 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning a Direct Feedback Loop between Humans and Convolutional Neural Networks through Local Explanations
Jul 08, 2023
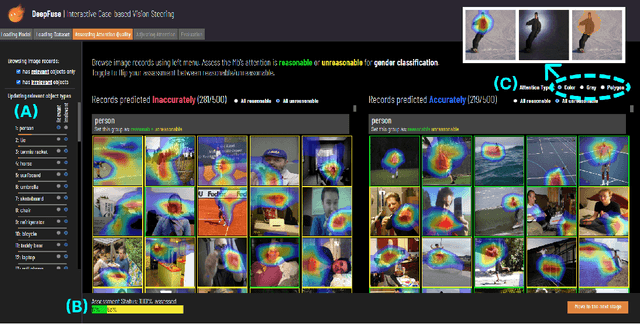

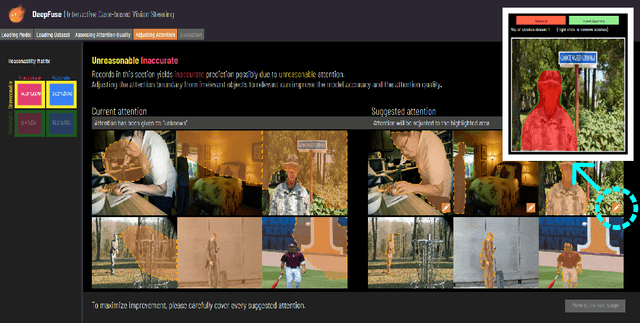
The local explanation provides heatmaps on images to explain how Convolutional Neural Networks (CNNs) derive their output. Due to its visual straightforwardness, the method has been one of the most popular explainable AI (XAI) methods for diagnosing CNNs. Through our formative study (S1), however, we captured ML engineers' ambivalent perspective about the local explanation as a valuable and indispensable envision in building CNNs versus the process that exhausts them due to the heuristic nature of detecting vulnerability. Moreover, steering the CNNs based on the vulnerability learned from the diagnosis seemed highly challenging. To mitigate the gap, we designed DeepFuse, the first interactive design that realizes the direct feedback loop between a user and CNNs in diagnosing and revising CNN's vulnerability using local explanations. DeepFuse helps CNN engineers to systemically search "unreasonable" local explanations and annotate the new boundaries for those identified as unreasonable in a labor-efficient manner. Next, it steers the model based on the given annotation such that the model doesn't introduce similar mistakes. We conducted a two-day study (S2) with 12 experienced CNN engineers. Using DeepFuse, participants made a more accurate and "reasonable" model than the current state-of-the-art. Also, participants found the way DeepFuse guides case-based reasoning can practically improve their current practice. We provide implications for design that explain how future HCI-driven design can move our practice forward to make XAI-driven insights more actionable.
RES: A Robust Framework for Guiding Visual Explanation
Jun 27, 2022
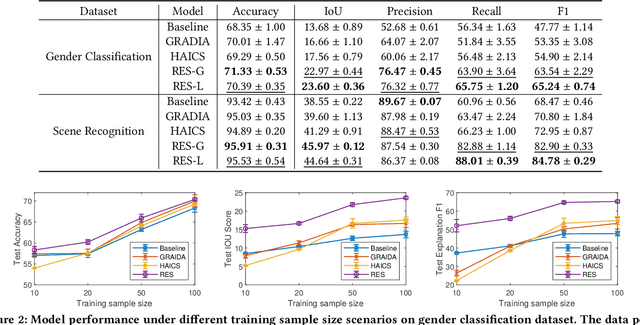
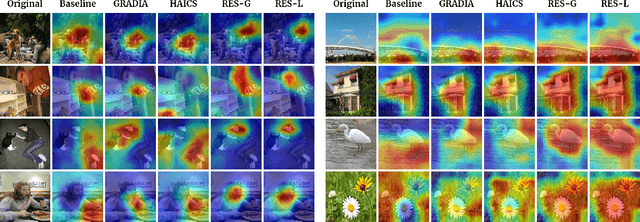
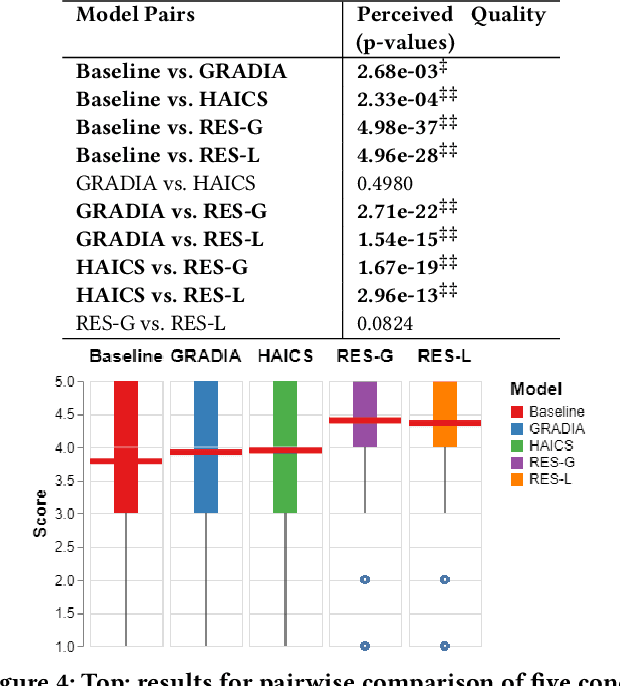
Despite the fast progress of explanation techniques in modern Deep Neural Networks (DNNs) where the main focus is handling "how to generate the explanations", advanced research questions that examine the quality of the explanation itself (e.g., "whether the explanations are accurate") and improve the explanation quality (e.g., "how to adjust the model to generate more accurate explanations when explanations are inaccurate") are still relatively under-explored. To guide the model toward better explanations, techniques in explanation supervision - which add supervision signals on the model explanation - have started to show promising effects on improving both the generalizability as and intrinsic interpretability of Deep Neural Networks. However, the research on supervising explanations, especially in vision-based applications represented through saliency maps, is in its early stage due to several inherent challenges: 1) inaccuracy of the human explanation annotation boundary, 2) incompleteness of the human explanation annotation region, and 3) inconsistency of the data distribution between human annotation and model explanation maps. To address the challenges, we propose a generic RES framework for guiding visual explanation by developing a novel objective that handles inaccurate boundary, incomplete region, and inconsistent distribution of human annotations, with a theoretical justification on model generalizability. Extensive experiments on two real-world image datasets demonstrate the effectiveness of the proposed framework on enhancing both the reasonability of the explanation and the performance of the backbone DNNs model.
* Published in KDD 2022