 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaravan MultiMet: Extending Caravan with Multiple Weather Nowcasts and Forecasts
Nov 14, 2024The Caravan large-sample hydrology dataset (Kratzert et al., 2023) was created to standardize and harmonize streamflow data from various regional datasets, combined with globally available meteorological forcing and catchment attributes. This community-driven project also allows researchers to conveniently extend the dataset for additional basins, as done 6 times to date (see https://github.com/kratzert/Caravan/discussions/10). We present a novel extension to Caravan, focusing on enriching the meteorological forcing data. Our extension adds three precipitation nowcast products (CPC, IMERG v07 Early, and CHIRPS) and three weather forecast products (ECMWF IFS HRES, GraphCast, and CHIRPS-GEFS) to the existing ERA5-Land reanalysis data. The inclusion of diverse data sources, particularly weather forecasts, enables more robust evaluation and benchmarking of hydrological models, especially for real-time forecasting scenarios. To the best of our knowledge, this extension makes Caravan the first large-sample hydrology dataset to incorporate weather forecast data, significantly enhancing its capabilities and fostering advancements in hydrological research, benchmarking, and real-time hydrologic forecasting. The data is publicly available under a CC-BY-4.0 license on Zenodo in two parts (https://zenodo.org/records/14161235, https://zenodo.org/records/14161281) and on Google Cloud Platform (GCP) - see more under the Data Availability chapter.
AI Increases Global Access to Reliable Flood Forecasts
Aug 10, 2023



Floods are one of the most common and impactful natural disasters, with a disproportionate impact in developing countries that often lack dense streamflow monitoring networks. Accurate and timely warnings are critical for mitigating flood risks, but accurate hydrological simulation models typically must be calibrated to long data records in each watershed where they are applied. We developed an Artificial Intelligence (AI) model to predict extreme hydrological events at timescales up to 7 days in advance. This model significantly outperforms current state of the art global hydrology models (the Copernicus Emergency Management Service Global Flood Awareness System) across all continents, lead times, and return periods. AI is especially effective at forecasting in ungauged basins, which is important because only a few percent of the world's watersheds have stream gauges, with a disproportionate number of ungauged basins in developing countries that are especially vulnerable to the human impacts of flooding. We produce forecasts of extreme events