 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoAda: Efficiently Finetune Geometric Diffusion Models with Equivariant Adapters
Jul 02, 2025Geometric diffusion models have shown remarkable success in molecular dynamics and structure generation. However, efficiently fine-tuning them for downstream tasks with varying geometric controls remains underexplored. In this work, we propose an SE(3)-equivariant adapter framework ( GeoAda) that enables flexible and parameter-efficient fine-tuning for controlled generative tasks without modifying the original model architecture. GeoAda introduces a structured adapter design: control signals are first encoded through coupling operators, then processed by a trainable copy of selected pretrained model layers, and finally projected back via decoupling operators followed by an equivariant zero-initialized convolution. By fine-tuning only these lightweight adapter modules, GeoAda preserves the model's geometric consistency while mitigating overfitting and catastrophic forgetting. We theoretically prove that the proposed adapters maintain SE(3)-equivariance, ensuring that the geometric inductive biases of the pretrained diffusion model remain intact during adaptation. We demonstrate the wide applicability of GeoAda across diverse geometric control types, including frame control, global control, subgraph control, and a broad range of application domains such as particle dynamics, molecular dynamics, human motion prediction, and molecule generation. Empirical results show that GeoAda achieves state-of-the-art fine-tuning performance while preserving original task accuracy, whereas other baselines experience significant performance degradation due to overfitting and catastrophic forgetting.
LayoutVLM: Differentiable Optimization of 3D Layout via Vision-Language Models
Dec 03, 2024



Open-universe 3D layout generation arranges unlabeled 3D assets conditioned on language instruction. Large language models (LLMs) struggle with generating physically plausible 3D scenes and adherence to input instructions, particularly in cluttered scenes. We introduce LayoutVLM, a framework and scene layout representation that exploits the semantic knowledge of Vision-Language Models (VLMs) and supports differentiable optimization to ensure physical plausibility. LayoutVLM employs VLMs to generate two mutually reinforcing representations from visually marked images, and a self-consistent decoding process to improve VLMs spatial planning. Our experiments show that LayoutVLM addresses the limitations of existing LLM and constraint-based approaches, producing physically plausible 3D layouts better aligned with the semantic intent of input language instructions. We also demonstrate that fine-tuning VLMs with the proposed scene layout representation extracted from existing scene datasets can improve performance.
Aligning Target-Aware Molecule Diffusion Models with Exact Energy Optimization
Jul 01, 2024Generating ligand molecules for specific protein targets, known as structure-based drug design, is a fundamental problem in therapeutics development and biological discovery. Recently, target-aware generative models, especially diffusion models, have shown great promise in modeling protein-ligand interactions and generating candidate drugs. However, existing models primarily focus on learning the chemical distribution of all drug candidates, which lacks effective steerability on the chemical quality of model generations. In this paper, we propose a novel and general alignment framework to align pretrained target diffusion models with preferred functional properties, named AliDiff. AliDiff shifts the target-conditioned chemical distribution towards regions with higher binding affinity and structural rationality, specified by user-defined reward functions, via the preference optimization approach. To avoid the overfitting problem in common preference optimization objectives, we further develop an improved Exact Energy Preference Optimization method to yield an exact and efficient alignment of the diffusion models, and provide the closed-form expression for the converged distribution. Empirical studies on the CrossDocked2020 benchmark show that AliDiff can generate molecules with state-of-the-art binding energies with up to -7.07 Avg. Vina Score, while maintaining strong molecular properties.
