 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Weight Space Learning: Understanding, Representation, and Generation
Mar 10, 2026Neural network weights are typically viewed as the end product of training, while most deep learning research focuses on data, features, and architectures. However, recent advances show that the set of all possible weight values (weight space) itself contains rich structure: pretrained models form organized distributions, exhibit symmetries, and can be embedded, compared, or even generated. Understanding such structures has tremendous impact on how neural networks are analyzed and compared, and on how knowledge is transferred across models, beyond individual training instances. This emerging research direction, which we refer to as Weight Space Learning (WSL), treats neural weights as a meaningful domain for analysis and modeling. This survey provides the first unified taxonomy of WSL. We categorize existing methods into three core dimensions: Weight Space Understanding (WSU), which studies the geometry and symmetries of weights; Weight Space Representation (WSR), which learns embeddings over model weights; and Weight Space Generation (WSG), which synthesizes new weights through hypernetworks or generative models. We further show how these developments enable practical applications, including model retrieval, continual and federated learning, neural architecture search, and data-free reconstruction. By consolidating fragmented progress under a coherent framework, this survey highlights weight space as a learnable, structured domain with growing impact across model analysis, transferring, and weight generation. We release an accompanying resource at https://github.com/Zehong-Wang/Awesome-Weight-Space-Learning.
A Graph Meta-Network for Learning on Kolmogorov-Arnold Networks
Feb 18, 2026Weight-space models learn directly from the parameters of neural networks, enabling tasks such as predicting their accuracy on new datasets. Naive methods -- like applying MLPs to flattened parameters -- perform poorly, making the design of better weight-space architectures a central challenge. While prior work leveraged permutation symmetries in standard networks to guide such designs, no analogous analysis or tailored architecture yet exists for Kolmogorov-Arnold Networks (KANs). In this work, we show that KANs share the same permutation symmetries as MLPs, and propose the KAN-graph, a graph representation of their computation. Building on this, we develop WS-KAN, the first weight-space architecture that learns on KANs, which naturally accounts for their symmetry. We analyze WS-KAN's expressive power, showing it can replicate an input KAN's forward pass - a standard approach for assessing expressiveness in weight-space architectures. We construct a comprehensive ``zoo'' of trained KANs spanning diverse tasks, which we use as benchmarks to empirically evaluate WS-KAN. Across all tasks, WS-KAN consistently outperforms structure-agnostic baselines, often by a substantial margin. Our code is available at https://github.com/BarSGuy/KAN-Graph-Metanetwork.
Spanning the Visual Analogy Space with a Weight Basis of LoRAs
Feb 17, 2026Visual analogy learning enables image manipulation through demonstration rather than textual description, allowing users to specify complex transformations difficult to articulate in words. Given a triplet $\{\mathbf{a}$, $\mathbf{a}'$, $\mathbf{b}\}$, the goal is to generate $\mathbf{b}'$ such that $\mathbf{a} : \mathbf{a}' :: \mathbf{b} : \mathbf{b}'$. Recent methods adapt text-to-image models to this task using a single Low-Rank Adaptation (LoRA) module, but they face a fundamental limitation: attempting to capture the diverse space of visual transformations within a fixed adaptation module constrains generalization capabilities. Inspired by recent work showing that LoRAs in constrained domains span meaningful, interpolatable semantic spaces, we propose LoRWeB, a novel approach that specializes the model for each analogy task at inference time through dynamic composition of learned transformation primitives, informally, choosing a point in a "space of LoRAs". We introduce two key components: (1) a learnable basis of LoRA modules, to span the space of different visual transformations, and (2) a lightweight encoder that dynamically selects and weighs these basis LoRAs based on the input analogy pair. Comprehensive evaluations demonstrate our approach achieves state-of-the-art performance and significantly improves generalization to unseen visual transformations. Our findings suggest that LoRA basis decompositions are a promising direction for flexible visual manipulation. Code and data are in https://research.nvidia.com/labs/par/lorweb
SHINE: A Scalable In-Context Hypernetwork for Mapping Context to LoRA in a Single Pass
