 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
FFN Fusion: Rethinking Sequential Computation in Large Language Models
Mar 24, 2025We introduce FFN Fusion, an architectural optimization technique that reduces sequential computation in large language models by identifying and exploiting natural opportunities for parallelization. Our key insight is that sequences of Feed-Forward Network (FFN) layers, particularly those remaining after the removal of specific attention layers, can often be parallelized with minimal accuracy impact. We develop a principled methodology for identifying and fusing such sequences, transforming them into parallel operations that significantly reduce inference latency while preserving model behavior. Applying these techniques to Llama-3.1-405B-Instruct, we create Llama-Nemotron-Ultra-253B-Base (Ultra-253B-Base), an efficient and soon-to-be publicly available model that achieves a 1.71X speedup in inference latency and 35X lower per-token cost while maintaining strong performance across benchmarks. Through extensive experiments on models from 49B to 253B parameters, we demonstrate that FFN Fusion becomes increasingly effective at larger scales and can complement existing optimization techniques like quantization and pruning. Most intriguingly, we find that even full transformer blocks containing both attention and FFN layers can sometimes be parallelized, suggesting new directions for neural architecture design.
Puzzle: Distillation-Based NAS for Inference-Optimized LLMs
Dec 03, 2024
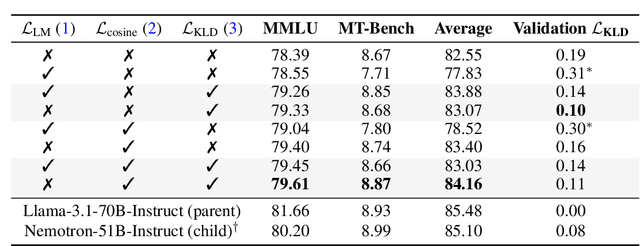

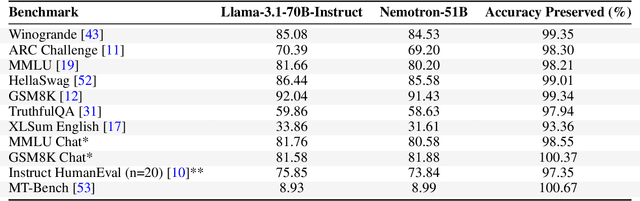
Large language models (LLMs) have demonstrated remarkable capabilities, but their adoption is limited by high computational costs during inference. While increasing parameter counts enhances accuracy, it also widens the gap between state-of-the-art capabilities and practical deployability. We present Puzzle, a framework to accelerate LLM inference on specific hardware while preserving their capabilities. Through an innovative application of neural architecture search (NAS) at an unprecedented scale, Puzzle systematically optimizes models with tens of billions of parameters under hardware constraints. Our approach utilizes blockwise local knowledge distillation (BLD) for parallel architecture exploration and employs mixed-integer programming for precise constraint optimization. We demonstrate the real-world impact of our framework through Llama-3.1-Nemotron-51B-Instruct (Nemotron-51B), a publicly available model derived from Llama-3.1-70B-Instruct. Nemotron-51B achieves a 2.17x inference throughput speedup, fitting on a single NVIDIA H100 GPU while preserving 98.4% of the original model's capabilities. Nemotron-51B currently stands as the most accurate language model capable of inference on a single GPU with large batch sizes. Remarkably, this transformation required just 45B training tokens, compared to over 15T tokens used for the 70B model it was derived from. This establishes a new paradigm where powerful models can be optimized for efficient deployment with only negligible compromise of their capabilities, demonstrating that inference performance, not parameter count alone, should guide model selection. With the release of Nemotron-51B and the presentation of the Puzzle framework, we provide practitioners immediate access to state-of-the-art language modeling capabilities at significantly reduced computational costs.
