 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNodule-Aligned Latent Space Learning with LLM-Driven Multimodal Diffusion for Lung Nodule Progression Prediction
Mar 16, 2026Early diagnosis of lung cancer is challenging due to biological uncertainty and the limited understanding of the biological mechanisms driving nodule progression. To address this, we propose Nodule-Aligned Multimodal (Latent) Diffusion (NAMD), a novel framework that predicts lung nodule progression by generating 1-year follow-up nodule computed tomography images with baseline scans and the patient's and nodule's Electronic Health Record (EHR). NAMD introduces a nodule-aligned latent space, where distances between latents directly correspond to changes in nodule attributes, and utilizes an LLM-driven control mechanism to condition the diffusion backbone on patient data. On the National Lung Screening Trial (NLST) dataset, our method synthesizes follow-up nodule images that achieve an AUROC of 0.805 and an AUPRC of 0.346 for lung nodule malignancy prediction, significantly outperforming both baseline scans and state-of-the-art synthesis methods, while closely approaching the performance of real follow-up scans (AUROC: 0.819, AUPRC: 0.393). These results demonstrate that NAMD captures clinically relevant features of lung nodule progression, facilitating earlier and more accurate diagnosis.
XAI Benchmark for Visual Explanation
Oct 12, 2023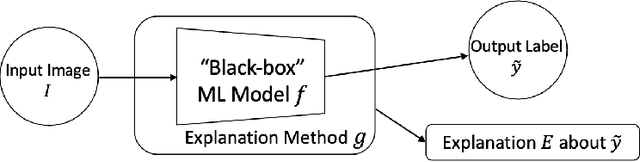
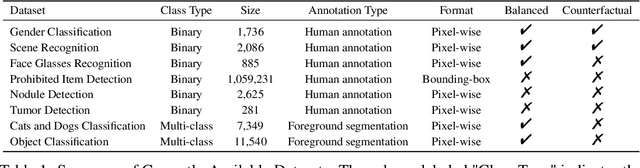
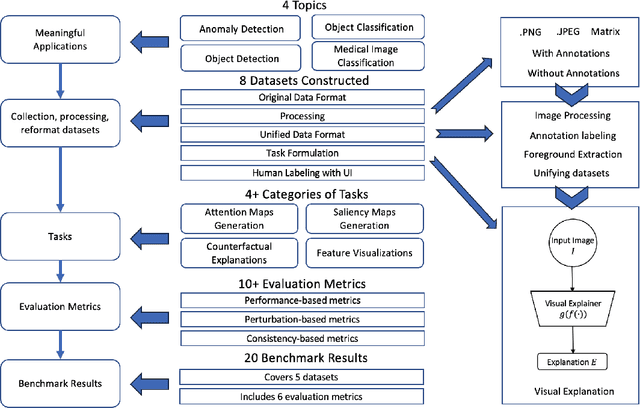

The rise of deep learning algorithms has led to significant advancements in computer vision tasks, but their "black box" nature has raised concerns regarding interpretability. Explainable AI (XAI) has emerged as a critical area of research aiming to open this "black box", and shed light on the decision-making process of AI models. Visual explanations, as a subset of Explainable Artificial Intelligence (XAI), provide intuitive insights into the decision-making processes of AI models handling visual data by highlighting influential areas in an input image. Despite extensive research conducted on visual explanations, most evaluations are model-centered since the availability of corresponding real-world datasets with ground truth explanations is scarce in the context of image data. To bridge this gap, we introduce an XAI Benchmark comprising a dataset collection from diverse topics that provide both class labels and corresponding explanation annotations for images. We have processed data from diverse domains to align with our unified visual explanation framework. We introduce a comprehensive Visual Explanation pipeline, which integrates data loading, preprocessing, experimental setup, and model evaluation processes. This structure enables researchers to conduct fair comparisons of various visual explanation techniques. In addition, we provide a comprehensive review of over 10 evaluation methods for visual explanation to assist researchers in effectively utilizing our dataset collection. To further assess the performance of existing visual explanation methods, we conduct experiments on selected datasets using various model-centered and ground truth-centered evaluation metrics. We envision this benchmark could facilitate the advancement of visual explanation models. The XAI dataset collection and easy-to-use code for evaluation are publicly accessible at https://xaidataset.github.io.
Deep Graph Representation Learning and Optimization for Influence Maximization
May 06, 2023



Influence maximization (IM) is formulated as selecting a set of initial users from a social network to maximize the expected number of influenced users. Researchers have made great progress in designing various traditional methods, and their theoretical design and performance gain are close to a limit. In the past few years, learning-based IM methods have emerged to achieve stronger generalization ability to unknown graphs than traditional ones. However, the development of learning-based IM methods is still limited by fundamental obstacles, including 1) the difficulty of effectively solving the objective function; 2) the difficulty of characterizing the diversified underlying diffusion patterns; and 3) the difficulty of adapting the solution under various node-centrality-constrained IM variants. To cope with the above challenges, we design a novel framework DeepIM to generatively characterize the latent representation of seed sets, and we propose to learn the diversified information diffusion pattern in a data-driven and end-to-end manner. Finally, we design a novel objective function to infer optimal seed sets under flexible node-centrality-based budget constraints. Extensive analyses are conducted over both synthetic and real-world datasets to demonstrate the overall performance of DeepIM. The code and data are available at: https://github.com/triplej0079/DeepIM.