Feb 06, 2026We propose SHINE (Scalable Hyper In-context NEtwork), a scalable hypernetwork that can map diverse meaningful contexts into high-quality LoRA adapters for large language models (LLM). By reusing the frozen LLM's own parameters in an in-context hypernetwork design and introducing architectural innovations, SHINE overcomes key limitations of prior hypernetworks and achieves strong expressive power with a relatively small number of parameters. We introduce a pretraining and instruction fine-tuning pipeline, and train our hypernetwork to generate high quality LoRA adapters from diverse meaningful contexts in a single forward pass. It updates LLM parameters without any fine-tuning, and immediately enables complex question answering tasks related to the context without directly accessing the context, effectively transforming in-context knowledge to in-parameter knowledge in one pass. Our work achieves outstanding results on various tasks, greatly saves time, computation and memory costs compared to SFT-based LLM adaptation, and shows great potential for scaling. Our code is available at https://github.com/Yewei-Liu/SHINE
On the Expressive Power of Permutation-Equivariant Weight-Space Networks
Feb 01, 2026Weight-space learning studies neural architectures that operate directly on the parameters of other neural networks. Motivated by the growing availability of pretrained models, recent work has demonstrated the effectiveness of weight-space networks across a wide range of tasks. SOTA weight-space networks rely on permutation-equivariant designs to improve generalization. However, this may negatively affect expressive power, warranting theoretical investigation. Importantly, unlike other structured domains, weight-space learning targets maps operating on both weight and function spaces, making expressivity analysis particularly subtle. While a few prior works provide partial expressivity results, a comprehensive characterization is still missing. In this work, we address this gap by developing a systematic theory for expressivity of weight-space networks. We first prove that all prominent permutation-equivariant networks are equivalent in expressive power. We then establish universality in both weight- and function-space settings under mild, natural assumptions on the input weights, and characterize the edge-case regimes where universality no longer holds. Together, these results provide a strong and unified foundation for the expressivity of weight-space networks.
Learning from Historical Activations in Graph Neural Networks
Jan 03, 2026Graph Neural Networks (GNNs) have demonstrated remarkable success in various domains such as social networks, molecular chemistry, and more. A crucial component of GNNs is the pooling procedure, in which the node features calculated by the model are combined to form an informative final descriptor to be used for the downstream task. However, previous graph pooling schemes rely on the last GNN layer features as an input to the pooling or classifier layers, potentially under-utilizing important activations of previous layers produced during the forward pass of the model, which we regard as historical graph activations. This gap is particularly pronounced in cases where a node's representation can shift significantly over the course of many graph neural layers, and worsened by graph-specific challenges such as over-smoothing in deep architectures. To bridge this gap, we introduce HISTOGRAPH, a novel two-stage attention-based final aggregation layer that first applies a unified layer-wise attention over intermediate activations, followed by node-wise attention. By modeling the evolution of node representations across layers, our HISTOGRAPH leverages both the activation history of nodes and the graph structure to refine features used for final prediction. Empirical results on multiple graph classification benchmarks demonstrate that HISTOGRAPH offers strong performance that consistently improves traditional techniques, with particularly strong robustness in deep GNNs.
GradMetaNet: An Equivariant Architecture for Learning on Gradients
Jul 02, 2025Gradients of neural networks encode valuable information for optimization, editing, and analysis of models. Therefore, practitioners often treat gradients as inputs to task-specific algorithms, e.g. for pruning or optimization. Recent works explore learning algorithms that operate directly on gradients but use architectures that are not specifically designed for gradient processing, limiting their applicability. In this paper, we present a principled approach for designing architectures that process gradients. Our approach is guided by three principles: (1) equivariant design that preserves neuron permutation symmetries, (2) processing sets of gradients across multiple data points to capture curvature information, and (3) efficient gradient representation through rank-1 decomposition. Based on these principles, we introduce GradMetaNet, a novel architecture for learning on gradients, constructed from simple equivariant blocks. We prove universality results for GradMetaNet, and show that previous approaches cannot approximate natural gradient-based functions that GradMetaNet can. We then demonstrate GradMetaNet's effectiveness on a diverse set of gradient-based tasks on MLPs and transformers, such as learned optimization, INR editing, and estimating loss landscape curvature.
