 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoldable SuperNets: Scalable Merging of Transformers with Different Initializations and Tasks
Paper and Code
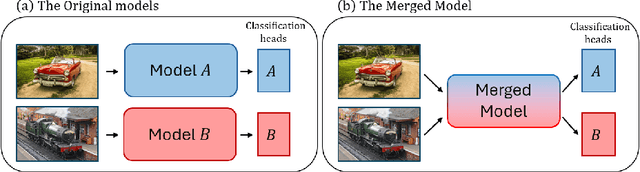
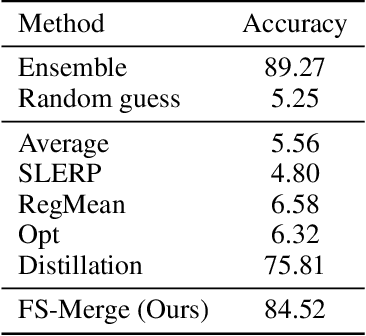
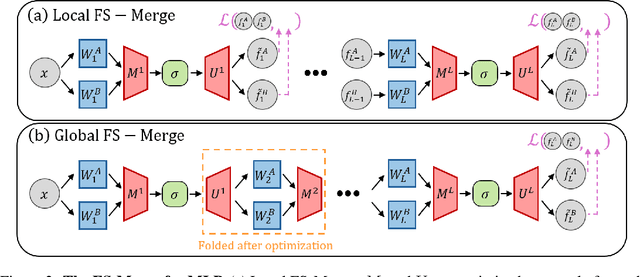
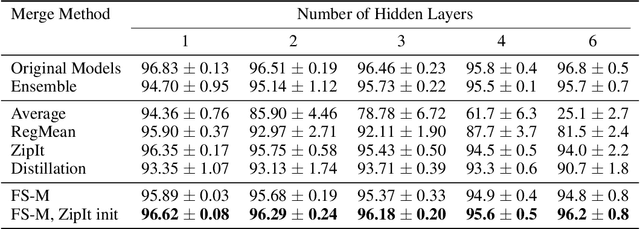
Many recent methods aim to merge neural networks (NNs) with identical architectures trained on different tasks to obtain a single multi-task model. Most existing works tackle the simpler setup of merging NNs initialized from a common pre-trained network, where simple heuristics like weight averaging work well. This work targets a more challenging goal: merging large transformers trained on different tasks from distinct initializations. First, we demonstrate that traditional merging methods fail catastrophically in this setup. To overcome this challenge, we propose Foldable SuperNet Merge (FS-Merge), a method that optimizes a SuperNet to fuse the original models using a feature reconstruction loss. FS-Merge is simple, data-efficient, and capable of merging models of varying widths. We test FS-Merge against existing methods, including knowledge distillation, on MLPs and transformers across various settings, sizes, tasks, and modalities. FS-Merge consistently outperforms them, achieving SOTA results, particularly in limited data scenarios.