 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Data-Driven Probabilistic Medium-Range Weather Forecasting
Jan 26, 2026The recent revolution in data-driven methods for weather forecasting has lead to a fragmented landscape of complex, bespoke architectures and training strategies, obscuring the fundamental drivers of forecast accuracy. Here, we demonstrate that state-of-the-art probabilistic skill requires neither intricate architectural constraints nor specialized training heuristics. We introduce a scalable framework for learning multi-scale atmospheric dynamics by combining a directly downsampled latent space with a history-conditioned local projector that resolves high-resolution physics. We find that our framework design is robust to the choice of probabilistic estimator, seamlessly supporting stochastic interpolants, diffusion models, and CRPS-based ensemble training. Validated against the Integrated Forecasting System and the deep learning probabilistic model GenCast, our framework achieves statistically significant improvements on most of the variables. These results suggest scaling a general-purpose model is sufficient for state-of-the-art medium-range prediction, eliminating the need for tailored training recipes and proving effective across the full spectrum of probabilistic frameworks.
Rethinking Molecule Synthesizability with Chain-of-Reaction
Sep 19, 2025A well-known pitfall of molecular generative models is that they are not guaranteed to generate synthesizable molecules. There have been considerable attempts to address this problem, but given the exponentially large combinatorial space of synthesizable molecules, existing methods have shown limited coverage of the space and poor molecular optimization performance. To tackle these problems, we introduce ReaSyn, a generative framework for synthesizable projection where the model explores the neighborhood of given molecules in the synthesizable space by generating pathways that result in synthesizable analogs. To fully utilize the chemical knowledge contained in the synthetic pathways, we propose a novel perspective that views synthetic pathways akin to reasoning paths in large language models (LLMs). Specifically, inspired by chain-of-thought (CoT) reasoning in LLMs, we introduce the chain-of-reaction (CoR) notation that explicitly states reactants, reaction types, and intermediate products for each step in a pathway. With the CoR notation, ReaSyn can get dense supervision in every reaction step to explicitly learn chemical reaction rules during supervised training and perform step-by-step reasoning. In addition, to further enhance the reasoning capability of ReaSyn, we propose reinforcement learning (RL)-based finetuning and goal-directed test-time compute scaling tailored for synthesizable projection. ReaSyn achieves the highest reconstruction rate and pathway diversity in synthesizable molecule reconstruction and the highest optimization performance in synthesizable goal-directed molecular optimization, and significantly outperforms previous synthesizable projection methods in synthesizable hit expansion. These results highlight ReaSyn's superior ability to navigate combinatorially-large synthesizable chemical space.
Align Your Flow: Scaling Continuous-Time Flow Map Distillation
Jun 17, 2025Diffusion- and flow-based models have emerged as state-of-the-art generative modeling approaches, but they require many sampling steps. Consistency models can distill these models into efficient one-step generators; however, unlike flow- and diffusion-based methods, their performance inevitably degrades when increasing the number of steps, which we show both analytically and empirically. Flow maps generalize these approaches by connecting any two noise levels in a single step and remain effective across all step counts. In this paper, we introduce two new continuous-time objectives for training flow maps, along with additional novel training techniques, generalizing existing consistency and flow matching objectives. We further demonstrate that autoguidance can improve performance, using a low-quality model for guidance during distillation, and an additional boost can be achieved by adversarial finetuning, with minimal loss in sample diversity. We extensively validate our flow map models, called Align Your Flow, on challenging image generation benchmarks and achieve state-of-the-art few-step generation performance on both ImageNet 64x64 and 512x512, using small and efficient neural networks. Finally, we show text-to-image flow map models that outperform all existing non-adversarially trained few-step samplers in text-conditioned synthesis.
GenMol: A Drug Discovery Generalist with Discrete Diffusion
Jan 10, 2025



