 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
Jun 02, 2026As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. In closed-loop simulation, the driving policy model actively interacts with the environment, where its actions dynamically update the simulator state and directly influence the next set of generated sensor observations. While recent reconstruction-based neural simulators offer photorealism, they are fundamentally constrained by their initial captured data and struggle to generalize to highly dynamic or novel scenes. To overcome these limitations, we introduce OmniDreams, a foundation generative world model mid- and post-trained from the Cosmos diffusion model to autoregressively generate action-conditioned videos in real time. By leveraging the rich visual priors of Cosmos and mid- and post-training on 21k hours of driving scenarios, OmniDreams synthesizes complex, unobserved phenomena that are hard for traditional simulators to capture, such as extreme weather and unpredictable dynamic agent behaviors. Crucially, it autoregressively conditions its photorealistic sensor generation on past frames, the current simulator state, and immediate driving actions. Deployed in a closed-loop system with the Alpamayo 1 policy model and AlpaSim orchestrator, OmniDreams acts as a highly responsive, reactive environment, providing a scalable and comprehensive solution for training and evaluating next-generation autonomous driving policies. We additionally show preliminary results indicating that a world-action model (WAM) post-trained from OmniDreams achieves strong performance on the Physical AI Autonomous Vehicles NuRec dataset, surpassing the VLA-based Alpamayo 1.5 research policy model while using only 1/5 the total parameters. These results highlight the potential for a real-time world model like OmniDreams to also serve as a backbone for policy architectures.
Variance Reduction for Expectations with Diffusion Teachers
May 20, 2026Pretrained diffusion models serve as frozen teachers feeding downstream pipelines such as text-to-3D, single-step distillation, and data attribution. The teacher gradients these pipelines consume are Monte Carlo (MC) expectations over noise levels and Gaussian noise samples; their estimator variance dominates compute cost because each draw requires expensive upstream work (rendering, simulation, encoding). We introduce CARV, a compute-aware variance-accounting framework that motivates a hierarchical MC estimator: amortize the expensive upstream computation over cheap diffusion-noise resamples, sharpened by timestep importance sampling and a stratified-inverse-CDF construction. In our text-to-3D distillation and attribution experiments, CARV delivers 2-3x effective compute multipliers (most from amortized reuse; ~25% additional from IS+stratification) without changing the objective; in single-step distillation, the same techniques cut gradient variance by an order of magnitude but do not improve downstream FID, marking the regime where MC variance is no longer the bottleneck.
Replay Can Provably Increase Forgetting
Jun 04, 2025Continual learning seeks to enable machine learning systems to solve an increasing corpus of tasks sequentially. A critical challenge for continual learning is forgetting, where the performance on previously learned tasks decreases as new tasks are introduced. One of the commonly used techniques to mitigate forgetting, sample replay, has been shown empirically to reduce forgetting by retaining some examples from old tasks and including them in new training episodes. In this work, we provide a theoretical analysis of sample replay in an over-parameterized continual linear regression setting, where each task is given by a linear subspace and with enough replay samples, one would be able to eliminate forgetting. Our analysis focuses on sample replay and highlights the role of the replayed samples and the relationship between task subspaces. Surprisingly, we find that, even in a noiseless setting, forgetting can be non-monotonic with respect to the number of replay samples. We present tasks where replay can be harmful with respect to worst-case settings, and also in distributional settings where replay of randomly selected samples increases forgetting in expectation. We also give empirical evidence that harmful replay is not limited to training with linear models by showing similar behavior for a neural networks equipped with SGD. Through experiments on a commonly used benchmark, we provide additional evidence that, even in seemingly benign scenarios, performance of the replay heavily depends on the choice of replay samples and the relationship between tasks.
Uncertainty Estimation for 3D Object Detection via Evidential Learning
Oct 31, 2024



3D object detection is an essential task for computer vision applications in autonomous vehicles and robotics. However, models often struggle to quantify detection reliability, leading to poor performance on unfamiliar scenes. We introduce a framework for quantifying uncertainty in 3D object detection by leveraging an evidential learning loss on Bird's Eye View representations in the 3D detector. These uncertainty estimates require minimal computational overhead and are generalizable across different architectures. We demonstrate both the efficacy and importance of these uncertainty estimates on identifying out-of-distribution scenes, poorly localized objects, and missing (false negative) detections; our framework consistently improves over baselines by 10-20% on average. Finally, we integrate this suite of tasks into a system where a 3D object detector auto-labels driving scenes and our uncertainty estimates verify label correctness before the labels are used to train a second model. Here, our uncertainty-driven verification results in a 1% improvement in mAP and a 1-2% improvement in NDS.
