 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaNEL: Exploration Posteriors for Generative Modeling Using Only Negative Rewards
Oct 10, 2025Today's generative models thrive with large amounts of supervised data and informative reward functions characterizing the quality of the generation. They work under the assumptions that the supervised data provides knowledge to pre-train the model, and the reward function provides dense information about how to further improve the generation quality and correctness. However, in the hardest instances of important problems, two problems arise: (1) the base generative model attains a near-zero reward signal, and (2) calls to the reward oracle are expensive. This setting poses a fundamentally different learning challenge than standard reward-based post-training. To address this, we propose BaNEL (Bayesian Negative Evidence Learning), an algorithm that post-trains the model using failed attempts only, while minimizing the number of reward evaluations (NREs). Our method is based on the idea that the problem of learning regularities underlying failures can be cast as another, in-loop generative modeling problem. We then leverage this model to assess whether new data resembles previously seen failures and steer the generation away from them. We show that BaNEL can improve model performance without observing a single successful sample on several sparse-reward tasks, outperforming existing novelty-bonus approaches by up to several orders of magnitude in success rate, while using fewer reward evaluations.
Truncated Consistency Models
Oct 18, 2024



Consistency models have recently been introduced to accelerate sampling from diffusion models by directly predicting the solution (i.e., data) of the probability flow ODE (PF ODE) from initial noise. However, the training of consistency models requires learning to map all intermediate points along PF ODE trajectories to their corresponding endpoints. This task is much more challenging than the ultimate objective of one-step generation, which only concerns the PF ODE's noise-to-data mapping. We empirically find that this training paradigm limits the one-step generation performance of consistency models. To address this issue, we generalize consistency training to the truncated time range, which allows the model to ignore denoising tasks at earlier time steps and focus its capacity on generation. We propose a new parameterization of the consistency function and a two-stage training procedure that prevents the truncated-time training from collapsing to a trivial solution. Experiments on CIFAR-10 and ImageNet $64\times64$ datasets show that our method achieves better one-step and two-step FIDs than the state-of-the-art consistency models such as iCT-deep, using more than 2$\times$ smaller networks. Project page: https://truncated-cm.github.io/
Improving the Training of Rectified Flows
May 30, 2024Diffusion models have shown great promise for image and video generation, but sampling from state-of-the-art models requires expensive numerical integration of a generative ODE. One approach for tackling this problem is rectified flows, which iteratively learn smooth ODE paths that are less susceptible to truncation error. However, rectified flows still require a relatively large number of function evaluations (NFEs). In this work, we propose improved techniques for training rectified flows, allowing them to compete with knowledge distillation methods even in the low NFE setting. Our main insight is that under realistic settings, a single iteration of the Reflow algorithm for training rectified flows is sufficient to learn nearly straight trajectories; hence, the current practice of using multiple Reflow iterations is unnecessary. We thus propose techniques to improve one-round training of rectified flows, including a U-shaped timestep distribution and LPIPS-Huber premetric. With these techniques, we improve the FID of the previous 2-rectified flow by up to 72% in the 1 NFE setting on CIFAR-10. On ImageNet 64$\times$64, our improved rectified flow outperforms the state-of-the-art distillation methods such as consistency distillation and progressive distillation in both one-step and two-step settings and rivals the performance of improved consistency training (iCT) in FID. Code is available at https://github.com/sangyun884/rfpp.
Can LLMs Produce Faithful Explanations For Fact-checking? Towards Faithful Explainable Fact-Checking via Multi-Agent Debate
Feb 12, 2024



Fact-checking research has extensively explored verification but less so the generation of natural-language explanations, crucial for user trust. While Large Language Models (LLMs) excel in text generation, their capability for producing faithful explanations in fact-checking remains underexamined. Our study investigates LLMs' ability to generate such explanations, finding that zero-shot prompts often result in unfaithfulness. To address these challenges, we propose the Multi-Agent Debate Refinement (MADR) framework, leveraging multiple LLMs as agents with diverse roles in an iterative refining process aimed at enhancing faithfulness in generated explanations. MADR ensures that the final explanation undergoes rigorous validation, significantly reducing the likelihood of unfaithful elements and aligning closely with the provided evidence. Experimental results demonstrate that MADR significantly improves the faithfulness of LLM-generated explanations to the evidence, advancing the credibility and trustworthiness of these explanations.