Drug discovery is a complex process that involves multiple scenarios and stages, such as fragment-constrained molecule generation, hit generation and lead optimization. However, existing molecular generative models can only tackle one or two of these scenarios and lack the flexibility to address various aspects of the drug discovery pipeline. In this paper, we present Generalist Molecular generative model (GenMol), a versatile framework that addresses these limitations by applying discrete diffusion to the Sequential Attachment-based Fragment Embedding (SAFE) molecular representation. GenMol generates SAFE sequences through non-autoregressive bidirectional parallel decoding, thereby allowing utilization of a molecular context that does not rely on the specific token ordering and enhanced computational efficiency. Moreover, under the discrete diffusion framework, we introduce fragment remasking, a strategy that optimizes molecules by replacing fragments with masked tokens and regenerating them, enabling effective exploration of chemical space. GenMol significantly outperforms the previous GPT-based model trained on SAFE representations in de novo generation and fragment-constrained generation, and achieves state-of-the-art performance in goal-directed hit generation and lead optimization. These experimental results demonstrate that GenMol can tackle a wide range of drug discovery tasks, providing a unified and versatile approach for molecular design.
Molecule Generation with Fragment Retrieval Augmentation
Nov 18, 2024



Fragment-based drug discovery, in which molecular fragments are assembled into new molecules with desirable biochemical properties, has achieved great success. However, many fragment-based molecule generation methods show limited exploration beyond the existing fragments in the database as they only reassemble or slightly modify the given ones. To tackle this problem, we propose a new fragment-based molecule generation framework with retrieval augmentation, namely Fragment Retrieval-Augmented Generation (f-RAG). f-RAG is based on a pre-trained molecular generative model that proposes additional fragments from input fragments to complete and generate a new molecule. Given a fragment vocabulary, f-RAG retrieves two types of fragments: (1) hard fragments, which serve as building blocks that will be explicitly included in the newly generated molecule, and (2) soft fragments, which serve as reference to guide the generation of new fragments through a trainable fragment injection module. To extrapolate beyond the existing fragments, f-RAG updates the fragment vocabulary with generated fragments via an iterative refinement process which is further enhanced with post-hoc genetic fragment modification. f-RAG can achieve an improved exploration-exploitation trade-off by maintaining a pool of fragments and expanding it with novel and high-quality fragments through a strong generative prior.
Multi-student Diffusion Distillation for Better One-step Generators
Oct 30, 2024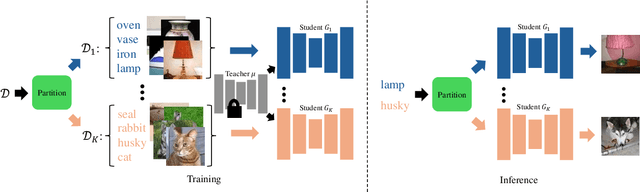


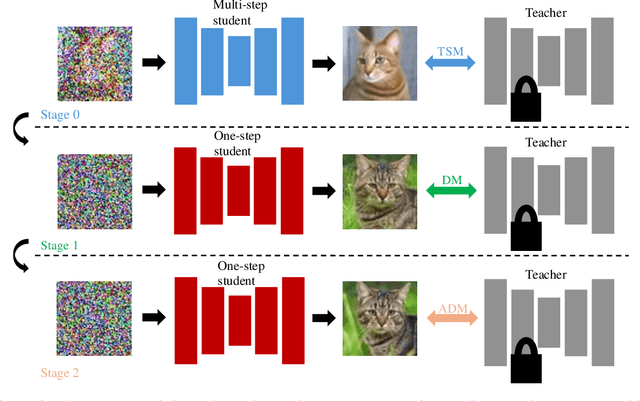
Diffusion models achieve high-quality sample generation at the cost of a lengthy multistep inference procedure. To overcome this, diffusion distillation techniques produce student generators capable of matching or surpassing the teacher in a single step. However, the student model's inference speed is limited by the size of the teacher architecture, preventing real-time generation for computationally heavy applications. In this work, we introduce Multi-Student Distillation (MSD), a framework to distill a conditional teacher diffusion model into multiple single-step generators. Each student generator is responsible for a subset of the conditioning data, thereby obtaining higher generation quality for the same capacity. MSD trains multiple distilled students, allowing smaller sizes and, therefore, faster inference. Also, MSD offers a lightweight quality boost over single-student distillation with the same architecture. We demonstrate MSD is effective by training multiple same-sized or smaller students on single-step distillation using distribution matching and adversarial distillation techniques. With smaller students, MSD gets competitive results with faster inference for single-step generation. Using 4 same-sized students, MSD sets a new state-of-the-art for one-step image generation: FID 1.20 on ImageNet-64x64 and 8.20 on zero-shot COCO2014.
Energy-Based Diffusion Language Models for Text Generation
Oct 28, 2024