in South America and Africa that achieve reliability approaching the current state of the art in Europe and North America, and we achieve reliability at between 4 and 6-day lead times that are similar to current state of the art nowcasts (0-day lead time). Additionally, we achieve accuracies over 10-year return period events that are similar to current accuracies over 2-year return period events, meaning that AI can provide warnings earlier and over larger and more impactful events. The model that we develop in this paper has been incorporated into an operational early warning system that produces publicly available (free and open) forecasts in real time in over 80 countries. This work using AI and open data highlights a need for increasing the availability of hydrological data to continue to improve global access to reliable flood warnings.
Flood forecasting with machine learning models in an operational framework
Nov 04, 2021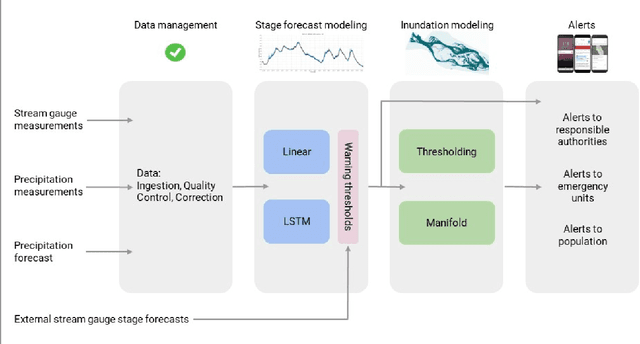
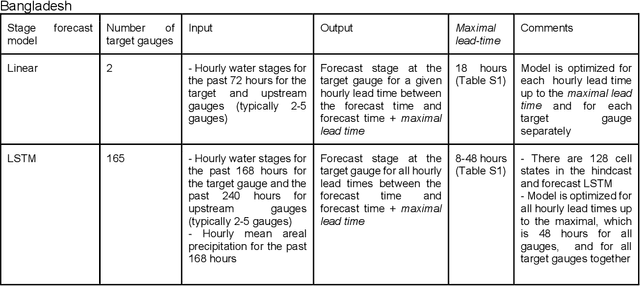
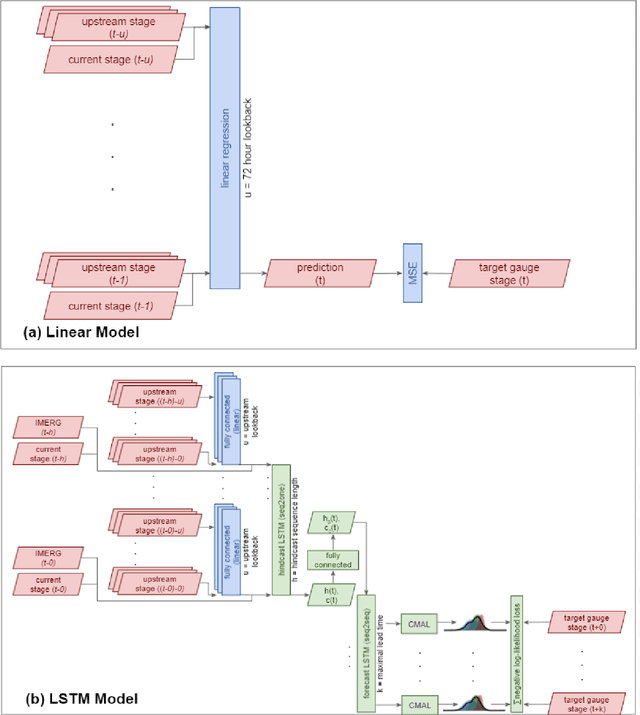
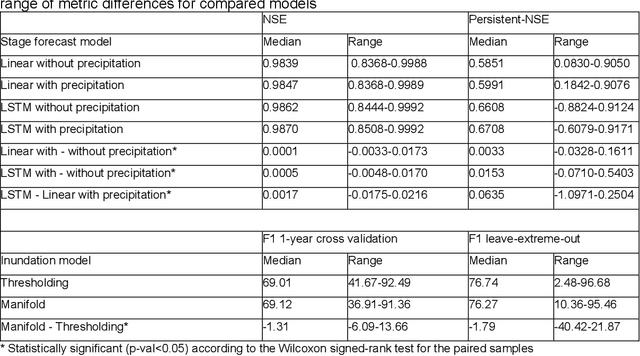
The operational flood forecasting system by Google was developed to provide accurate real-time flood warnings to agencies and the public, with a focus on riverine floods in large, gauged rivers. It became operational in 2018 and has since expanded geographically. This forecasting system consists of four subsystems: data validation, stage forecasting, inundation modeling, and alert distribution. Machine learning is used for two of the subsystems. Stage forecasting is modeled with the Long Short-Term Memory (LSTM) networks and the Linear models. Flood inundation is computed with the Thresholding and the Manifold models, where the former computes inundation extent and the latter computes both inundation extent and depth. The Manifold model, presented here for the first time, provides a machine-learning alternative to hydraulic modeling of flood inundation. When evaluated on historical data, all models achieve sufficiently high-performance metrics for operational use. The LSTM showed higher skills than the Linear model, while the Thresholding and Manifold models achieved similar performance metrics for modeling inundation extent. During the 2021 monsoon season, the flood warning system was operational in India and Bangladesh, covering flood-prone regions around rivers with a total area of 287,000 km2, home to more than 350M people. More than 100M flood alerts were sent to affected populations, to relevant authorities, and to emergency organizations. Current and future work on the system includes extending coverage to additional flood-prone locations, as well as improving modeling capabilities and accuracy.
