 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
FFN Fusion: Rethinking Sequential Computation in Large Language Models
Mar 24, 2025We introduce FFN Fusion, an architectural optimization technique that reduces sequential computation in large language models by identifying and exploiting natural opportunities for parallelization. Our key insight is that sequences of Feed-Forward Network (FFN) layers, particularly those remaining after the removal of specific attention layers, can often be parallelized with minimal accuracy impact. We develop a principled methodology for identifying and fusing such sequences, transforming them into parallel operations that significantly reduce inference latency while preserving model behavior. Applying these techniques to Llama-3.1-405B-Instruct, we create Llama-Nemotron-Ultra-253B-Base (Ultra-253B-Base), an efficient and soon-to-be publicly available model that achieves a 1.71X speedup in inference latency and 35X lower per-token cost while maintaining strong performance across benchmarks. Through extensive experiments on models from 49B to 253B parameters, we demonstrate that FFN Fusion becomes increasingly effective at larger scales and can complement existing optimization techniques like quantization and pruning. Most intriguingly, we find that even full transformer blocks containing both attention and FFN layers can sometimes be parallelized, suggesting new directions for neural architecture design.
Learning on LLM Output Signatures for gray-box LLM Behavior Analysis
Mar 18, 2025Large Language Models (LLMs) have achieved widespread adoption, yet our understanding of their behavior remains limited, particularly in detecting data contamination and hallucinations. While recently proposed probing techniques provide insights through activation analysis, they require "white-box" access to model internals, often unavailable. Current "gray-box" approaches typically analyze only the probability of the actual tokens in the sequence with simple task-specific heuristics. Importantly, these methods overlook the rich information contained in the full token distribution at each processing step. To address these limitations, we propose that gray-box analysis should leverage the complete observable output of LLMs, consisting of both the previously used token probabilities as well as the complete token distribution sequences - a unified data type we term LOS (LLM Output Signature). To this end, we develop a transformer-based approach to process LOS that theoretically guarantees approximation of existing techniques while enabling more nuanced analysis. Our approach achieves superior performance on hallucination and data contamination detection in gray-box settings, significantly outperforming existing baselines. Furthermore, it demonstrates strong transfer capabilities across datasets and LLMs, suggesting that LOS captures fundamental patterns in LLM behavior. Our code is available at: https://github.com/BarSGuy/LLM-Output-Signatures-Network.
No Data, No Optimization: A Lightweight Method To Disrupt Neural Networks With Sign-Flips
Feb 11, 2025Deep Neural Networks (DNNs) can be catastrophically disrupted by flipping only a handful of sign bits in their parameters. We introduce Deep Neural Lesion (DNL), a data-free, lightweight method that locates these critical parameters and triggers massive accuracy drops. We validate its efficacy on a wide variety of computer vision models and datasets. The method requires no training data or optimization and can be carried out via common exploits software, firmware or hardware based attack vectors. An enhanced variant that uses a single forward and backward pass further amplifies the damage beyond DNL's zero-pass approach. Flipping just two sign bits in ResNet50 on ImageNet reduces accuracy by 99.8\%. We also show that selectively protecting a small fraction of vulnerable sign bits provides a practical defense against such attacks.
Puzzle: Distillation-Based NAS for Inference-Optimized LLMs
Dec 03, 2024
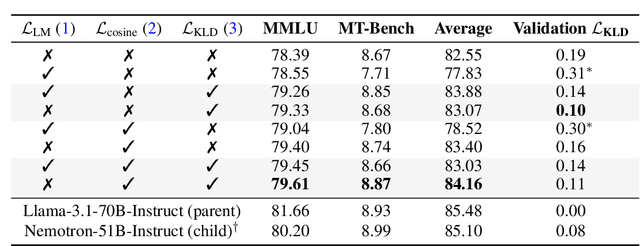

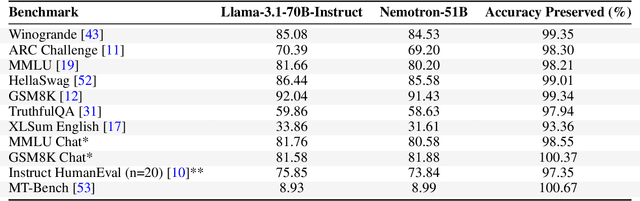
Large language models (LLMs) have demonstrated remarkable capabilities, but their adoption is limited by high computational costs during inference. While increasing parameter counts enhances accuracy, it also widens the gap between state-of-the-art capabilities and practical deployability. We present Puzzle, a framework to accelerate LLM inference on specific hardware while preserving their capabilities. Through an innovative application of neural architecture search (NAS) at an unprecedented scale, Puzzle systematically optimizes models with tens of billions of parameters under hardware constraints. Our approach utilizes blockwise local knowledge distillation (BLD) for parallel architecture exploration and employs mixed-integer programming for precise constraint optimization. We demonstrate the real-world impact of our framework through Llama-3.1-Nemotron-51B-Instruct (Nemotron-51B), a publicly available model derived from Llama-3.1-70B-Instruct. Nemotron-51B achieves a 2.17x inference throughput speedup, fitting on a single NVIDIA H100 GPU while preserving 98.4% of the original model's capabilities. Nemotron-51B currently stands as the most accurate language model capable of inference on a single GPU with large batch sizes. Remarkably, this transformation required just 45B training tokens, compared to over 15T tokens used for the 70B model it was derived from. This establishes a new paradigm where powerful models can be optimized for efficient deployment with only negligible compromise of their capabilities, demonstrating that inference performance, not parameter count alone, should guide model selection. With the release of Nemotron-51B and the presentation of the Puzzle framework, we provide practitioners immediate access to state-of-the-art language modeling capabilities at significantly reduced computational costs.
Hierarchical Selective Classification
May 19, 2024Deploying deep neural networks for risk-sensitive tasks necessitates an uncertainty estimation mechanism. This paper introduces hierarchical selective classification, extending selective classification to a hierarchical setting. Our approach leverages the inherent structure of class relationships, enabling models to reduce the specificity of their predictions when faced with uncertainty. In this paper, we first formalize hierarchical risk and coverage, and introduce hierarchical risk-coverage curves. Next, we develop algorithms for hierarchical selective classification (which we refer to as "inference rules"), and propose an efficient algorithm that guarantees a target accuracy constraint with high probability. Lastly, we conduct extensive empirical studies on over a thousand ImageNet classifiers, revealing that training regimes such as CLIP, pretraining on ImageNet21k and knowledge distillation boost hierarchical selective performance.