 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny-Subgroup Equivariant Networks via Symmetry Breaking
Mar 19, 2026The inclusion of symmetries as an inductive bias, known as equivariance, often improves generalization on geometric data (e.g. grids, sets, and graphs). However, equivariant architectures are usually highly constrained, designed for symmetries chosen a priori, and not applicable to datasets with other symmetries. This precludes the development of flexible, multi-modal foundation models capable of processing diverse data equivariantly. In this work, we build a single model -- the Any-Subgroup Equivariant Network (ASEN) -- that can be simultaneously equivariant to several groups, simply by modulating a certain auxiliary input feature. In particular, we start with a fully permutation-equivariant base model, and then obtain subgroup equivariance by using a symmetry-breaking input whose automorphism group is that subgroup. However, finding an input with the desired automorphism group is computationally hard. We overcome this by relaxing from exact to approximate symmetry breaking, leveraging the notion of 2-closure to derive fast algorithms. Theoretically, we show that our subgroup-equivariant networks can simulate equivariant MLPs, and their universality can be guaranteed if the base model is universal. Empirically, we validate our method on symmetry selection for graph and image tasks, as well as multitask and transfer learning for sequence tasks, showing that a single network equivariant to multiple permutation subgroups outperforms both separate equivariant models and a single non-equivariant model.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Learning on LLM Output Signatures for gray-box LLM Behavior Analysis
Mar 18, 2025Large Language Models (LLMs) have achieved widespread adoption, yet our understanding of their behavior remains limited, particularly in detecting data contamination and hallucinations. While recently proposed probing techniques provide insights through activation analysis, they require "white-box" access to model internals, often unavailable. Current "gray-box" approaches typically analyze only the probability of the actual tokens in the sequence with simple task-specific heuristics. Importantly, these methods overlook the rich information contained in the full token distribution at each processing step. To address these limitations, we propose that gray-box analysis should leverage the complete observable output of LLMs, consisting of both the previously used token probabilities as well as the complete token distribution sequences - a unified data type we term LOS (LLM Output Signature). To this end, we develop a transformer-based approach to process LOS that theoretically guarantees approximation of existing techniques while enabling more nuanced analysis. Our approach achieves superior performance on hallucination and data contamination detection in gray-box settings, significantly outperforming existing baselines. Furthermore, it demonstrates strong transfer capabilities across datasets and LLMs, suggesting that LOS captures fundamental patterns in LLM behavior. Our code is available at: https://github.com/BarSGuy/LLM-Output-Signatures-Network.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Learning on LoRAs: GL-Equivariant Processing of Low-Rank Weight Spaces for Large Finetuned Models
Oct 05, 2024



Low-rank adaptations (LoRAs) have revolutionized the finetuning of large foundation models, enabling efficient adaptation even with limited computational resources. The resulting proliferation of LoRAs presents exciting opportunities for applying machine learning techniques that take these low-rank weights themselves as inputs. In this paper, we investigate the potential of Learning on LoRAs (LoL), a paradigm where LoRA weights serve as input to machine learning models. For instance, an LoL model that takes in LoRA weights as inputs could predict the performance of the finetuned model on downstream tasks, detect potentially harmful finetunes, or even generate novel model edits without traditional training methods. We first identify the inherent parameter symmetries of low rank decompositions of weights, which differ significantly from the parameter symmetries of standard neural networks. To efficiently process LoRA weights, we develop several symmetry-aware invariant or equivariant LoL models, using tools such as canonicalization, invariant featurization, and equivariant layers. We finetune thousands of text-to-image diffusion models and language models to collect datasets of LoRAs. In numerical experiments on these datasets, we show that our LoL architectures are capable of processing low rank weight decompositions to predict CLIP score, finetuning data attributes, finetuning data membership, and accuracy on downstream tasks.
The Empirical Impact of Neural Parameter Symmetries, or Lack Thereof
May 30, 2024



Many algorithms and observed phenomena in deep learning appear to be affected by parameter symmetries -- transformations of neural network parameters that do not change the underlying neural network function. These include linear mode connectivity, model merging, Bayesian neural network inference, metanetworks, and several other characteristics of optimization or loss-landscapes. However, theoretical analysis of the relationship between parameter space symmetries and these phenomena is difficult. In this work, we empirically investigate the impact of neural parameter symmetries by introducing new neural network architectures that have reduced parameter space symmetries. We develop two methods, with some provable guarantees, of modifying standard neural networks to reduce parameter space symmetries. With these new methods, we conduct a comprehensive experimental study consisting of multiple tasks aimed at assessing the effect of removing parameter symmetries. Our experiments reveal several interesting observations on the empirical impact of parameter symmetries; for instance, we observe linear mode connectivity between our networks without alignment of weight spaces, and we find that our networks allow for faster and more effective Bayesian neural network training.
A Canonization Perspective on Invariant and Equivariant Learning
May 29, 2024