Sequential Data Generation with Groupwise Diffusion Process
Oct 02, 2023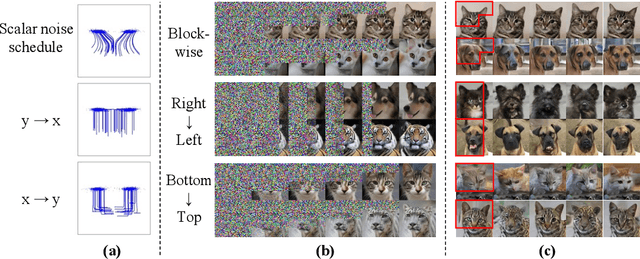



We present the Groupwise Diffusion Model (GDM), which divides data into multiple groups and diffuses one group at one time interval in the forward diffusion process. GDM generates data sequentially from one group at one time interval, leading to several interesting properties. First, as an extension of diffusion models, GDM generalizes certain forms of autoregressive models and cascaded diffusion models. As a unified framework, GDM allows us to investigate design choices that have been overlooked in previous works, such as data-grouping strategy and order of generation. Furthermore, since one group of the initial noise affects only a certain group of the generated data, latent space now possesses group-wise interpretable meaning. We can further extend GDM to the frequency domain where the forward process sequentially diffuses each group of frequency components. Dividing the frequency bands of the data as groups allows the latent variables to become a hierarchical representation where individual groups encode data at different levels of abstraction. We demonstrate several applications of such representation including disentanglement of semantic attributes, image editing, and generating variations.
Minimizing Trajectory Curvature of ODE-based Generative Models
Feb 05, 2023Recent ODE/SDE-based generative models, such as diffusion models, rectified flows, and flow matching, define a generative process as a time reversal of a fixed forward process. Even though these models show impressive performance on large-scale datasets, numerical simulation requires multiple evaluations of a neural network, leading to a slow sampling speed. We attribute the reason to the high curvature of the learned generative trajectories, as it is directly related to the truncation error of a numerical solver. Based on the relationship between the forward process and the curvature, here we present an efficient method of training the forward process to minimize the curvature of generative trajectories without any ODE/SDE simulation. Experiments show that our method achieves a lower curvature than previous models and, therefore, decreased sampling costs while maintaining competitive performance. Code is available at https://github.com/sangyun884/fast-ode.
Progressive Deblurring of Diffusion Models for Coarse-to-Fine Image Synthesis
Jul 16, 2022

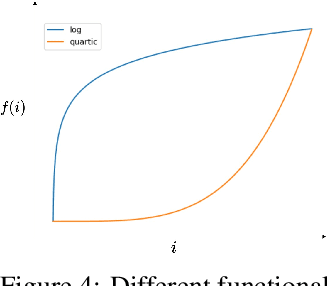
Recently, diffusion models have shown remarkable results in image synthesis by gradually removing noise and amplifying signals. Although the simple generative process surprisingly works well, is this the best way to generate image data? For instance, despite the fact that human perception is more sensitive to the low frequencies of an image, diffusion models themselves do not consider any relative importance of each frequency component. Therefore, to incorporate the inductive bias for image data, we propose a novel generative process that synthesizes images in a coarse-to-fine manner. First, we generalize the standard diffusion models by enabling diffusion in a rotated coordinate system with different velocities for each component of the vector. We further propose a blur diffusion as a special case, where each frequency component of an image is diffused at different speeds. Specifically, the proposed blur diffusion consists of a forward process that blurs an image and adds noise gradually, after which a corresponding reverse process deblurs an image and removes noise progressively. Experiments show that the proposed model outperforms the previous method in FID on LSUN bedroom and church datasets. Code is available at https://github.com/sangyun884/blur-diffusion.
