 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMode Seeking meets Mean Seeking for Fast Long Video Generation
Feb 27, 2026Scaling video generation from seconds to minutes faces a critical bottleneck: while short-video data is abundant and high-fidelity, coherent long-form data is scarce and limited to narrow domains. To address this, we propose a training paradigm where Mode Seeking meets Mean Seeking, decoupling local fidelity from long-term coherence based on a unified representation via a Decoupled Diffusion Transformer. Our approach utilizes a global Flow Matching head trained via supervised learning on long videos to capture narrative structure, while simultaneously employing a local Distribution Matching head that aligns sliding windows to a frozen short-video teacher via a mode-seeking reverse-KL divergence. This strategy enables the synthesis of minute-scale videos that learns long-range coherence and motions from limited long videos via supervised flow matching, while inheriting local realism by aligning every sliding-window segment of the student to a frozen short-video teacher, resulting in a few-step fast long video generator. Evaluations show that our method effectively closes the fidelity-horizon gap by jointly improving local sharpness, motion and long-range consistency. Project website: https://primecai.github.io/mmm/.
OpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation
Jan 21, 2026This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling.
Transition Matching Distillation for Fast Video Generation
Jan 14, 2026Large video diffusion and flow models have achieved remarkable success in high-quality video generation, but their use in real-time interactive applications remains limited due to their inefficient multi-step sampling process. In this work, we present Transition Matching Distillation (TMD), a novel framework for distilling video diffusion models into efficient few-step generators. The central idea of TMD is to match the multi-step denoising trajectory of a diffusion model with a few-step probability transition process, where each transition is modeled as a lightweight conditional flow. To enable efficient distillation, we decompose the original diffusion backbone into two components: (1) a main backbone, comprising the majority of early layers, that extracts semantic representations at each outer transition step; and (2) a flow head, consisting of the last few layers, that leverages these representations to perform multiple inner flow updates. Given a pretrained video diffusion model, we first introduce a flow head to the model, and adapt it into a conditional flow map. We then apply distribution matching distillation to the student model with flow head rollout in each transition step. Extensive experiments on distilling Wan2.1 1.3B and 14B text-to-video models demonstrate that TMD provides a flexible and strong trade-off between generation speed and visual quality. In particular, TMD outperforms existing distilled models under comparable inference costs in terms of visual fidelity and prompt adherence. Project page: https://research.nvidia.com/labs/genair/tmd
Rethinking Molecule Synthesizability with Chain-of-Reaction
Sep 19, 2025A well-known pitfall of molecular generative models is that they are not guaranteed to generate synthesizable molecules. There have been considerable attempts to address this problem, but given the exponentially large combinatorial space of synthesizable molecules, existing methods have shown limited coverage of the space and poor molecular optimization performance. To tackle these problems, we introduce ReaSyn, a generative framework for synthesizable projection where the model explores the neighborhood of given molecules in the synthesizable space by generating pathways that result in synthesizable analogs. To fully utilize the chemical knowledge contained in the synthetic pathways, we propose a novel perspective that views synthetic pathways akin to reasoning paths in large language models (LLMs). Specifically, inspired by chain-of-thought (CoT) reasoning in LLMs, we introduce the chain-of-reaction (CoR) notation that explicitly states reactants, reaction types, and intermediate products for each step in a pathway. With the CoR notation, ReaSyn can get dense supervision in every reaction step to explicitly learn chemical reaction rules during supervised training and perform step-by-step reasoning. In addition, to further enhance the reasoning capability of ReaSyn, we propose reinforcement learning (RL)-based finetuning and goal-directed test-time compute scaling tailored for synthesizable projection. ReaSyn achieves the highest reconstruction rate and pathway diversity in synthesizable molecule reconstruction and the highest optimization performance in synthesizable goal-directed molecular optimization, and significantly outperforms previous synthesizable projection methods in synthesizable hit expansion. These results highlight ReaSyn's superior ability to navigate combinatorially-large synthesizable chemical space.
