 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Deployment Improves Planning Skills in LLMs
Dec 31, 2025We show that iterative deployment of large language models (LLMs), each fine-tuned on data carefully curated by users from the previous models' deployment, can significantly change the properties of the resultant models. By testing this mechanism on various planning domains, we observe substantial improvements in planning skills, with later models displaying emergent generalization by discovering much longer plans than the initial models. We then provide theoretical analysis showing that iterative deployment effectively implements reinforcement learning (RL) training in the outer-loop (i.e. not as part of intentional model training), with an implicit reward function. The connection to RL has two important implications: first, for the field of AI safety, as the reward function entailed by repeated deployment is not defined explicitly, and could have unexpected implications to the properties of future model deployments. Second, the mechanism highlighted here can be viewed as an alternative training regime to explicit RL, relying on data curation rather than explicit rewards.
Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings
Dec 13, 2025



So far, expensive finetuning beyond the pretraining sequence length has been a requirement for effectively extending the context of language models (LM). In this work, we break this key bottleneck by Dropping the Positional Embeddings of LMs after training (DroPE). Our simple method is motivated by three key theoretical and empirical observations. First, positional embeddings (PEs) serve a crucial role during pretraining, providing an important inductive bias that significantly facilitates convergence. Second, over-reliance on this explicit positional information is also precisely what prevents test-time generalization to sequences of unseen length, even when using popular PE-scaling methods. Third, positional embeddings are not an inherent requirement of effective language modeling and can be safely removed after pretraining, following a short recalibration phase. Empirically, DroPE yields seamless zero-shot context extension without any long-context finetuning, quickly adapting pretrained LMs without compromising their capabilities in the original training context. Our findings hold across different models and dataset sizes, far outperforming previous specialized architectures and established rotary positional embedding scaling methods.
GradMetaNet: An Equivariant Architecture for Learning on Gradients
Jul 02, 2025Gradients of neural networks encode valuable information for optimization, editing, and analysis of models. Therefore, practitioners often treat gradients as inputs to task-specific algorithms, e.g. for pruning or optimization. Recent works explore learning algorithms that operate directly on gradients but use architectures that are not specifically designed for gradient processing, limiting their applicability. In this paper, we present a principled approach for designing architectures that process gradients. Our approach is guided by three principles: (1) equivariant design that preserves neuron permutation symmetries, (2) processing sets of gradients across multiple data points to capture curvature information, and (3) efficient gradient representation through rank-1 decomposition. Based on these principles, we introduce GradMetaNet, a novel architecture for learning on gradients, constructed from simple equivariant blocks. We prove universality results for GradMetaNet, and show that previous approaches cannot approximate natural gradient-based functions that GradMetaNet can. We then demonstrate GradMetaNet's effectiveness on a diverse set of gradient-based tasks on MLPs and transformers, such as learned optimization, INR editing, and estimating loss landscape curvature.
Learning on LLM Output Signatures for gray-box LLM Behavior Analysis
Mar 18, 2025Large Language Models (LLMs) have achieved widespread adoption, yet our understanding of their behavior remains limited, particularly in detecting data contamination and hallucinations. While recently proposed probing techniques provide insights through activation analysis, they require "white-box" access to model internals, often unavailable. Current "gray-box" approaches typically analyze only the probability of the actual tokens in the sequence with simple task-specific heuristics. Importantly, these methods overlook the rich information contained in the full token distribution at each processing step. To address these limitations, we propose that gray-box analysis should leverage the complete observable output of LLMs, consisting of both the previously used token probabilities as well as the complete token distribution sequences - a unified data type we term LOS (LLM Output Signature). To this end, we develop a transformer-based approach to process LOS that theoretically guarantees approximation of existing techniques while enabling more nuanced analysis. Our approach achieves superior performance on hallucination and data contamination detection in gray-box settings, significantly outperforming existing baselines. Furthermore, it demonstrates strong transfer capabilities across datasets and LLMs, suggesting that LOS captures fundamental patterns in LLM behavior. Our code is available at: https://github.com/BarSGuy/LLM-Output-Signatures-Network.
Learning on LoRAs: GL-Equivariant Processing of Low-Rank Weight Spaces for Large Finetuned Models
Oct 05, 2024Low-rank adaptations (LoRAs) have revolutionized the finetuning of large foundation models, enabling efficient adaptation even with limited computational resources. The resulting proliferation of LoRAs presents exciting opportunities for applying machine learning techniques that take these low-rank weights themselves as inputs. In this paper, we investigate the potential of Learning on LoRAs (LoL), a paradigm where LoRA weights serve as input to machine learning models. For instance, an LoL model that takes in LoRA weights as inputs could predict the performance of the finetuned model on downstream tasks, detect potentially harmful finetunes, or even generate novel model edits without traditional training methods. We first identify the inherent parameter symmetries of low rank decompositions of weights, which differ significantly from the parameter symmetries of standard neural networks. To efficiently process LoRA weights, we develop several symmetry-aware invariant or equivariant LoL models, using tools such as canonicalization, invariant featurization, and equivariant layers. We finetune thousands of text-to-image diffusion models and language models to collect datasets of LoRAs. In numerical experiments on these datasets, we show that our LoL architectures are capable of processing low rank weight decompositions to predict CLIP score, finetuning data attributes, finetuning data membership, and accuracy on downstream tasks.