MC-LSTM: Mass-Conserving LSTM
Feb 08, 2021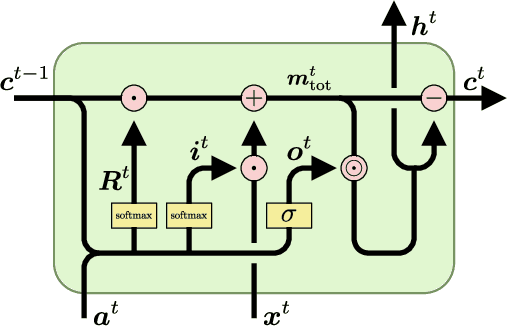
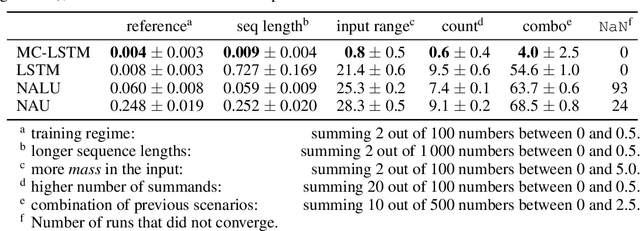
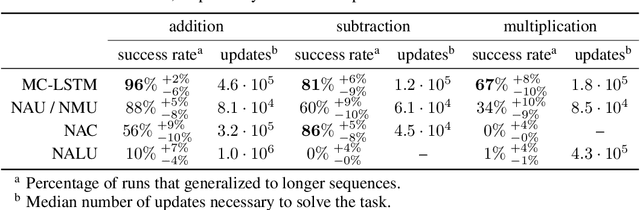
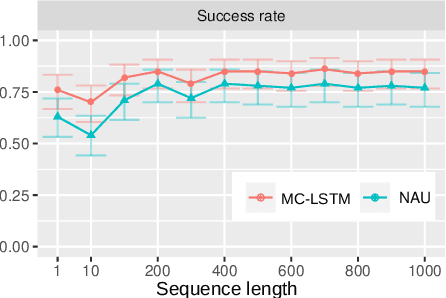
The success of Convolutional Neural Networks (CNNs) in computer vision is mainly driven by their strong inductive bias, which is strong enough to allow CNNs to solve vision-related tasks with random weights, meaning without learning. Similarly, Long Short-Term Memory (LSTM) has a strong inductive bias towards storing information over time. However, many real-world systems are governed by conservation laws, which lead to the redistribution of particular quantities -- e.g. in physical and economical systems. Our novel Mass-Conserving LSTM (MC-LSTM) adheres to these conservation laws by extending the inductive bias of LSTM to model the redistribution of those stored quantities. MC-LSTMs set a new state-of-the-art for neural arithmetic units at learning arithmetic operations, such as addition tasks, which have a strong conservation law, as the sum is constant over time. Further, MC-LSTM is applied to traffic forecasting, modelling a pendulum, and a large benchmark dataset in hydrology, where it sets a new state-of-the-art for predicting peak flows. In the hydrology example, we show that MC-LSTM states correlate with real-world processes and are therefore interpretable.