One-step Diffusion Models with $f$-Divergence Distribution Matching
Feb 21, 2025Sampling from diffusion models involves a slow iterative process that hinders their practical deployment, especially for interactive applications. To accelerate generation speed, recent approaches distill a multi-step diffusion model into a single-step student generator via variational score distillation, which matches the distribution of samples generated by the student to the teacher's distribution. However, these approaches use the reverse Kullback-Leibler (KL) divergence for distribution matching which is known to be mode seeking. In this paper, we generalize the distribution matching approach using a novel $f$-divergence minimization framework, termed $f$-distill, that covers different divergences with different trade-offs in terms of mode coverage and training variance. We derive the gradient of the $f$-divergence between the teacher and student distributions and show that it is expressed as the product of their score differences and a weighting function determined by their density ratio. This weighting function naturally emphasizes samples with higher density in the teacher distribution, when using a less mode-seeking divergence. We observe that the popular variational score distillation approach using the reverse-KL divergence is a special case within our framework. Empirically, we demonstrate that alternative $f$-divergences, such as forward-KL and Jensen-Shannon divergences, outperform the current best variational score distillation methods across image generation tasks. In particular, when using Jensen-Shannon divergence, $f$-distill achieves current state-of-the-art one-step generation performance on ImageNet64 and zero-shot text-to-image generation on MS-COCO. Project page: https://research.nvidia.com/labs/genair/f-distill
A2SB: Audio-to-Audio Schrodinger Bridges
Jan 20, 2025



Audio in the real world may be perturbed due to numerous factors, causing the audio quality to be degraded. The following work presents an audio restoration model tailored for high-res music at 44.1kHz. Our model, Audio-to-Audio Schrodinger Bridges (A2SB), is capable of both bandwidth extension (predicting high-frequency components) and inpainting (re-generating missing segments). Critically, A2SB is end-to-end without need of a vocoder to predict waveform outputs, able to restore hour-long audio inputs, and trained on permissively licensed music data. A2SB is capable of achieving state-of-the-art bandwidth extension and inpainting quality on several out-of-distribution music test sets. Our demo website is https: //research.nvidia.com/labs/adlr/A2SB/.
BlobGEN-Vid: Compositional Text-to-Video Generation with Blob Video Representations
Jan 13, 2025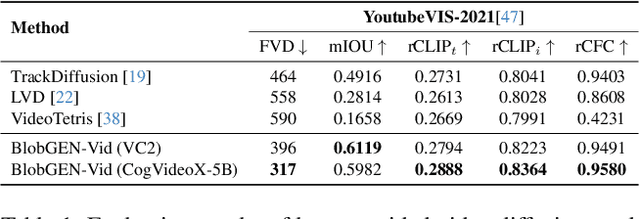
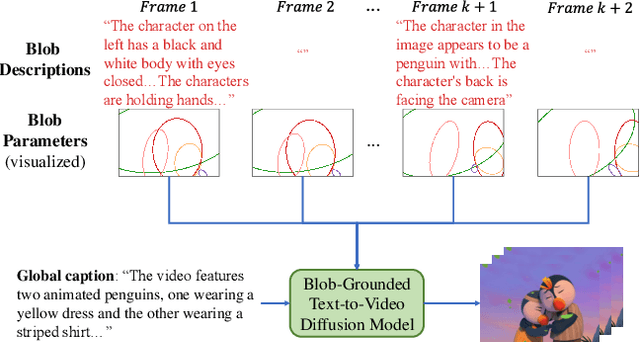
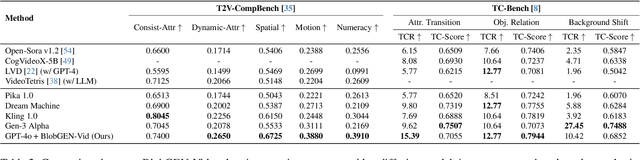
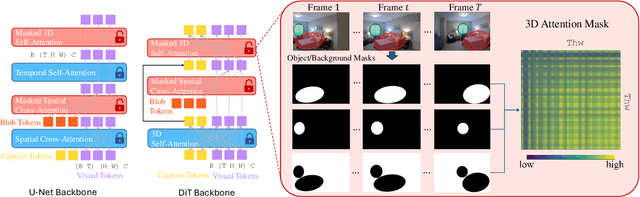
Existing video generation models struggle to follow complex text prompts and synthesize multiple objects, raising the need for additional grounding input for improved controllability. In this work, we propose to decompose videos into visual primitives - blob video representation, a general representation for controllable video generation. Based on blob conditions, we develop a blob-grounded video diffusion model named BlobGEN-Vid that allows users to control object motions and fine-grained object appearance. In particular, we introduce a masked 3D attention module that effectively improves regional consistency across frames. In addition, we introduce a learnable module to interpolate text embeddings so that users can control semantics in specific frames and obtain smooth object transitions. We show that our framework is model-agnostic and build BlobGEN-Vid based on both U-Net and DiT-based video diffusion models. Extensive experimental results show that BlobGEN-Vid achieves superior zero-shot video generation ability and state-of-the-art layout controllability on multiple benchmarks. When combined with an LLM for layout planning, our framework even outperforms proprietary text-to-video generators in terms of compositional accuracy.