Flood forecasting with machine learning models in an operational framework
Nov 04, 2021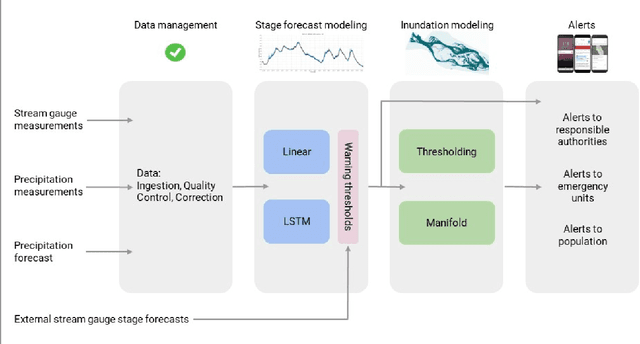
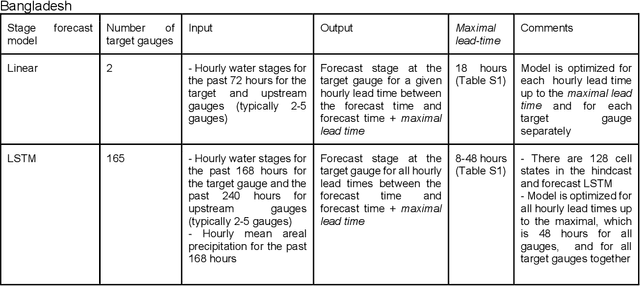
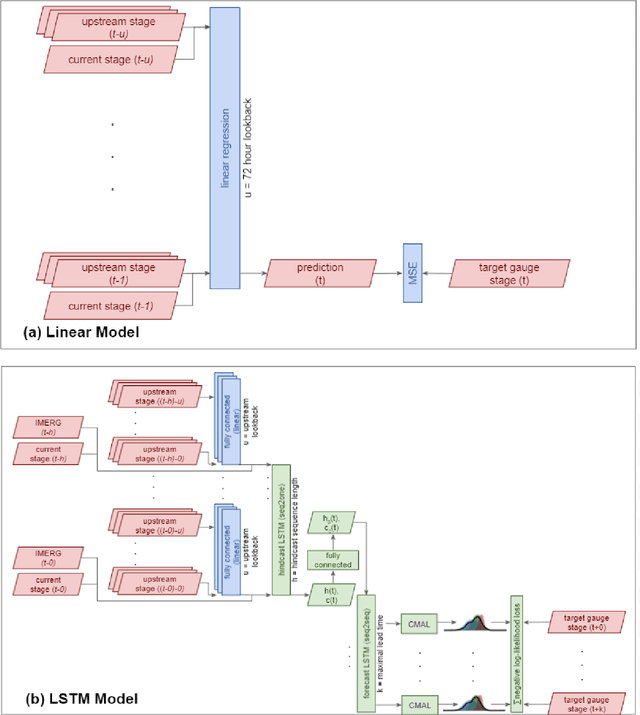
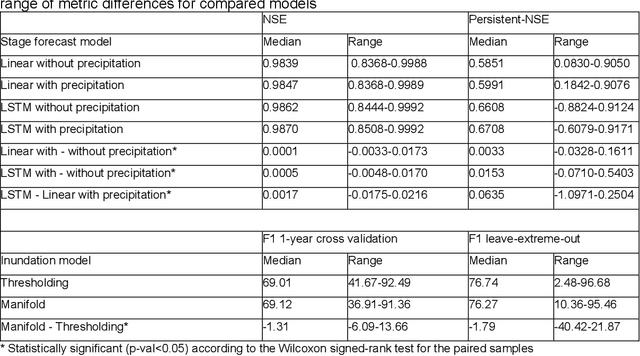
The operational flood forecasting system by Google was developed to provide accurate real-time flood warnings to agencies and the public, with a focus on riverine floods in large, gauged rivers. It became operational in 2018 and has since expanded geographically. This forecasting system consists of four subsystems: data validation, stage forecasting, inundation modeling, and alert distribution. Machine learning is used for two of the subsystems. Stage forecasting is modeled with the Long Short-Term Memory (LSTM) networks and the Linear models. Flood inundation is computed with the Thresholding and the Manifold models, where the former computes inundation extent and the latter computes both inundation extent and depth. The Manifold model, presented here for the first time, provides a machine-learning alternative to hydraulic modeling of flood inundation. When evaluated on historical data, all models achieve sufficiently high-performance metrics for operational use. The LSTM showed higher skills than the Linear model, while the Thresholding and Manifold models achieved similar performance metrics for modeling inundation extent. During the 2021 monsoon season, the flood warning system was operational in India and Bangladesh, covering flood-prone regions around rivers with a total area of 287,000 km2, home to more than 350M people. More than 100M flood alerts were sent to affected populations, to relevant authorities, and to emergency organizations. Current and future work on the system includes extending coverage to additional flood-prone locations, as well as improving modeling capabilities and accuracy.