Variational Inference Failures Under Model Symmetries: Permutation Invariant Posteriors for Bayesian Neural Networks
Aug 10, 2024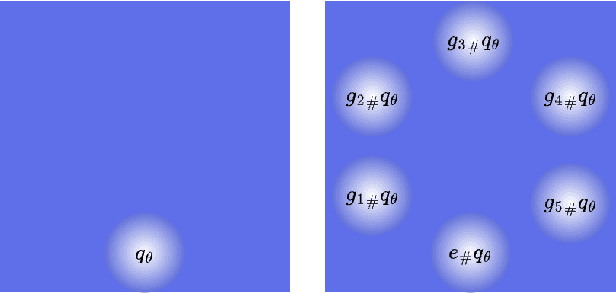

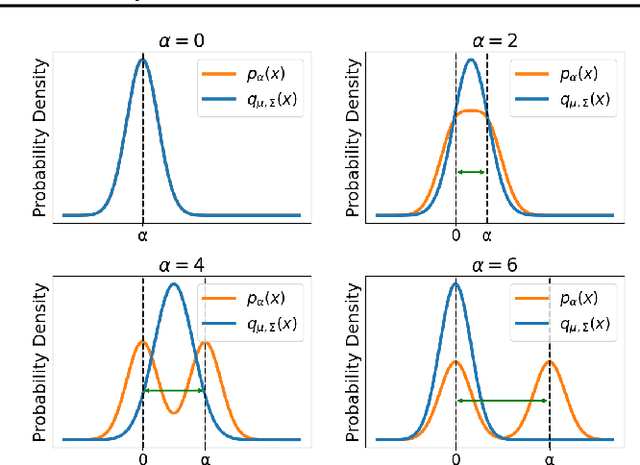
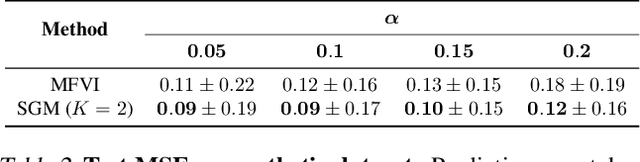
Weight space symmetries in neural network architectures, such as permutation symmetries in MLPs, give rise to Bayesian neural network (BNN) posteriors with many equivalent modes. This multimodality poses a challenge for variational inference (VI) techniques, which typically rely on approximating the posterior with a unimodal distribution. In this work, we investigate the impact of weight space permutation symmetries on VI. We demonstrate, both theoretically and empirically, that these symmetries lead to biases in the approximate posterior, which degrade predictive performance and posterior fit if not explicitly accounted for. To mitigate this behavior, we leverage the symmetric structure of the posterior and devise a symmetrization mechanism for constructing permutation invariant variational posteriors. We show that the symmetrized distribution has a strictly better fit to the true posterior, and that it can be trained using the original ELBO objective with a modified KL regularization term. We demonstrate experimentally that our approach mitigates the aforementioned biases and results in improved predictions and a higher ELBO.
Topological Blind Spots: Understanding and Extending Topological Deep Learning Through the Lens of Expressivity
Aug 10, 2024Topological deep learning (TDL) facilitates learning from data represented by topological structures. The primary model utilized in this setting is higher-order message-passing (HOMP), which extends traditional graph message-passing neural networks (MPNN) to diverse topological domains. Given the significant expressivity limitations of MPNNs, our paper aims to explore both the strengths and weaknesses of HOMP's expressive power and subsequently design novel architectures to address these limitations. We approach this from several perspectives: First, we demonstrate HOMP's inability to distinguish between topological objects based on fundamental topological and metric properties such as diameter, orientability, planarity, and homology. Second, we show HOMP's limitations in fully leveraging the topological structure of objects constructed using common lifting and pooling operators on graphs. Finally, we compare HOMP's expressive power to hypergraph networks, which are the most extensively studied TDL methods. We then develop two new classes of TDL models: multi-cellular networks (MCN) and scalable multi-cellular networks (SMCN). These models draw inspiration from expressive graph architectures. While MCN can reach full expressivity but is highly unscalable, SMCN offers a more scalable alternative that still mitigates many of HOMP's expressivity limitations. Finally, we construct a synthetic dataset, where TDL models are tasked with separating pairs of topological objects based on basic topological properties. We demonstrate that while HOMP is unable to distinguish between any of the pairs in the dataset, SMCN successfully distinguishes all pairs, empirically validating our theoretical findings. Our work opens a new design space and new opportunities for TDL, paving the way for more expressive and versatile models.