DUE: Dynamic Uncertainty-Aware Explanation Supervision via 3D Imputation
Mar 16, 2024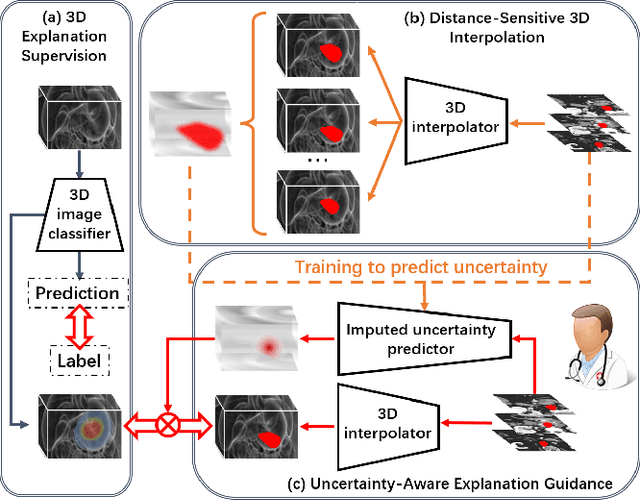
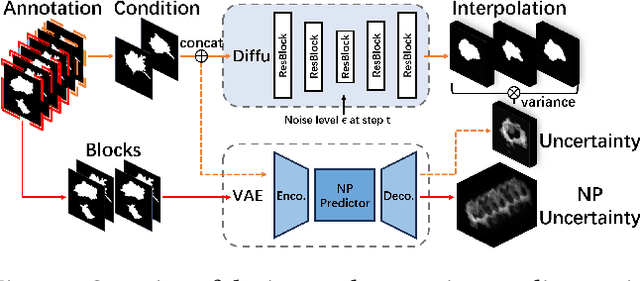
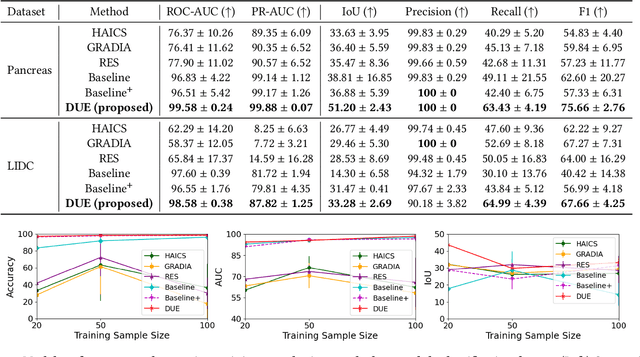
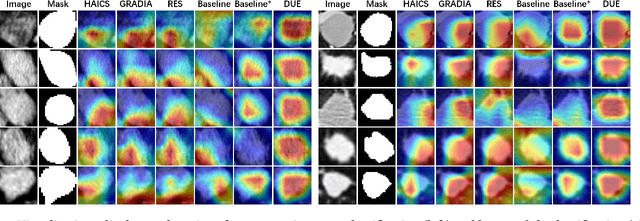
Explanation supervision aims to enhance deep learning models by integrating additional signals to guide the generation of model explanations, showcasing notable improvements in both the predictability and explainability of the model. However, the application of explanation supervision to higher-dimensional data, such as 3D medical images, remains an under-explored domain. Challenges associated with supervising visual explanations in the presence of an additional dimension include: 1) spatial correlation changed, 2) lack of direct 3D annotations, and 3) uncertainty varies across different parts of the explanation. To address these challenges, we propose a Dynamic Uncertainty-aware Explanation supervision (DUE) framework for 3D explanation supervision that ensures uncertainty-aware explanation guidance when dealing with sparsely annotated 3D data with diffusion-based 3D interpolation. Our proposed framework is validated through comprehensive experiments on diverse real-world medical imaging datasets. The results demonstrate the effectiveness of our framework in enhancing the predictability and explainability of deep learning models in the context of medical imaging diagnosis applications.