HydroNets: Leveraging River Structure for Hydrologic Modeling
Jul 01, 2020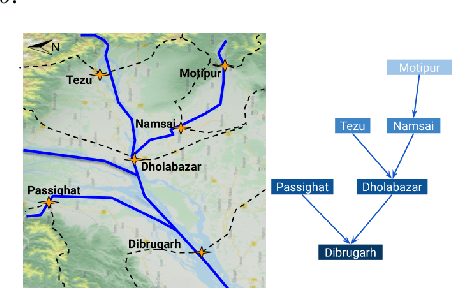
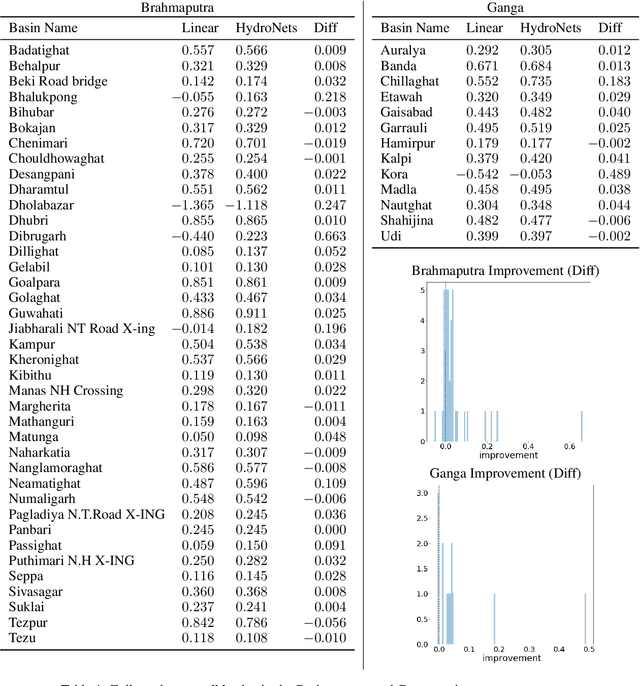
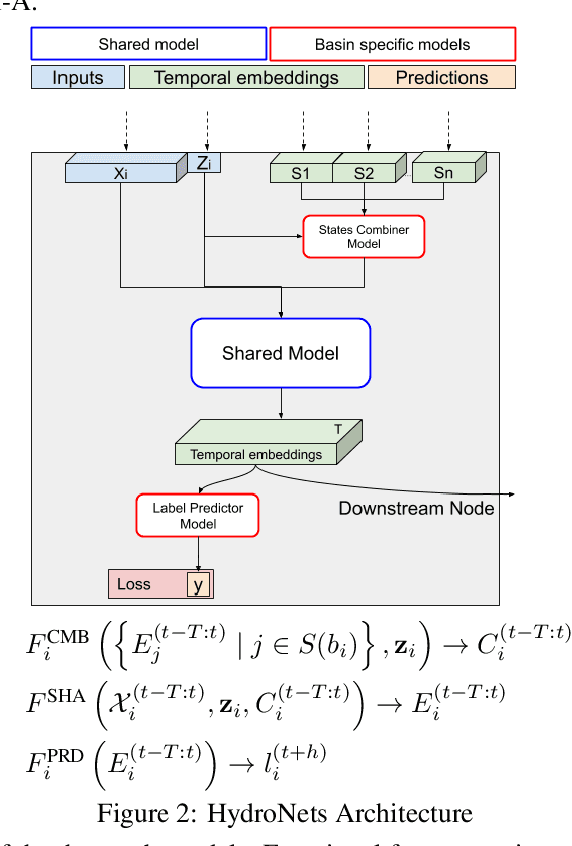

Accurate and scalable hydrologic models are essential building blocks of several important applications, from water resource management to timely flood warnings. However, as the climate changes, precipitation and rainfall-runoff pattern variations become more extreme, and accurate training data that can account for the resulting distributional shifts become more scarce. In this work we present a novel family of hydrologic models, called HydroNets, which leverages river network structure. HydroNets are deep neural network models designed to exploit both basin specific rainfall-runoff signals, and upstream network dynamics, which can lead to improved predictions at longer horizons. The injection of the river structure prior knowledge reduces sample complexity and allows for scalable and more accurate hydrologic modeling even with only a few years of data. We present an empirical study over two large basins in India that convincingly support the proposed model and its advantages.
ML for Flood Forecasting at Scale
Jan 28, 2019Effective riverine flood forecasting at scale is hindered by a multitude of factors, most notably the need to rely on human calibration in current methodology, the limited amount of data for a specific location, and the computational difficulty of building continent/global level models that are sufficiently accurate. Machine learning (ML) is primed to be useful in this scenario: learned models often surpass human experts in complex high-dimensional scenarios, and the framework of transfer or multitask learning is an appealing solution for leveraging local signals to achieve improved global performance. We propose to build on these strengths and develop ML systems for timely and accurate riverine flood prediction.
Towards Global Remote Discharge Estimation: Using the Few to Estimate The Many
Jan 03, 2019
Learning hydrologic models for accurate riverine flood prediction at scale is a challenge of great importance. One of the key difficulties is the need to rely on in-situ river discharge measurements, which can be quite scarce and unreliable, particularly in regions where floods cause the most damage every year. Accordingly, in this work we tackle the problem of river discharge estimation at different river locations. A core characteristic of the data at hand (e.g. satellite measurements) is that we have few measurements for many locations, all sharing the same physics that underlie the water discharge. We capture this scenario in a simple but powerful common mechanism regression (CMR) model with a local component as well as a shared one which captures the global discharge mechanism. The resulting learning objective is non-convex, but we show that we can find its global optimum by leveraging the power of joining local measurements across sites. In particular, using a spectral initialization with provable near-optimal accuracy, we can find the optimum using standard descent methods. We demonstrate the efficacy of our approach for the problem of discharge estimation using simulations.