Uncertainty Estimation with Deep Learning for Rainfall-Runoff Modelling
Dec 15, 2020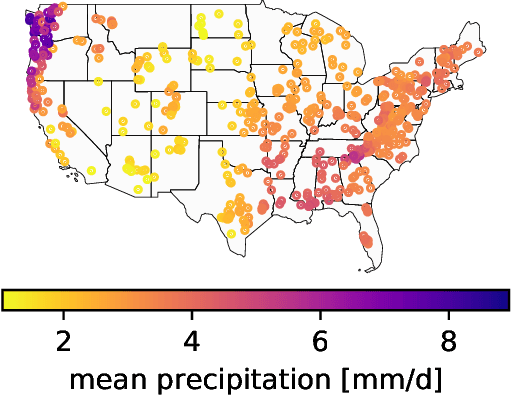
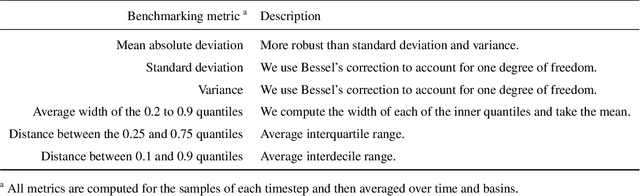
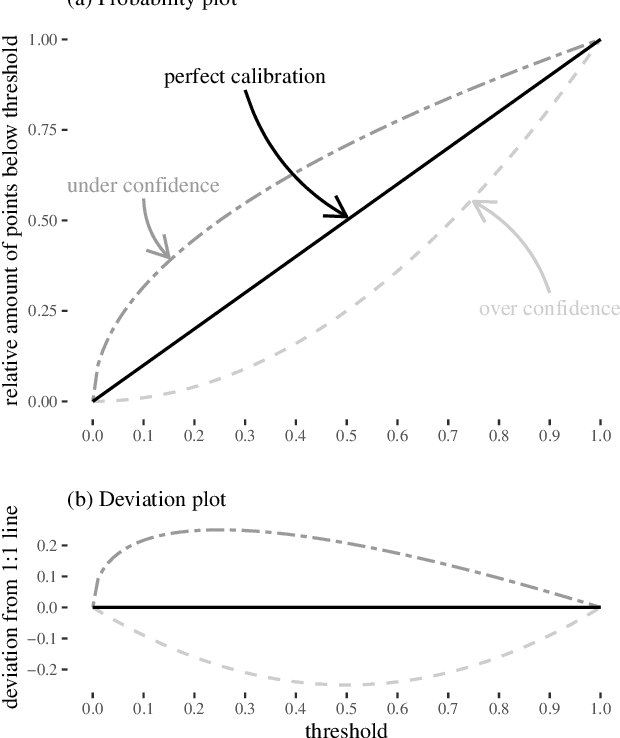
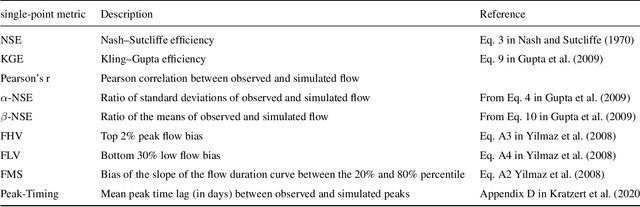
Deep Learning is becoming an increasingly important way to produce accurate hydrological predictions across a wide range of spatial and temporal scales. Uncertainty estimations are critical for actionable hydrological forecasting, and while standardized community benchmarks are becoming an increasingly important part of hydrological model development and research, similar tools for benchmarking uncertainty estimation are lacking. We establish an uncertainty estimation benchmarking procedure and present four Deep Learning baselines, out of which three are based on Mixture Density Networks and one is based on Monte Carlo dropout. Additionally, we provide a post-hoc model analysis to put forward some qualitative understanding of the resulting models. Most importantly however, we show that accurate, precise, and reliable uncertainty estimation can be achieved with Deep Learning.
Rainfall-Runoff Prediction at Multiple Timescales with a Single Long Short-Term Memory Network
Oct 15, 2020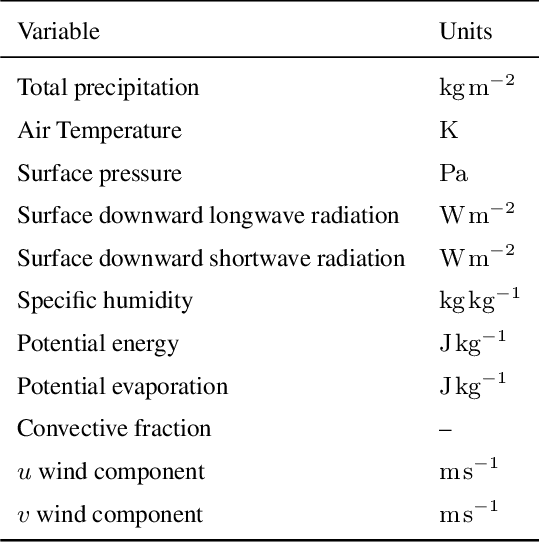
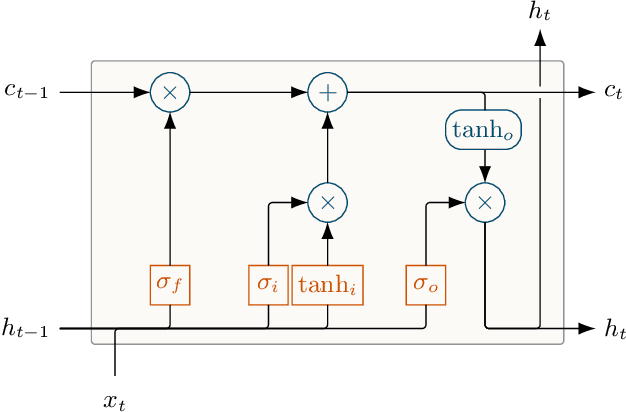
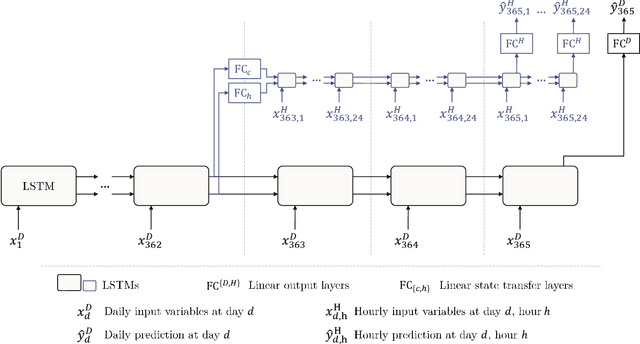