High-Resolution Virtual Try-On with Misalignment and Occlusion-Handled Conditions
Jun 28, 2022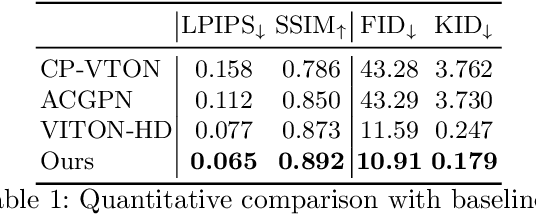
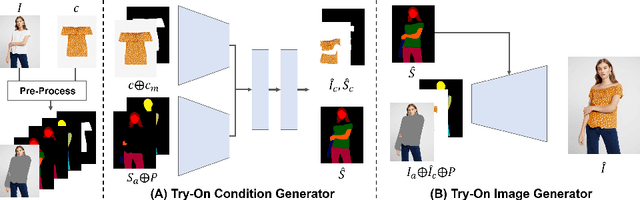
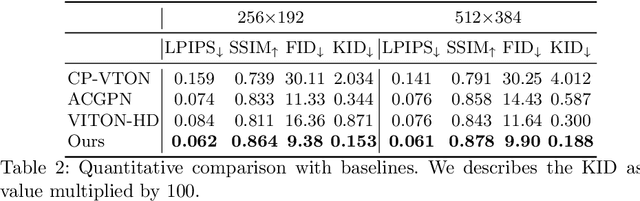
Image-based virtual try-on aims to synthesize an image of a person wearing a given clothing item. To solve the task, the existing methods warp the clothing item to fit the person's body and generate the segmentation map of the person wearing the item, before fusing the item with the person. However, when the warping and the segmentation generation stages operate individually without information exchange, the misalignment between the warped clothes and the segmentation map occurs, which leads to the artifacts in the final image. The information disconnection also causes excessive warping near the clothing regions occluded by the body parts, so called pixel-squeezing artifacts. To settle the issues, we propose a novel try-on condition generator as a unified module of the two stages (i.e., warping and segmentation generation stages). A newly proposed feature fusion block in the condition generator implements the information exchange, and the condition generator does not create any misalignment or pixel-squeezing artifacts. We also introduce discriminator rejection that filters out the incorrect segmentation map predictions and assures the performance of virtual try-on frameworks. Experiments on a high-resolution dataset demonstrate that our model successfully handles the misalignment and the occlusion, and significantly outperforms the baselines. Code is available at https://github.com/sangyun884/HR-VITON.
Learning Multiple Probabilistic Degradation Generators for Unsupervised Real World Image Super Resolution
Jan 26, 2022

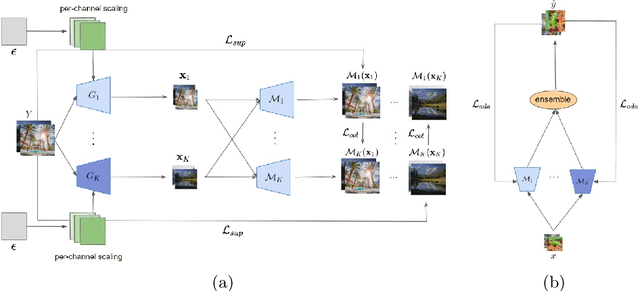

Unsupervised real world super resolution (USR) aims at restoring high-resolution (HR) images given low-resolution (LR) inputs when paired data is unavailable. One of the most common approaches is synthesizing noisy LR images using GANs and utilizing a synthetic dataset to train the model in a supervised manner. The goal of modeling the degradation generator is to approximate the distribution of LR images given a HR image. Previous works simply assumed the conditional distribution as a delta function and learned the deterministic mapping from HR image to a LR image. Instead, we propose the probabilistic degradation generator. Our degradation generator is a deep hierarchical latent variable model and more suitable for modeling the complex distribution. Furthermore, we train multiple degradation generators to enhance the mode coverage and apply the novel collaborative learning. We outperform several baselines on benchmark datasets in terms of PSNR and SSIM and demonstrate the robustness of our method on unseen data distribution.
