analytic filters to propagate multi-object distributions that contain information on the current cell ensemble including their lineages. We also develop numerical implementations of the resulting multi-object filters. Experiments using simulation, synthetic cell migration video, and real time-lapse sequence, are presented to demonstrate the capability of the solutions.
Drone-as-a-Service Composition Under Uncertainty
Mar 11, 2021
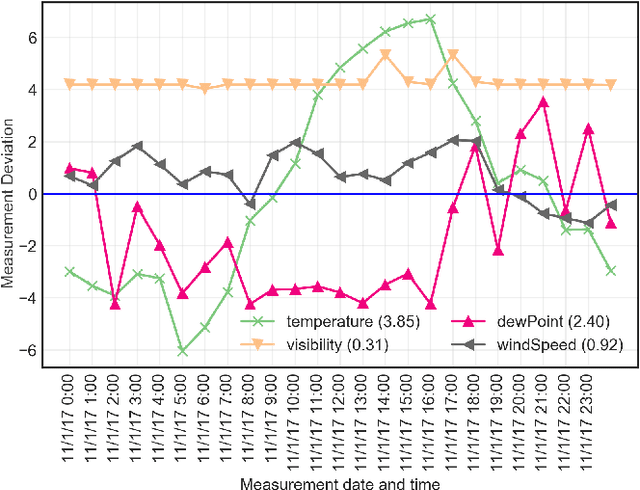
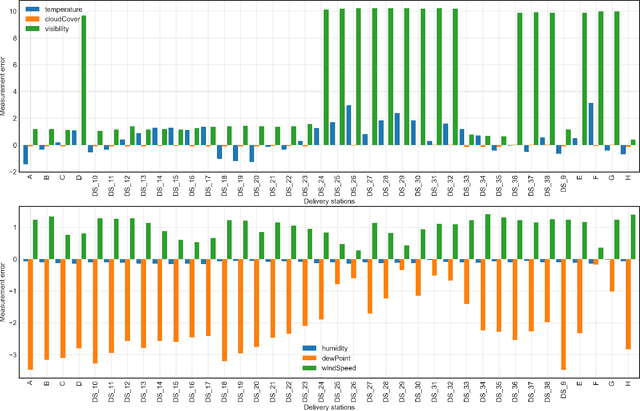
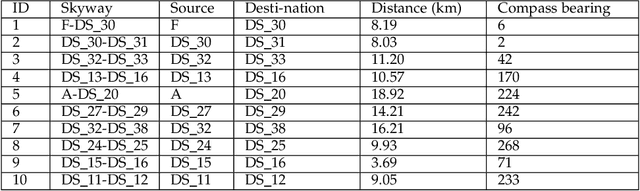
We propose an uncertainty-aware service approach to provide drone-based delivery services called Drone-as-a-Service (DaaS) effectively. Specifically, we propose a service model of DaaS based on the dynamic spatiotemporal features of drones and their in-flight contexts. The proposed DaaS service approach consists of three components: scheduling, route-planning, and composition. First, we develop a DaaS scheduling model to generate DaaS itineraries through a Skyway network. Second, we propose an uncertainty-aware DaaS route-planning algorithm that selects the optimal Skyways under weather uncertainties. Third, we develop two DaaS composition techniques to select an optimal DaaS composition at each station of the planned route. A spatiotemporal DaaS composer first selects the optimal DaaSs based on their spatiotemporal availability and drone capabilities. A predictive DaaS composer then utilises the outcome of the first composer to enable fast and accurate DaaS composition using several Machine Learning classification methods. We train the classifiers using a new set of spatiotemporal features which are in addition to other DaaS QoS properties. Our experiments results show the effectiveness and efficiency of the proposed approach.