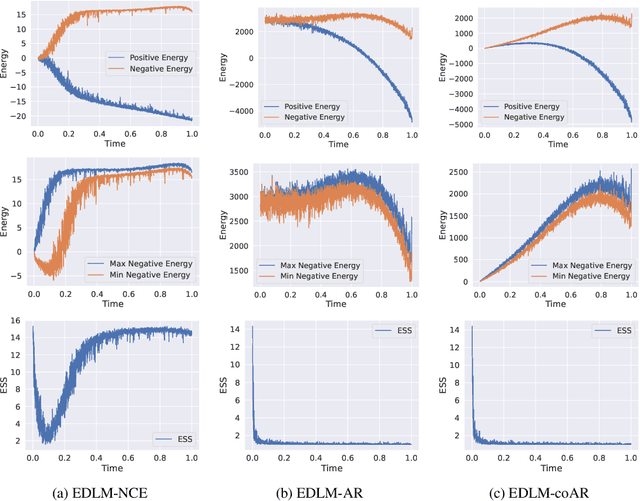
Despite remarkable progress in autoregressive language models, alternative generative paradigms beyond left-to-right generation are still being actively explored. Discrete diffusion models, with the capacity for parallel generation, have recently emerged as a promising alternative. Unfortunately, these models still underperform the autoregressive counterparts, with the performance gap increasing when reducing the number of sampling steps. Our analysis reveals that this degradation is a consequence of an imperfect approximation used by diffusion models. In this work, we propose Energy-based Diffusion Language Model (EDLM), an energy-based model operating at the full sequence level for each diffusion step, introduced to improve the underlying approximation used by diffusion models. More specifically, we introduce an EBM in a residual form, and show that its parameters can be obtained by leveraging a pretrained autoregressive model or by finetuning a bidirectional transformer via noise contrastive estimation. We also propose an efficient generation algorithm via parallel important sampling. Comprehensive experiments on language modeling benchmarks show that our model can consistently outperform state-of-the-art diffusion models by a significant margin, and approaches autoregressive models' perplexity. We further show that, without any generation performance drop, our framework offers a 1.3$\times$ sampling speedup over existing diffusion models.
Warped Diffusion: Solving Video Inverse Problems with Image Diffusion Models
Oct 21, 2024



Using image models naively for solving inverse video problems often suffers from flickering, texture-sticking, and temporal inconsistency in generated videos. To tackle these problems, in this paper, we view frames as continuous functions in the 2D space, and videos as a sequence of continuous warping transformations between different frames. This perspective allows us to train function space diffusion models only on images and utilize them to solve temporally correlated inverse problems. The function space diffusion models need to be equivariant with respect to the underlying spatial transformations. To ensure temporal consistency, we introduce a simple post-hoc test-time guidance towards (self)-equivariant solutions. Our method allows us to deploy state-of-the-art latent diffusion models such as Stable Diffusion XL to solve video inverse problems. We demonstrate the effectiveness of our method for video inpainting and $8\times$ video super-resolution, outperforming existing techniques based on noise transformations. We provide generated video results: https://giannisdaras.github.io/warped\_diffusion.github.io/.
Truncated Consistency Models
Oct 18, 2024