In many applications, we desire neural networks to exhibit invariance or equivariance to certain groups due to symmetries inherent in the data. Recently, frame-averaging methods emerged to be a unified framework for attaining symmetries efficiently by averaging over input-dependent subsets of the group, i.e., frames. What we currently lack is a principled understanding of the design of frames. In this work, we introduce a canonization perspective that provides an essential and complete view of the design of frames. Canonization is a classic approach for attaining invariance by mapping inputs to their canonical forms. We show that there exists an inherent connection between frames and canonical forms. Leveraging this connection, we can efficiently compare the complexity of frames as well as determine the optimality of certain frames. Guided by this principle, we design novel frames for eigenvectors that are strictly superior to existing methods -- some are even optimal -- both theoretically and empirically. The reduction to the canonization perspective further uncovers equivalences between previous methods. These observations suggest that canonization provides a fundamental understanding of existing frame-averaging methods and unifies existing equivariant and invariant learning methods.
Future Directions in Foundations of Graph Machine Learning
Feb 03, 2024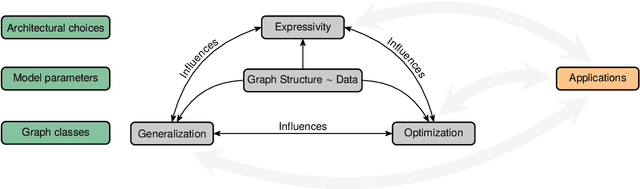
Machine learning on graphs, especially using graph neural networks (GNNs), has seen a surge in interest due to the wide availability of graph data across a broad spectrum of disciplines, from life to social and engineering sciences. Despite their practical success, our theoretical understanding of the properties of GNNs remains highly incomplete. Recent theoretical advancements primarily focus on elucidating the coarse-grained expressive power of GNNs, predominantly employing combinatorial techniques. However, these studies do not perfectly align with practice, particularly in understanding the generalization behavior of GNNs when trained with stochastic first-order optimization techniques. In this position paper, we argue that the graph machine learning community needs to shift its attention to developing a more balanced theory of graph machine learning, focusing on a more thorough understanding of the interplay of expressive power, generalization, and optimization.
Graph Metanetworks for Processing Diverse Neural Architectures
Dec 07, 2023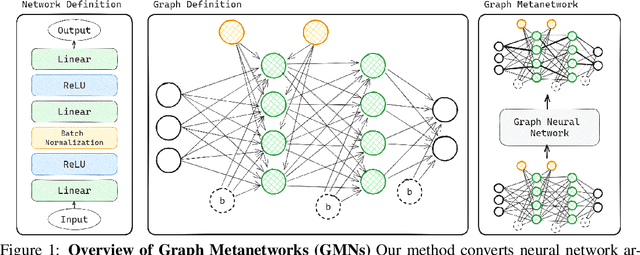
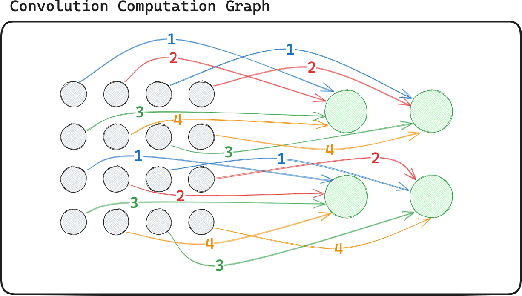
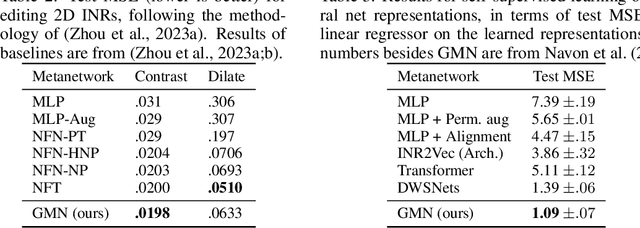
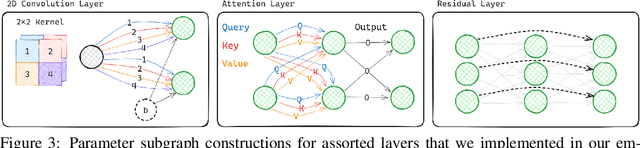
Neural networks efficiently encode learned information within their parameters. Consequently, many tasks can be unified by treating neural networks themselves as input data. When doing so, recent studies demonstrated the importance of accounting for the symmetries and geometry of parameter spaces. However, those works developed architectures tailored to specific networks such as MLPs and CNNs without normalization layers, and generalizing such architectures to other types of networks can be challenging. In this work, we overcome these challenges by building new metanetworks - neural networks that take weights from other neural networks as input. Put simply, we carefully build graphs representing the input neural networks and process the graphs using graph neural networks. Our approach, Graph Metanetworks (GMNs), generalizes to neural architectures where competing methods struggle, such as multi-head attention layers, normalization layers, convolutional layers, ResNet blocks, and group-equivariant linear layers. We prove that GMNs are expressive and equivariant to parameter permutation symmetries that leave the input neural network functions unchanged. We validate the effectiveness of our method on several metanetwork tasks over diverse neural network architectures.
Expressive Sign Equivariant Networks for Spectral Geometric Learning
Dec 04, 2023Recent work has shown the utility of developing machine learning models that respect the structure and symmetries of eigenvectors. These works promote sign invariance, since for any eigenvector v the negation -v is also an eigenvector. However, we show that sign invariance is theoretically limited for tasks such as building orthogonally equivariant models and learning node positional encodings for link prediction in graphs. In this work, we demonstrate the benefits of sign equivariance for these tasks. To obtain these benefits, we develop novel sign equivariant neural network architectures. Our models are based on a new analytic characterization of sign equivariant polynomials and thus inherit provable expressiveness properties. Controlled synthetic experiments show that our networks can achieve the theoretically predicted benefits of sign equivariant models. Code is available at https://github.com/cptq/Sign-Equivariant-Nets.