 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgegrid2vec: Learning Efficient Visual Representations via Flexible Grid-Graphs
Paper and Code
Jul 31, 2020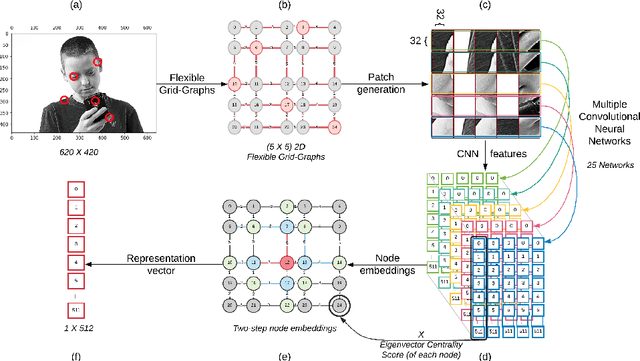
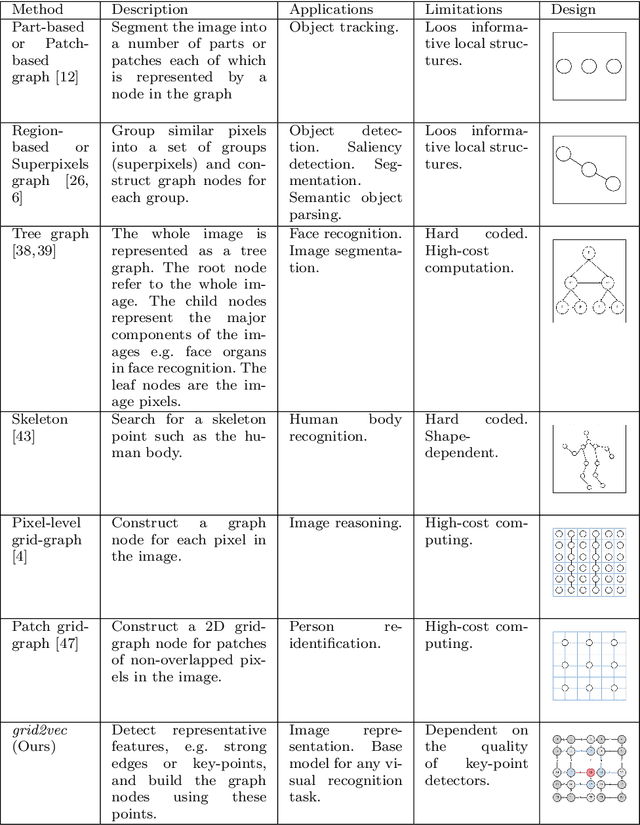
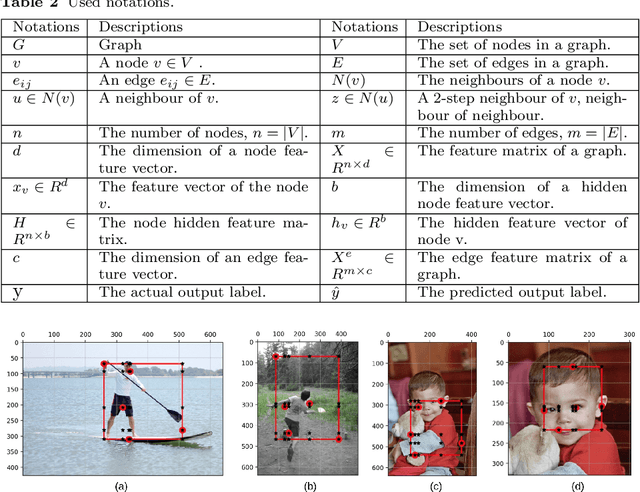

We propose $grid2vec$, a novel approach for image representation learning based on Graph Convolutional Network (GCN). Existing visual representation methods suffer from several issues, such as requiring high-computation, losing in-depth structures, and being restricted to specific objects. $grid2vec$ converts an image to a low-dimensional feature vector. A key component of $grid2vec$ is Flexible Grid-Graphs, a spatially-adaptive method based on the image key-points, as a flexible grid, to generate the graph representation. It represents each image with a graph of unique node locations and edge distances. Nodes, in Flexible Grid-Graphs, describe the most representative patches in the image. We develop a multi-channel Convolutional Neural Network architecture to learn local features of each patch. We implement a hybrid node-embedding method, i.e., having spectral and non-spectral components. It aggregates the products of neighbours' features and node's eigenvector centrality score. We compare the performance of $grid2vec$ with a set of state-of-the-art representation learning and visual recognition models. $grid2vec$ has only $512$ features in comparison to a range from VGG16 with $25,090$ to NASNet with $487,874$. We show the models' superior accuracy in both binary and multi-class image classification. Although we utilise imbalanced, low-size dataset, $grid2vec$ shows stable and superior results against the well-known base classifiers.