Multi-student Diffusion Distillation for Better One-step Generators
Oct 30, 2024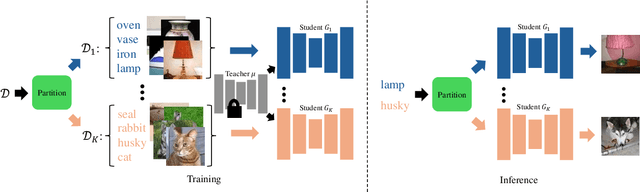


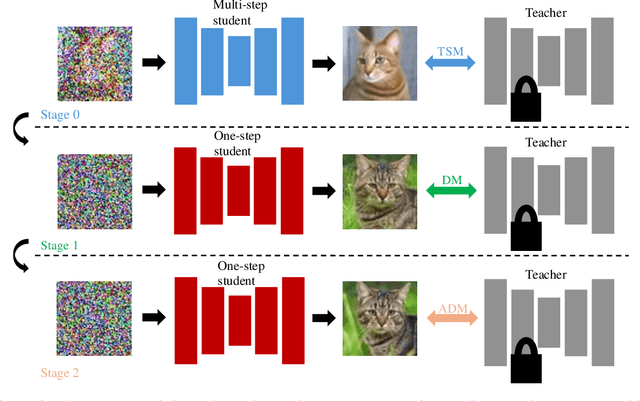
Diffusion models achieve high-quality sample generation at the cost of a lengthy multistep inference procedure. To overcome this, diffusion distillation techniques produce student generators capable of matching or surpassing the teacher in a single step. However, the student model's inference speed is limited by the size of the teacher architecture, preventing real-time generation for computationally heavy applications. In this work, we introduce Multi-Student Distillation (MSD), a framework to distill a conditional teacher diffusion model into multiple single-step generators. Each student generator is responsible for a subset of the conditioning data, thereby obtaining higher generation quality for the same capacity. MSD trains multiple distilled students, allowing smaller sizes and, therefore, faster inference. Also, MSD offers a lightweight quality boost over single-student distillation with the same architecture. We demonstrate MSD is effective by training multiple same-sized or smaller students on single-step distillation using distribution matching and adversarial distillation techniques. With smaller students, MSD gets competitive results with faster inference for single-step generation. Using 4 same-sized students, MSD sets a new state-of-the-art for one-step image generation: FID 1.20 on ImageNet-64x64 and 8.20 on zero-shot COCO2014.
SpaceMesh: A Continuous Representation for Learning Manifold Surface Meshes
Sep 30, 2024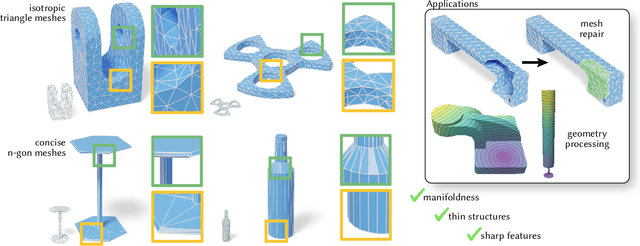
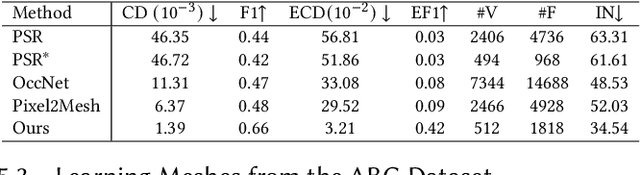
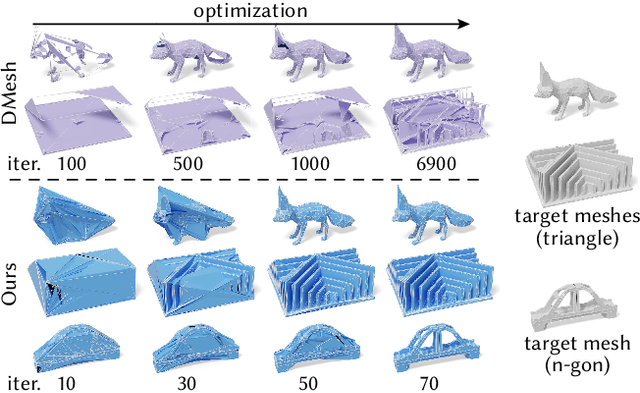

Meshes are ubiquitous in visual computing and simulation, yet most existing machine learning techniques represent meshes only indirectly, e.g. as the level set of a scalar field or deformation of a template, or as a disordered triangle soup lacking local structure. This work presents a scheme to directly generate manifold, polygonal meshes of complex connectivity as the output of a neural network. Our key innovation is to define a continuous latent connectivity space at each mesh vertex, which implies the discrete mesh. In particular, our vertex embeddings generate cyclic neighbor relationships in a halfedge mesh representation, which gives a guarantee of edge-manifoldness and the ability to represent general polygonal meshes. This representation is well-suited to machine learning and stochastic optimization, without restriction on connectivity or topology. We first explore the basic properties of this representation, then use it to fit distributions of meshes from large datasets. The resulting models generate diverse meshes with tessellation structure learned from the dataset population, with concise details and high-quality mesh elements. In applications, this approach not only yields high-quality outputs from generative models, but also enables directly learning challenging geometry processing tasks such as mesh repair.