* 20 pages, 20 figures, Accepted for publication at IEEE Transactions on Services Computing
grid2vec: Learning Efficient Visual Representations via Flexible Grid-Graphs
Jul 31, 2020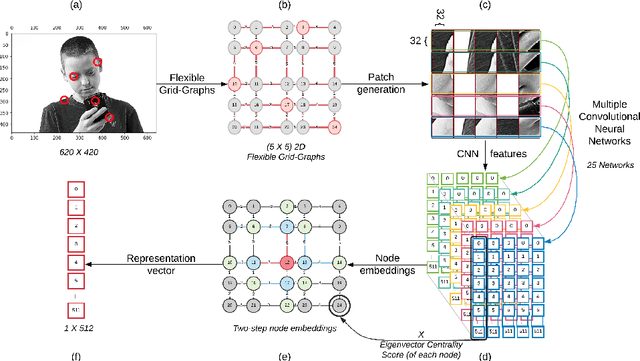
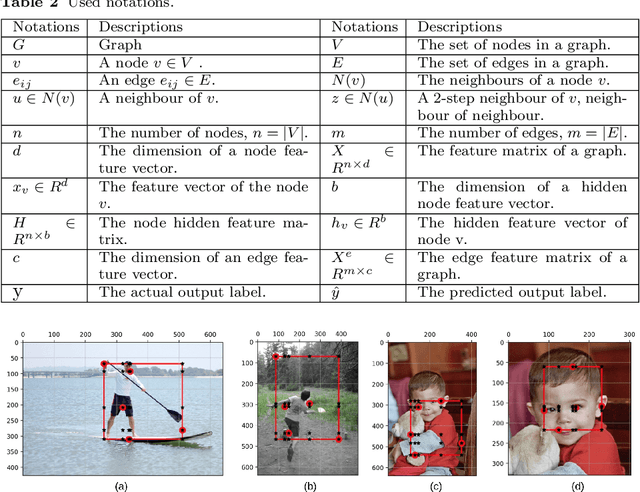

We propose $grid2vec$, a novel approach for image representation learning based on Graph Convolutional Network (GCN). Existing visual representation methods suffer from several issues, such as requiring high-computation, losing in-depth structures, and being restricted to specific objects. $grid2vec$ converts an image to a low-dimensional feature vector. A key component of $grid2vec$ is Flexible Grid-Graphs, a spatially-adaptive method based on the image key-points, as a flexible grid, to generate the graph representation. It represents each image with a graph of unique node locations and edge distances. Nodes, in Flexible Grid-Graphs, describe the most representative patches in the image. We develop a multi-channel Convolutional Neural Network architecture to learn local features of each patch. We implement a hybrid node-embedding method, i.e., having spectral and non-spectral components. It aggregates the products of neighbours' features and node's eigenvector centrality score. We compare the performance of $grid2vec$ with a set of state-of-the-art representation learning and visual recognition models. $grid2vec$ has only $512$ features in comparison to a range from VGG16 with $25,090$ to NASNet with $487,874$. We show the models' superior accuracy in both binary and multi-class image classification. Although we utilise imbalanced, low-size dataset, $grid2vec$ shows stable and superior results against the well-known base classifiers.
DroTrack: High-speed Drone-based Object Tracking Under Uncertainty
May 02, 2020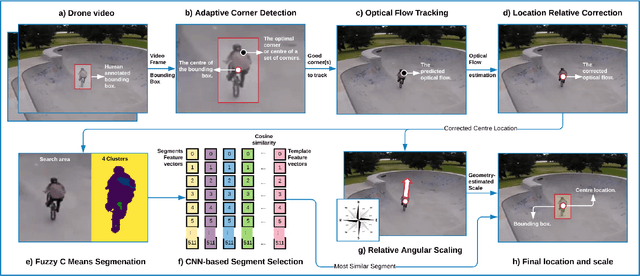
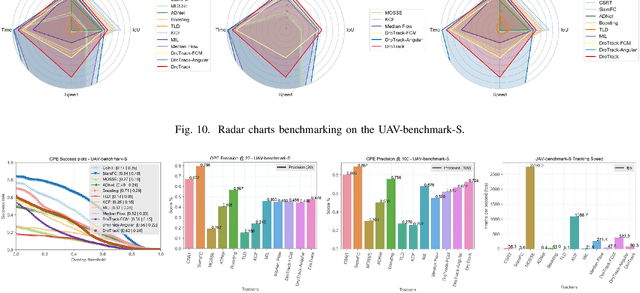

We present DroTrack, a high-speed visual single-object tracking framework for drone-captured video sequences. Most of the existing object tracking methods are designed to tackle well-known challenges, such as occlusion and cluttered backgrounds. The complex motion of drones, i.e., multiple degrees of freedom in three-dimensional space, causes high uncertainty. The uncertainty problem leads to inaccurate location predictions and fuzziness in scale estimations. DroTrack solves such issues by discovering the dependency between object representation and motion geometry. We implement an effective object segmentation based on Fuzzy C Means (FCM). We incorporate the spatial information into the membership function to cluster the most discriminative segments. We then enhance the object segmentation by using a pre-trained Convolution Neural Network (CNN) model. DroTrack also leverages the geometrical angular motion to estimate a reliable object scale. We discuss the experimental results and performance evaluation using two datasets of 51,462 drone-captured frames. The combination of the FCM segmentation and the angular scaling increased DroTrack precision by up to $9\%$ and decreased the centre location error by $162$ pixels on average. DroTrack outperforms all the high-speed trackers and achieves comparable results in comparison to deep learning trackers. DroTrack offers high frame rates up to 1000 frame per second (fps) with the best location precision, more than a set of state-of-the-art real-time trackers.
