 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Tricks for Domain Adaptive Multi-Object Tracking
May 31, 2022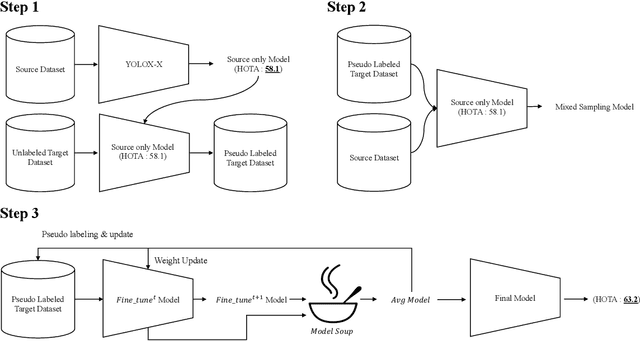
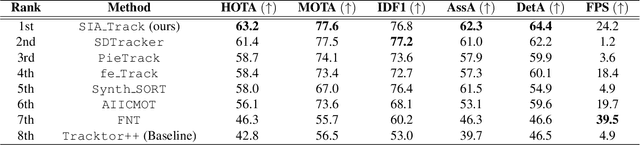

In this paper, SIA_Track is presented which is developed by a research team from SI Analytics. The proposed method was built from pre-existing detector and tracker under the tracking-by-detection paradigm. The tracker we used is an online tracker that merely links newly received detections with existing tracks. The core part of our method is training procedure of the object detector where synthetic and unlabeled real data were only used for training. To maximize the performance on real data, we first propose to use pseudo-labeling that generates imperfect labels for real data using a model trained with synthetic dataset. After that model soups scheme was applied to aggregate weights produced during iterative pseudo-labeling. Besides, cross-domain mixed sampling also helped to increase detection performance on real data. Our method, SIA_Track, takes the first place on MOTSynth2MOT17 track at BMTT 2022 challenge. The code is available on https://github.com/SIAnalytics/BMTT2022_SIA_track.
Learning Multiple Probabilistic Degradation Generators for Unsupervised Real World Image Super Resolution
Jan 26, 2022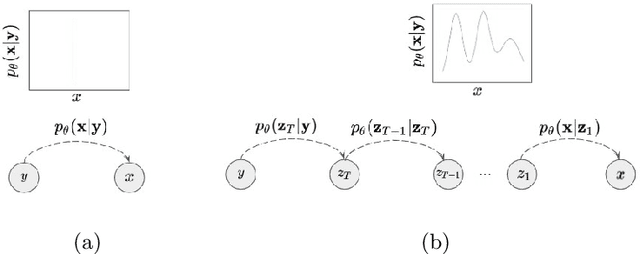

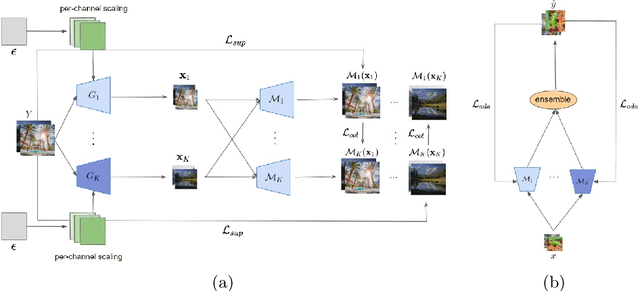

Unsupervised real world super resolution (USR) aims at restoring high-resolution (HR) images given low-resolution (LR) inputs when paired data is unavailable. One of the most common approaches is synthesizing noisy LR images using GANs and utilizing a synthetic dataset to train the model in a supervised manner. The goal of modeling the degradation generator is to approximate the distribution of LR images given a HR image. Previous works simply assumed the conditional distribution as a delta function and learned the deterministic mapping from HR image to a LR image. Instead, we propose the probabilistic degradation generator. Our degradation generator is a deep hierarchical latent variable model and more suitable for modeling the complex distribution. Furthermore, we train multiple degradation generators to enhance the mode coverage and apply the novel collaborative learning. We outperform several baselines on benchmark datasets in terms of PSNR and SSIM and demonstrate the robustness of our method on unseen data distribution.