XAI Benchmark for Visual Explanation
Oct 12, 2023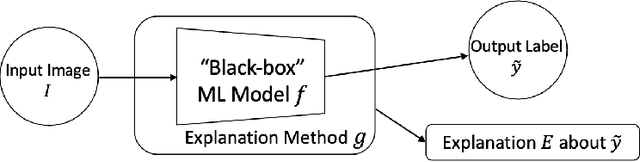
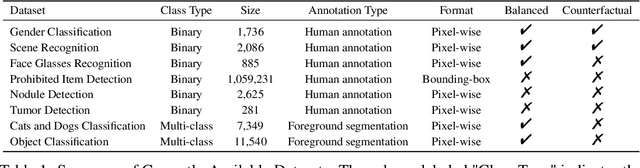
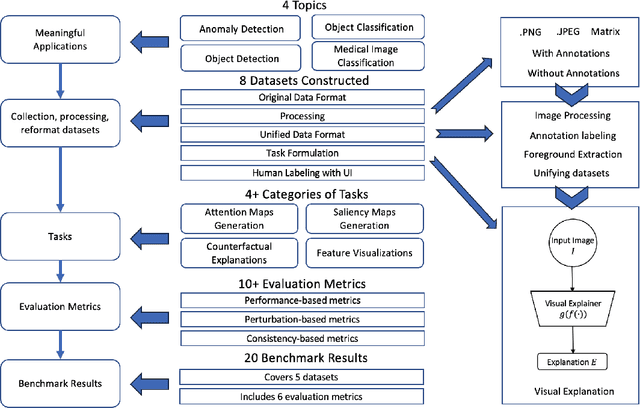

The rise of deep learning algorithms has led to significant advancements in computer vision tasks, but their "black box" nature has raised concerns regarding interpretability. Explainable AI (XAI) has emerged as a critical area of research aiming to open this "black box", and shed light on the decision-making process of AI models. Visual explanations, as a subset of Explainable Artificial Intelligence (XAI), provide intuitive insights into the decision-making processes of AI models handling visual data by highlighting influential areas in an input image. Despite extensive research conducted on visual explanations, most evaluations are model-centered since the availability of corresponding real-world datasets with ground truth explanations is scarce in the context of image data. To bridge this gap, we introduce an XAI Benchmark comprising a dataset collection from diverse topics that provide both class labels and corresponding explanation annotations for images. We have processed data from diverse domains to align with our unified visual explanation framework. We introduce a comprehensive Visual Explanation pipeline, which integrates data loading, preprocessing, experimental setup, and model evaluation processes. This structure enables researchers to conduct fair comparisons of various visual explanation techniques. In addition, we provide a comprehensive review of over 10 evaluation methods for visual explanation to assist researchers in effectively utilizing our dataset collection. To further assess the performance of existing visual explanation methods, we conduct experiments on selected datasets using various model-centered and ground truth-centered evaluation metrics. We envision this benchmark could facilitate the advancement of visual explanation models. The XAI dataset collection and easy-to-use code for evaluation are publicly accessible at https://xaidataset.github.io.
Visual Attention-Prompted Prediction and Learning
Oct 12, 2023



Explanation(attention)-guided learning is a method that enhances a model's predictive power by incorporating human understanding during the training phase. While attention-guided learning has shown promising results, it often involves time-consuming and computationally expensive model retraining. To address this issue, we introduce the attention-prompted prediction technique, which enables direct prediction guided by the attention prompt without the need for model retraining. However, this approach presents several challenges, including: 1) How to incorporate the visual attention prompt into the model's decision-making process and leverage it for future predictions even in the absence of a prompt? and 2) How to handle the incomplete information from the visual attention prompt? To tackle these challenges, we propose a novel framework called Visual Attention-Prompted Prediction and Learning, which seamlessly integrates visual attention prompts into the model's decision-making process and adapts to images both with and without attention prompts for prediction. To address the incomplete information of the visual attention prompt, we introduce a perturbation-based attention map modification method. Additionally, we propose an optimization-based mask aggregation method with a new weight learning function for adaptive perturbed annotation aggregation in the attention map modification process. Our overall framework is designed to learn in an attention-prompt guided multi-task manner to enhance future predictions even for samples without attention prompts and trained in an alternating manner for better convergence. Extensive experiments conducted on two datasets demonstrate the effectiveness of our proposed framework in enhancing predictions for samples, both with and without provided prompts.
Going Beyond XAI: A Systematic Survey for Explanation-Guided Learning
Dec 07, 2022



As the societal impact of Deep Neural Networks (DNNs) grows, the goals for advancing DNNs become more complex and diverse, ranging from improving a conventional model accuracy metric to infusing advanced human virtues such as fairness, accountability, transparency (FaccT), and unbiasedness. Recently, techniques in Explainable Artificial Intelligence (XAI) are attracting considerable attention, and have tremendously helped Machine Learning (ML) engineers in understanding AI models. However, at the same time, we started to witness the emerging need beyond XAI among AI communities; based on the insights learned from XAI, how can we better empower ML engineers in steering their DNNs so that the model's reasonableness and performance can be improved as intended? This article provides a timely and extensive literature overview of the field Explanation-Guided Learning (EGL), a domain of techniques that steer the DNNs' reasoning process by adding regularization, supervision, or intervention on model explanations. In doing so, we first provide a formal definition of EGL and its general learning paradigm. Secondly, an overview of the key factors for EGL evaluation, as well as summarization and categorization of existing evaluation procedures and metrics for EGL are provided. Finally, the current and potential future application areas and directions of EGL are discussed, and an extensive experimental study is presented aiming at providing comprehensive comparative studies among existing EGL models in various popular application domains, such as Computer Vision (CV) and Natural Language Processing (NLP) domains.