A Bayesian 3D Multi-view Multi-object Tracking Filter
Jan 13, 2020
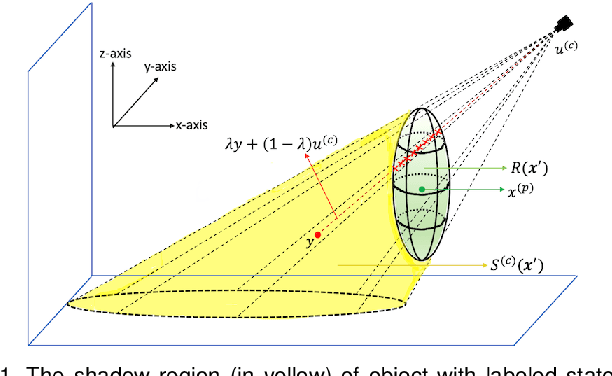
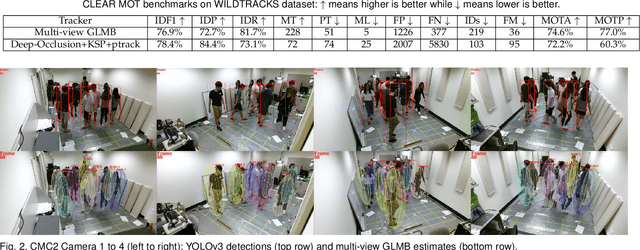

This paper proposes an online multi-camera multi-object tracker that only requires monocular detector training, independent of the multi-camera configurations, allowing seamless extension/deletion of cameras without (retraining) effort. The proposed algorithm has a linear complexity in the total number of detections across the cameras, and hence scales gracefully with the number of cameras. It operates in 3D world frame, and provides 3D trajectory estimates of the objects. The key innovation is a high fidelity yet tractable 3D occlusion model, amenable to optimal Bayesian multi-view multi-object filtering, which seamlessly integrates, into a single Bayesian recursion, the sub-tasks of track management, state estimation, clutter rejection, and occlusion/misdetection handling. The proposed algorithm is evaluated on the latest WILDTRACKS dataset, and demonstrated to work in very crowded scenes on a new dataset.
Online Multiple Pedestrian Tracking using Deep Temporal Appearance Matching Association
Jul 01, 2019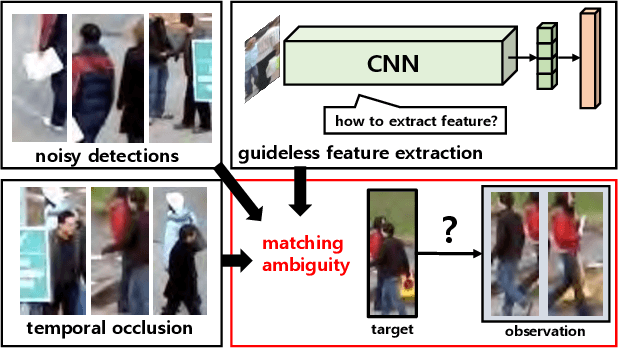
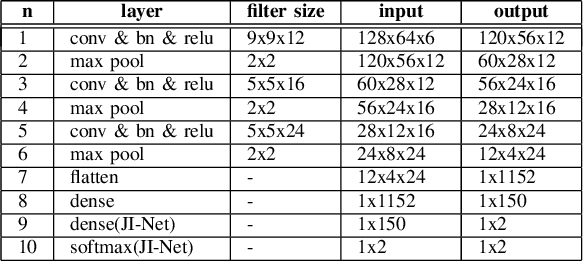
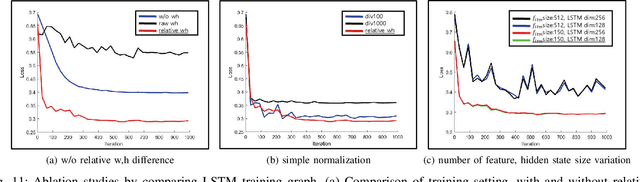
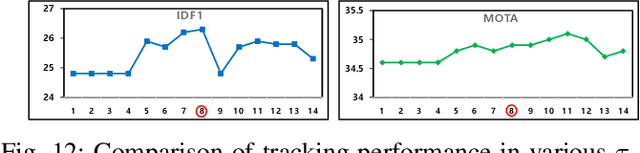
In online multiple pedestrian tracking it is of great importance to construct reliable cost matrix for assigning observations to tracks. Each element of cost matrix is constructed by using similarity measure. Many previous works have proposed their own similarity calculation methods consisting of geometric model (e.g. bounding box coordinates) and appearance model. In particular, appearance model contains information with higher dimension compared to geometric model. Thanks to the recent success of deep learning based methods, handling of high dimensional appearance information becomes possible. Among many deep networks, a siamese network with triplet loss is popularly adopted as an appearance feature extractor. Since the siamese network can extract features of each input independently, it is possible to adaptively model tracks (e.g. linear update). However, it is not suitable for multi-object setting that requires comparison with other inputs. In this paper we propose a novel track appearance modeling based on joint inference network to address this issue. The proposed method enables comparison of two inputs to be used for adaptive appearance modeling. It contributes to disambiguating target-observation matching and consolidating the identity consistency. Intensive experimental results support effectiveness of our method.