An End-to-End Trainable Video Panoptic Segmentation Method usingTransformers
Oct 08, 2021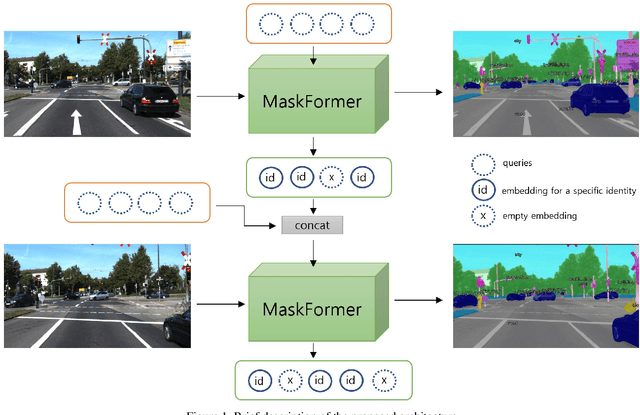



In this paper, we present an algorithm to tackle a video panoptic segmentation problem, a newly emerging area of research. The video panoptic segmentation is a task that unifies the typical task of panoptic segmentation and multi-object tracking. In other words, it requires generating the instance tracking IDs along with panoptic segmentation results across video sequences. Our proposed video panoptic segmentation algorithm uses the transformer and it can be trained in end-to-end with an input of multiple video frames. We test our method on the STEP dataset and report its performance with recently proposed STQ metric. The method archived 57.81\% on the KITTI-STEP dataset and 31.8\% on the MOTChallenge-STEP dataset.
Simple and Efficient Unpaired Real-world Super-Resolution using Image Statistics
Sep 19, 2021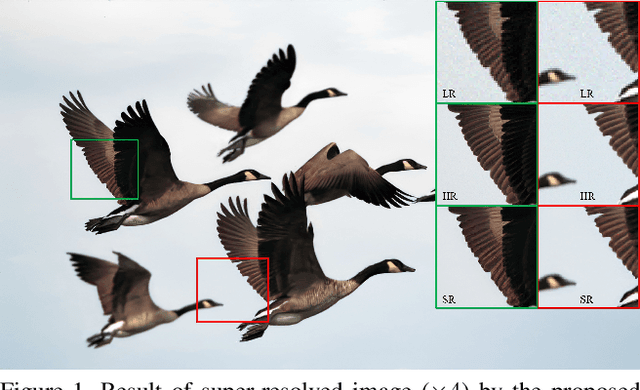
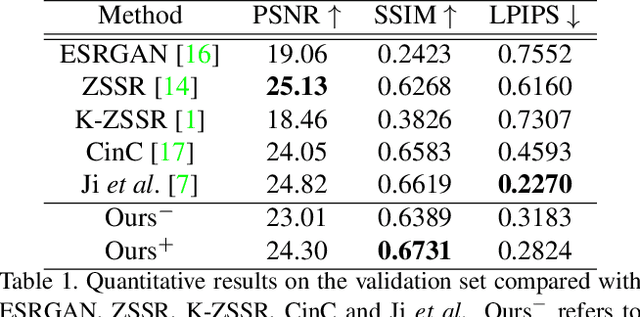
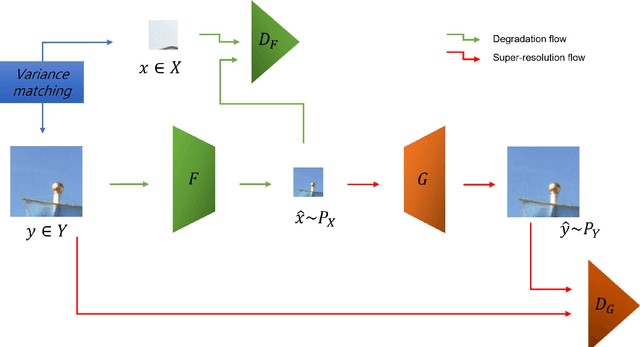
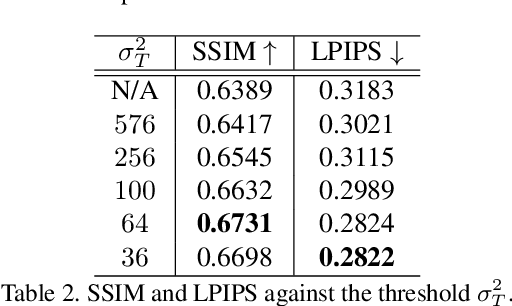
Learning super-resolution (SR) network without the paired low resolution (LR) and high resolution (HR) image is difficult because direct supervision through the corresponding HR counterpart is unavailable. Recently, many real-world SR researches take advantage of the unpaired image-to-image translation technique. That is, they used two or more generative adversarial networks (GANs), each of which translates images from one domain to another domain, \eg, translates images from the HR domain to the LR domain. However, it is not easy to stably learn such a translation with GANs using unpaired data. In this study, we present a simple and efficient method of training of real-world SR