Learning entropy production via neural networks
Mar 13, 2020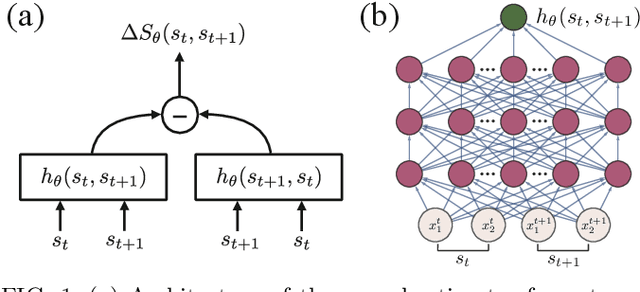
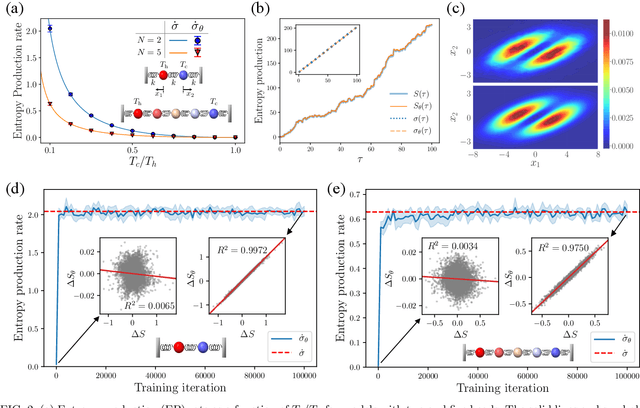
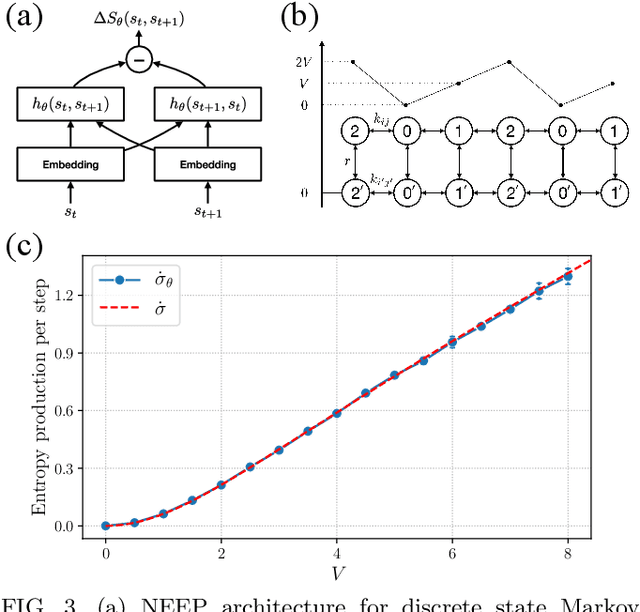
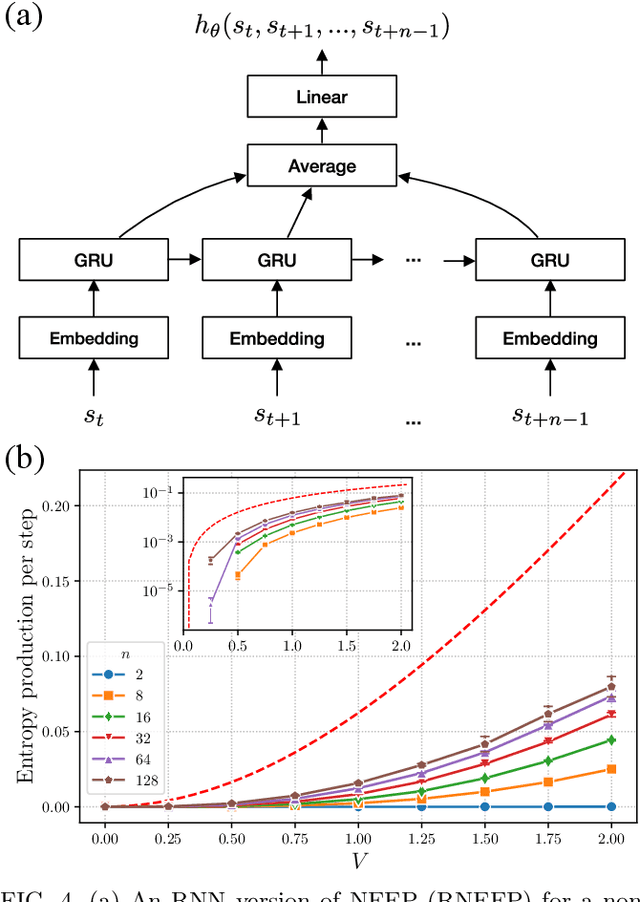
This Letter presents a neural estimator for entropy production, or NEEP, that estimates entropy production (EP) from trajectories without any prior knowledge of the system. For steady state, we rigorously prove that the estimator, which can be built up from different choices of deep neural networks, provides stochastic EP by optimizing the objective function proposed here. We verify the NEEP with the stochastic processes of the bead-spring and discrete flashing ratchet models, and also demonstrate that our method is applicable to high-dimensional data and non-Markovian systems.