It Takes a Graph to Know a Graph: Rewiring for Homophily with a Reference Graph
May 18, 2025Graph Neural Networks (GNNs) excel at analyzing graph-structured data but struggle on heterophilic graphs, where connected nodes often belong to different classes. While this challenge is commonly addressed with specialized GNN architectures, graph rewiring remains an underexplored strategy in this context. We provide theoretical foundations linking edge homophily, GNN embedding smoothness, and node classification performance, motivating the need to enhance homophily. Building on this insight, we introduce a rewiring framework that increases graph homophily using a reference graph, with theoretical guarantees on the homophily of the rewired graph. To broaden applicability, we propose a label-driven diffusion approach for constructing a homophilic reference graph from node features and training labels. Through extensive simulations, we analyze how the homophily of both the original and reference graphs influences the rewired graph homophily and downstream GNN performance. We evaluate our method on 11 real-world heterophilic datasets and show that it outperforms existing rewiring techniques and specialized GNNs for heterophilic graphs, achieving improved node classification accuracy while remaining efficient and scalable to large graphs.
Efficient GNN Training Through Structure-Aware Randomized Mini-Batching
Apr 25, 2025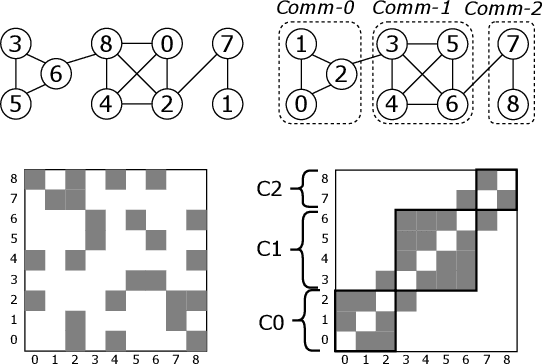

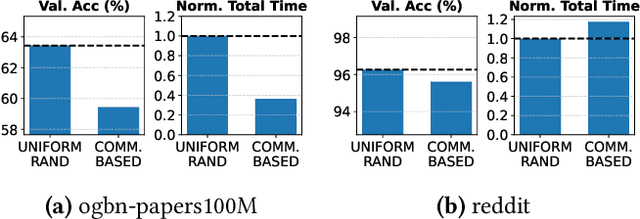
Graph Neural Networks (GNNs) enable learning on realworld graphs and mini-batch training has emerged as the de facto standard for training GNNs because it can scale to very large graphs and improve convergence. Current mini-batch construction policies largely ignore efficiency considerations of GNN training. Specifically, existing mini-batching techniques employ randomization schemes to improve accuracy and convergence. However, these randomization schemes are often agnostic to the structural properties of the graph (for eg. community structure), resulting in highly irregular memory access patterns during GNN training that make suboptimal use of on-chip GPU caches. On the other hand, while deterministic mini-batching based solely on graph structure delivers fast runtime performance, the lack of randomness compromises both the final model accuracy and training convergence speed. In this paper, we present Community-structure-aware Randomized Mini-batching (COMM-RAND), a novel methodology that bridges the gap between the above extremes. COMM-RAND allows practitioners to explore the space between pure randomness and pure graph structural awareness during mini-batch construction, leading to significantly more efficient GNN training with similar accuracy. We evaluated COMM-RAND across four popular graph learning benchmarks. COMM-RAND cuts down GNN training time by up to 2.76x (1.8x on average) while achieving an accuracy that is within 1.79% points (0.42% on average) compared to popular random mini-batching approaches.
Learning on LLM Output Signatures for gray-box LLM Behavior Analysis
Mar 18, 2025Large Language Models (LLMs) have achieved widespread adoption, yet our understanding of their behavior remains limited, particularly in detecting data contamination and hallucinations. While recently proposed probing techniques provide insights through activation analysis, they require "white-box" access to model internals, often unavailable. Current "gray-box" approaches typically analyze only the probability of the actual tokens in the sequence with simple task-specific heuristics. Importantly, these methods overlook the rich information contained in the full token distribution at each processing step. To address these limitations, we propose that gray-box analysis should leverage the complete observable output of LLMs, consisting of both the previously used token probabilities as well as the complete token distribution sequences - a unified data type we term LOS (LLM Output Signature). To this end, we develop a transformer-based approach to process LOS that theoretically guarantees approximation of existing techniques while enabling more nuanced analysis. Our approach achieves superior performance on hallucination and data contamination detection in gray-box settings, significantly outperforming existing baselines. Furthermore, it demonstrates strong transfer capabilities across datasets and LLMs, suggesting that LOS captures fundamental patterns in LLM behavior. Our code is available at: https://github.com/BarSGuy/LLM-Output-Signatures-Network.