Consistency models have recently been introduced to accelerate sampling from diffusion models by directly predicting the solution (i.e., data) of the probability flow ODE (PF ODE) from initial noise. However, the training of consistency models requires learning to map all intermediate points along PF ODE trajectories to their corresponding endpoints. This task is much more challenging than the ultimate objective of one-step generation, which only concerns the PF ODE's noise-to-data mapping. We empirically find that this training paradigm limits the one-step generation performance of consistency models. To address this issue, we generalize consistency training to the truncated time range, which allows the model to ignore denoising tasks at earlier time steps and focus its capacity on generation. We propose a new parameterization of the consistency function and a two-stage training procedure that prevents the truncated-time training from collapsing to a trivial solution. Experiments on CIFAR-10 and ImageNet $64\times64$ datasets show that our method achieves better one-step and two-step FIDs than the state-of-the-art consistency models such as iCT-deep, using more than 2$\times$ smaller networks. Project page: https://truncated-cm.github.io/
EquiJump: Protein Dynamics Simulation via SO(3)-Equivariant Stochastic Interpolants
Oct 12, 2024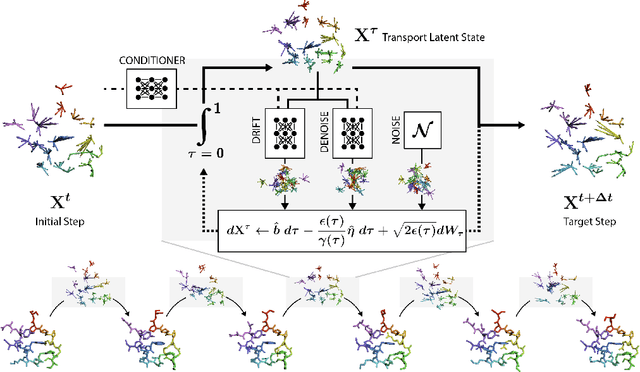

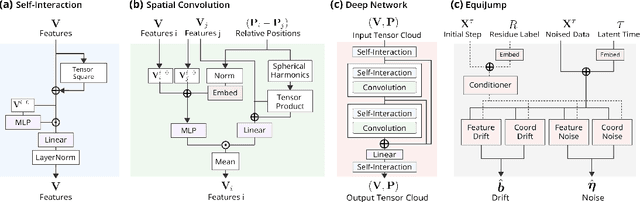
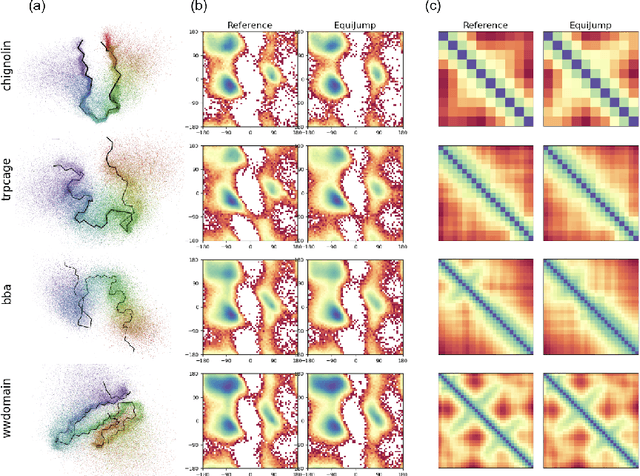
Mapping the conformational dynamics of proteins is crucial for elucidating their functional mechanisms. While Molecular Dynamics (MD) simulation enables detailed time evolution of protein motion, its computational toll hinders its use in practice. To address this challenge, multiple deep learning models for reproducing and accelerating MD have been proposed drawing on transport-based generative methods. However, existing work focuses on generation through transport of samples from prior distributions, that can often be distant from the data manifold. The recently proposed framework of stochastic interpolants, instead, enables transport between arbitrary distribution endpoints. Building upon this work, we introduce EquiJump, a transferable SO(3)-equivariant model that bridges all-atom protein dynamics simulation time steps directly. Our approach unifies diverse sampling methods and is benchmarked against existing models on trajectory data of fast folding proteins. EquiJump achieves state-of-the-art results on dynamics simulation with a transferable model on all of the fast folding proteins.