network. To stably train the network, we use statistics of an image patch, such as means and variances. Our real-world SR framework consists of two GANs, one for translating HR images to LR images (degradation task) and the other for translating LR to HR (SR task). We argue that the unpaired image translation using GANs can be learned efficiently with our proposed data sampling strategy, namely, variance matching. We test our method on the NTIRE 2020 real-world SR dataset. Our method outperforms the current state-of-the-art method in terms of the SSIM metric as well as produces comparable results on the LPIPS metric.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
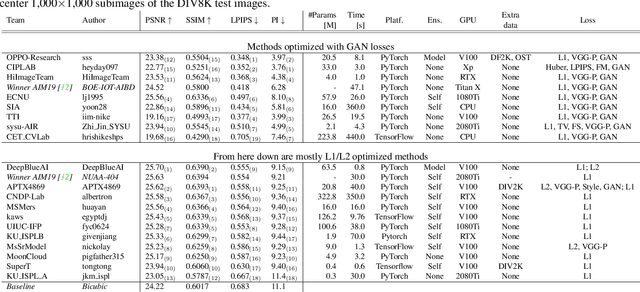

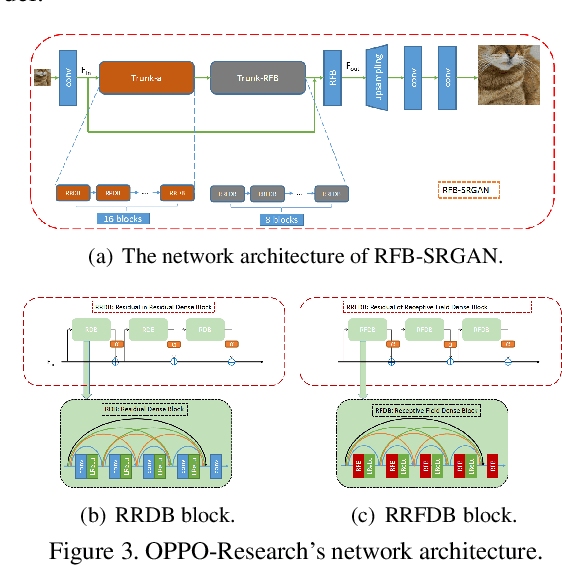
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Online Multi-Object Tracking Framework with the GMPHD Filter and Occlusion Group Management
Jul 31, 2019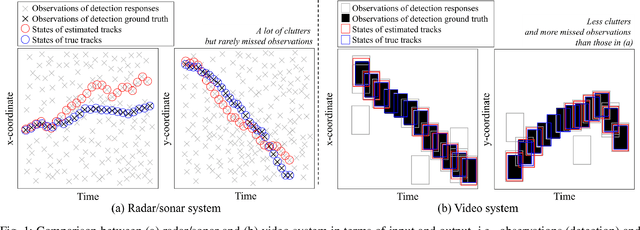
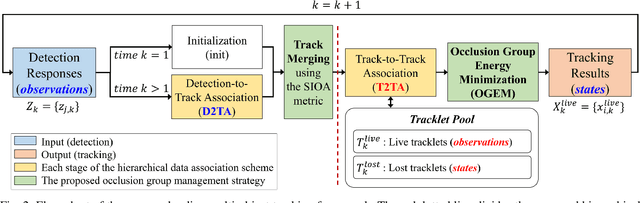


In this paper, we propose an efficient online multi-object tracking framework based on the GMPHD filter and occlusion group management scheme where the GMPHD filter utilizes hierarchical data association to reduce the false negatives caused by miss detection. The hierarchical data association consists of two steps: detection-to-track and track-to-track associations, which can recover the lost tracks and their switched IDs. In addition, the proposed framework is equipped with an object grouping management scheme which handles occlusion problems with two main parts. The first part is "track merging" which can merge the false positive tracks caused by false positive detections from occlusions, where the false positive tracks are usually occluded with a measure. The measure is the occlusion ratio