Improving Hyperparameter Optimization with Checkpointed Model Weights
Jun 26, 2024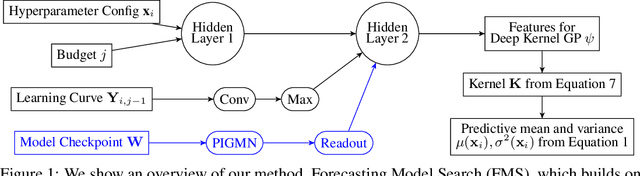
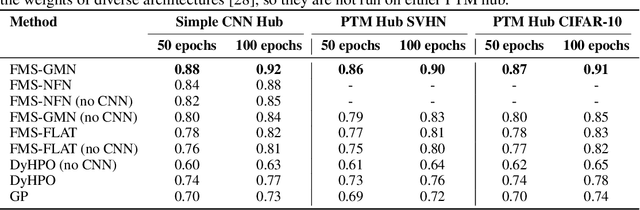
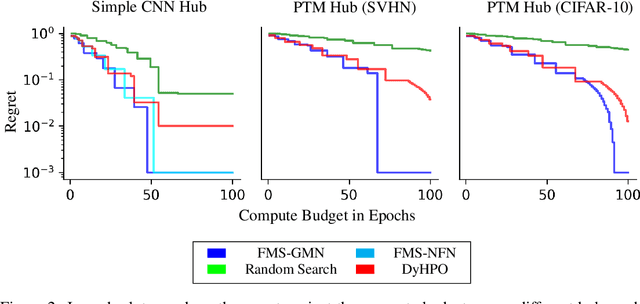

When training deep learning models, the performance depends largely on the selected hyperparameters. However, hyperparameter optimization (HPO) is often one of the most expensive parts of model design. Classical HPO methods treat this as a black-box optimization problem. However, gray-box HPO methods, which incorporate more information about the setup, have emerged as a promising direction for more efficient optimization. For example, using intermediate loss evaluations to terminate bad selections. In this work, we propose an HPO method for neural networks using logged checkpoints of the trained weights to guide future hyperparameter selections. Our method, Forecasting Model Search (FMS), embeds weights into a Gaussian process deep kernel surrogate model, using a permutation-invariant graph metanetwork to be data-efficient with the logged network weights. To facilitate reproducibility and further research, we open-source our code at https://github.com/NVlabs/forecasting-model-search.
LATTE3D: Large-scale Amortized Text-To-Enhanced3D Synthesis
Mar 22, 2024


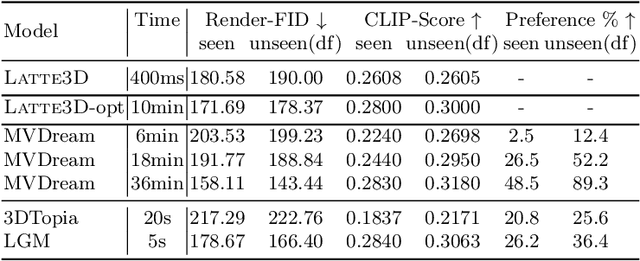
Recent text-to-3D generation approaches produce impressive 3D results but require time-consuming optimization that can take up to an hour per prompt. Amortized methods like ATT3D optimize multiple prompts simultaneously to improve efficiency, enabling fast text-to-3D synthesis. However, they cannot capture high-frequency geometry and texture details and struggle to scale to large prompt sets, so they generalize poorly. We introduce LATTE3D, addressing these limitations to achieve fast, high-quality generation on a significantly larger prompt set. Key to our method is 1) building a scalable architecture and 2) leveraging 3D data during optimization through 3D-aware diffusion priors, shape regularization, and model initialization to achieve robustness to diverse and complex training prompts. LATTE3D amortizes both neural field and textured surface generation to produce highly detailed textured meshes in a single forward pass. LATTE3D generates 3D objects in 400ms, and can be further enhanced with fast test-time optimization.