RES: A Robust Framework for Guiding Visual Explanation
Jun 27, 2022
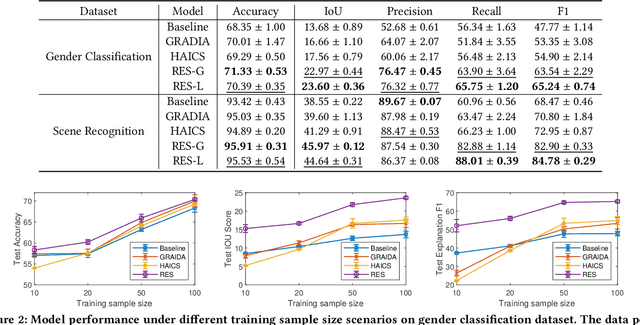
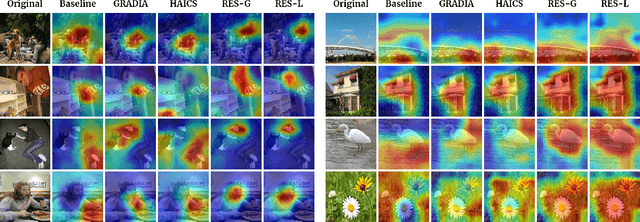
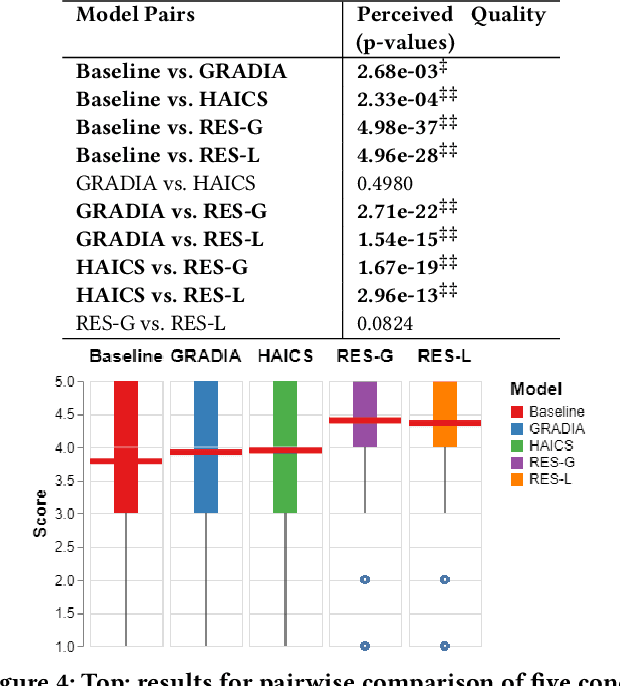
Despite the fast progress of explanation techniques in modern Deep Neural Networks (DNNs) where the main focus is handling "how to generate the explanations", advanced research questions that examine the quality of the explanation itself (e.g., "whether the explanations are accurate") and improve the explanation quality (e.g., "how to adjust the model to generate more accurate explanations when explanations are inaccurate") are still relatively under-explored. To guide the model toward better explanations, techniques in explanation supervision - which add supervision signals on the model explanation - have started to show promising effects on improving both the generalizability as and intrinsic interpretability of Deep Neural Networks. However, the research on supervising explanations, especially in vision-based applications represented through saliency maps, is in its early stage due to several inherent challenges: 1) inaccuracy of the human explanation annotation boundary, 2) incompleteness of the human explanation annotation region, and 3) inconsistency of the data distribution between human annotation and model explanation maps. To address the challenges, we propose a generic RES framework for guiding visual explanation by developing a novel objective that handles inaccurate boundary, incomplete region, and inconsistent distribution of human annotations, with a theoretical justification on model generalizability. Extensive experiments on two real-world image datasets demonstrate the effectiveness of the proposed framework on enhancing both the reasonability of the explanation and the performance of the backbone DNNs model.
* Published in KDD 2022