GenMol: A Drug Discovery Generalist with Discrete Diffusion
Jan 10, 2025



Drug discovery is a complex process that involves multiple scenarios and stages, such as fragment-constrained molecule generation, hit generation and lead optimization. However, existing molecular generative models can only tackle one or two of these scenarios and lack the flexibility to address various aspects of the drug discovery pipeline. In this paper, we present Generalist Molecular generative model (GenMol), a versatile framework that addresses these limitations by applying discrete diffusion to the Sequential Attachment-based Fragment Embedding (SAFE) molecular representation. GenMol generates SAFE sequences through non-autoregressive bidirectional parallel decoding, thereby allowing utilization of a molecular context that does not rely on the specific token ordering and enhanced computational efficiency. Moreover, under the discrete diffusion framework, we introduce fragment remasking, a strategy that optimizes molecules by replacing fragments with masked tokens and regenerating them, enabling effective exploration of chemical space. GenMol significantly outperforms the previous GPT-based model trained on SAFE representations in de novo generation and fragment-constrained generation, and achieves state-of-the-art performance in goal-directed hit generation and lead optimization. These experimental results demonstrate that GenMol can tackle a wide range of drug discovery tasks, providing a unified and versatile approach for molecular design.
Molecule Generation with Fragment Retrieval Augmentation
Nov 18, 2024



Fragment-based drug discovery, in which molecular fragments are assembled into new molecules with desirable biochemical properties, has achieved great success. However, many fragment-based molecule generation methods show limited exploration beyond the existing fragments in the database as they only reassemble or slightly modify the given ones. To tackle this problem, we propose a new fragment-based molecule generation framework with retrieval augmentation, namely Fragment Retrieval-Augmented Generation (f-RAG). f-RAG is based on a pre-trained molecular generative model that proposes additional fragments from input fragments to complete and generate a new molecule. Given a fragment vocabulary, f-RAG retrieves two types of fragments: (1) hard fragments, which serve as building blocks that will be explicitly included in the newly generated molecule, and (2) soft fragments, which serve as reference to guide the generation of new fragments through a trainable fragment injection module. To extrapolate beyond the existing fragments, f-RAG updates the fragment vocabulary with generated fragments via an iterative refinement process which is further enhanced with post-hoc genetic fragment modification. f-RAG can achieve an improved exploration-exploitation trade-off by maintaining a pool of fragments and expanding it with novel and high-quality fragments through a strong generative prior.
Multi-student Diffusion Distillation for Better One-step Generators
Oct 30, 2024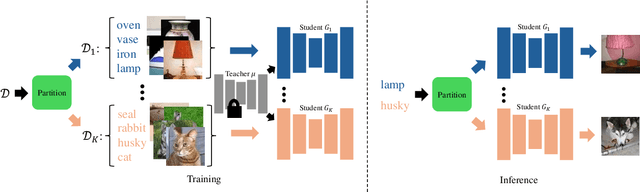


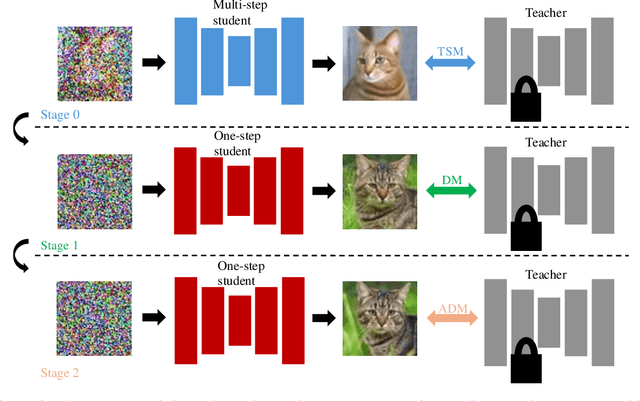
Diffusion models achieve high-quality sample generation at the cost of a lengthy multistep inference procedure. To overcome this, diffusion distillation techniques produce student generators capable of matching or surpassing the teacher in a single step. However, the student model's inference speed is limited by the size of the teacher architecture, preventing real-time generation for computationally heavy applications. In this work, we introduce Multi-Student Distillation (MSD), a framework to distill a conditional teacher diffusion model into multiple single-step generators. Each student generator is responsible for a subset of the conditioning data, thereby obtaining higher generation quality for the same capacity. MSD trains multiple distilled students, allowing smaller sizes and, therefore, faster inference. Also, MSD offers a lightweight quality boost over single-student distillation with the same architecture. We demonstrate MSD is effective by training multiple same-sized or smaller students on single-step distillation using distribution matching and adversarial distillation techniques. With smaller students, MSD gets competitive results with faster inference for single-step generation. Using 4 same-sized students, MSD sets a new state-of-the-art for one-step image generation: FID 1.20 on ImageNet-64x64 and 8.20 on zero-shot COCO2014.