between visual objects, sum-of-intersection-over-area (SIOA) we defined instead of the IOU metric. The second part is "occlusion group energy minimization (OGEM)" which prevents the occluded true positive tracks from false "track merging". We define each group of the occluded objects as an energy function and find an optimal hypothesis which makes the energy minimal. We evaluate the proposed tracker in benchmark datasets such as MOT15 and MOT17 which are built for multi-person tracking. An ablation study in training dataset shows that not only "track merging" and "OGEM" complement each other but also the proposed tracking method has more robust performance and less sensitive to parameters than baseline methods. Also, SIOA works better than IOU for various sizes of false positives. Experimental results show that the proposed tracker efficiently handles occlusion situations and achieves competitive performance compared to the state-of-the-art methods. Especially, our method shows the best multi-object tracking accuracy among the online and real-time executable methods.
Online Multiple Pedestrian Tracking using Deep Temporal Appearance Matching Association
Jul 01, 2019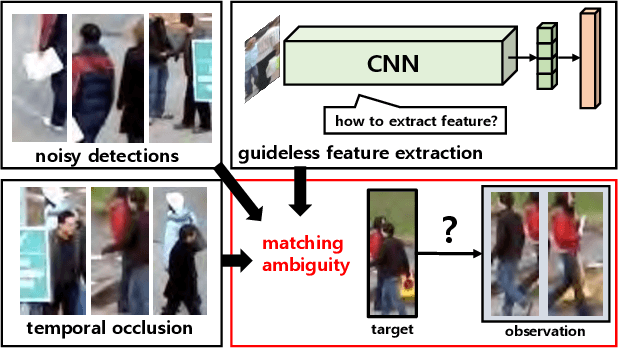
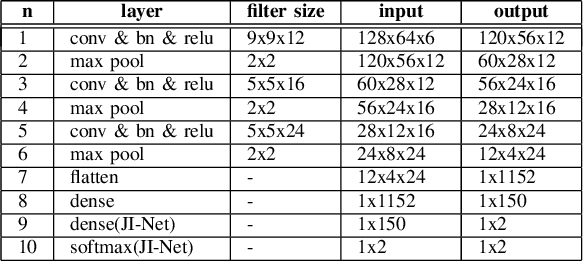
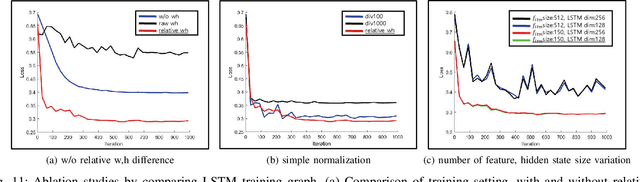
In online multiple pedestrian tracking it is of great importance to construct reliable cost matrix for assigning observations to tracks. Each element of cost matrix is constructed by using similarity measure. Many previous works have proposed their own similarity calculation methods consisting of geometric model (e.g. bounding box coordinates) and appearance model. In particular, appearance model contains information with higher dimension compared to geometric model. Thanks to the recent