Graph Metanetworks for Processing Diverse Neural Architectures
Dec 07, 2023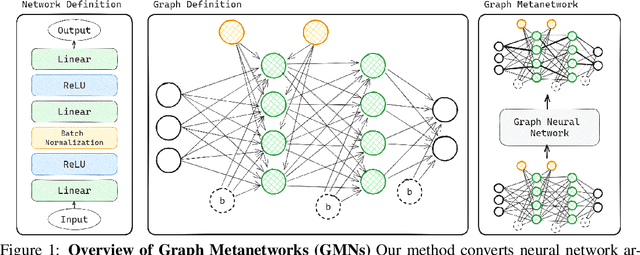
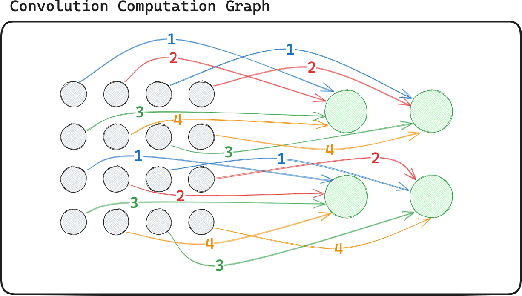
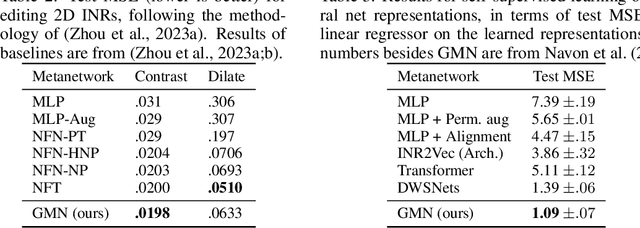
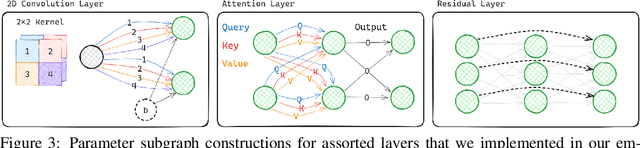
Neural networks efficiently encode learned information within their parameters. Consequently, many tasks can be unified by treating neural networks themselves as input data. When doing so, recent studies demonstrated the importance of accounting for the symmetries and geometry of parameter spaces. However, those works developed architectures tailored to specific networks such as MLPs and CNNs without normalization layers, and generalizing such architectures to other types of networks can be challenging. In this work, we overcome these challenges by building new metanetworks - neural networks that take weights from other neural networks as input. Put simply, we carefully build graphs representing the input neural networks and process the graphs using graph neural networks. Our approach, Graph Metanetworks (GMNs), generalizes to neural architectures where competing methods struggle, such as multi-head attention layers, normalization layers, convolutional layers, ResNet blocks, and group-equivariant linear layers. We prove that GMNs are expressive and equivariant to parameter permutation symmetries that leave the input neural network functions unchanged. We validate the effectiveness of our method on several metanetwork tasks over diverse neural network architectures.
ATT3D: Amortized Text-to-3D Object Synthesis
Jun 06, 2023



Text-to-3D modelling has seen exciting progress by combining generative text-to-image models with image-to-3D methods like Neural Radiance Fields. DreamFusion recently achieved high-quality results but requires a lengthy, per-prompt optimization to create 3D objects. To address this, we amortize optimization over text prompts by training on many prompts simultaneously with a unified model, instead of separately. With this, we share computation across a prompt set, training in less time than per-prompt optimization. Our framework - Amortized text-to-3D (ATT3D) - enables knowledge-sharing between prompts to generalize to unseen setups and smooth interpolations between text for novel assets and simple animations.