success of deep learning based methods, handling of high dimensional appearance information becomes possible. Among many deep networks, a siamese network with triplet loss is popularly adopted as an appearance feature extractor. Since the siamese network can extract features of each input independently, it is possible to adaptively model tracks (e.g. linear update). However, it is not suitable for multi-object setting that requires comparison with other inputs. In this paper we propose a novel track appearance modeling based on joint inference network to address this issue. The proposed method enables comparison of two inputs to be used for adaptive appearance modeling. It contributes to disambiguating target-observation matching and consolidating the identity consistency. Intensive experimental results support effectiveness of our method.
Multiple Hypothesis Tracking Algorithm for Multi-Target Multi-Camera Tracking with Disjoint Views
Jan 25, 2019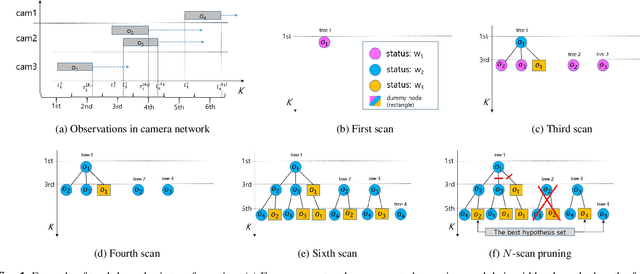
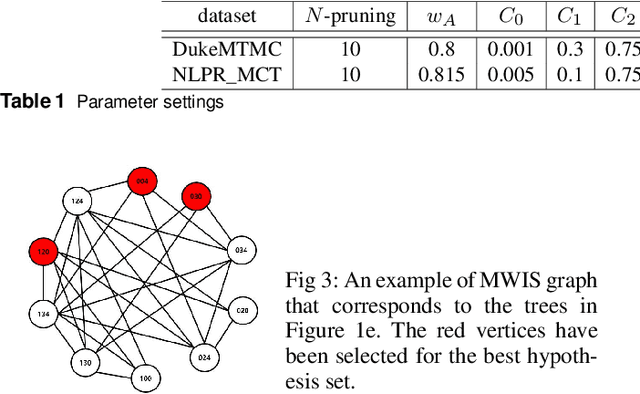
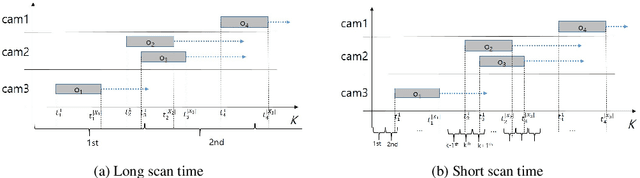
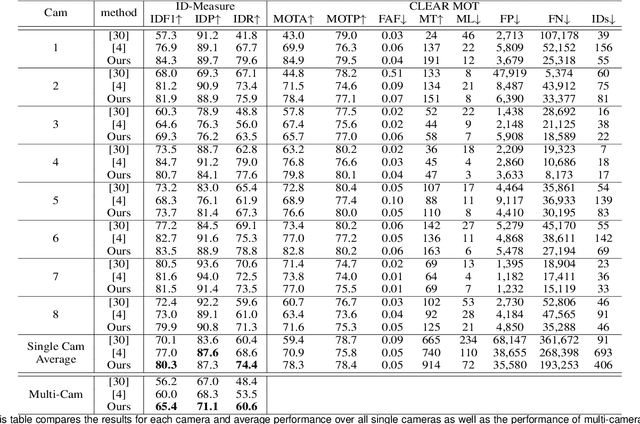
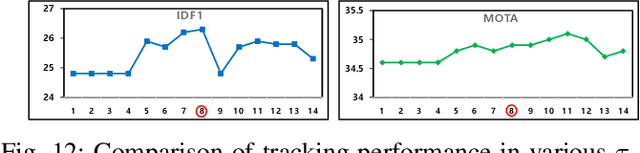
In this study, a multiple hypothesis tracking (MHT) algorithm for multi-target multi-camera tracking (MCT) with disjoint views is proposed. Our method forms track-hypothesis trees, and each branch of them represents a multi-camera track of a target that may move within a camera as well as move across cameras. Furthermore, multi-target tracking within a camera is performed simultaneously with the tree formation by manipulating a status of each track hypothesis. Each status represents three different stages of a multi-camera track: tracking, searching, and end-of-track. The tracking status means targets are tracked by a single camera tracker. In the searching status, the disappeared targets are examined if they reappear in other cameras. The end-of-track status does the target exited the camera network due to its lengthy invisibility. These three status assists MHT to form the track-hypothesis trees for multi-camera tracking. Furthermore, they present a gating technique for eliminating of unlikely observation-to-track association. In the experiments, they evaluate the proposed method using two datasets, DukeMTMC and NLPR-MCT, which demonstrates that the proposed method outperforms the state-of-the-art method in terms of improvement of the accuracy. In addition, they show that the proposed method can operate in real-time and online.
* published in IET image processing, 2018
Online Multi-Object Tracking with Historical Appearance Matching and Scene Adaptive Detection Filtering
Sep 18, 2018
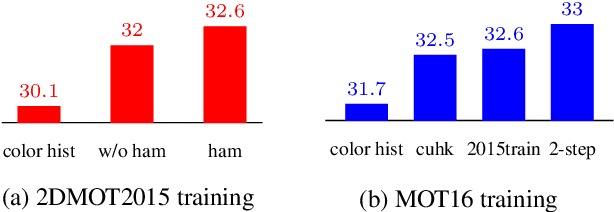
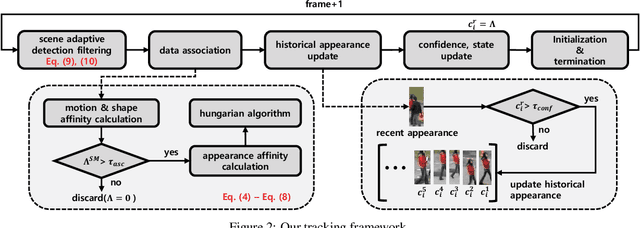
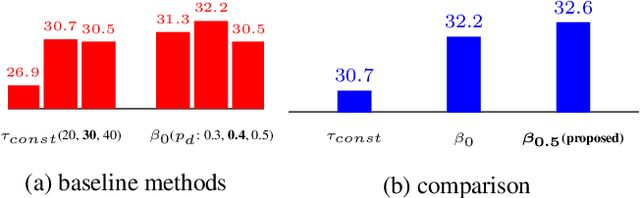
In this paper, we propose the methods to handle temporal errors during multi-object tracking. Temporal error occurs when objects are occluded or noisy detections appear near the object. In those situations, tracking may fail and various errors like drift or ID-switching occur. It is hard to overcome temporal errors only by using motion and shape information. So, we propose the historical appearance matching method and joint-input siamese network which was trained by 2-step process. It can prevent tracking failures although objects are temporally occluded or last matching information is unreliable. We also provide useful technique to remove noisy detections effectively according to scene condition. Tracking performance, especially identity consistency, is highly improved by attaching our methods.