Long Short-Term Memory Networks (LSTMs) have been applied to daily discharge prediction with remarkable success. Many practical scenarios, however, require predictions at more granular timescales. For instance, accurate prediction of short but extreme flood peaks can make a life-saving difference, yet such peaks may escape the coarse temporal resolution of daily predictions. Naively training an LSTM on hourly data, however, entails very long input sequences that make learning hard and computationally expensive. In this study, we propose two Multi-Timescale LSTM (MTS-LSTM) architectures that jointly predict multiple timescales within one model, as they process long-past inputs at a single temporal resolution and branch out into each individual timescale for more recent input steps. We test these models on 516 basins across the continental United States and benchmark against the US National Water Model. Compared to naive prediction with a distinct LSTM per timescale, the multi-timescale architectures are computationally more efficient with no loss in accuracy. Beyond prediction quality, the multi-timescale LSTM can process different input variables at different timescales, which is especially relevant to operational applications where the lead time of meteorological forcings depends on their temporal resolution.
HydroNets: Leveraging River Structure for Hydrologic Modeling
Jul 01, 2020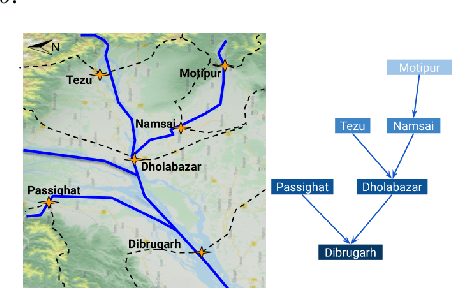
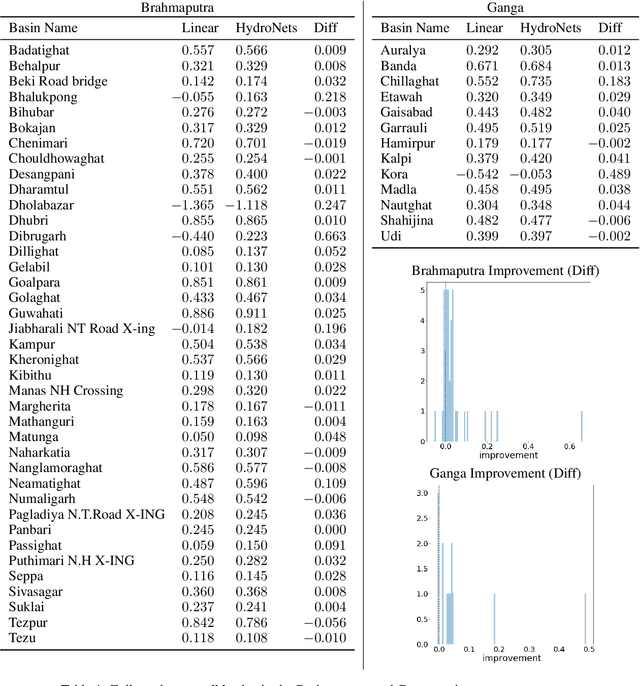
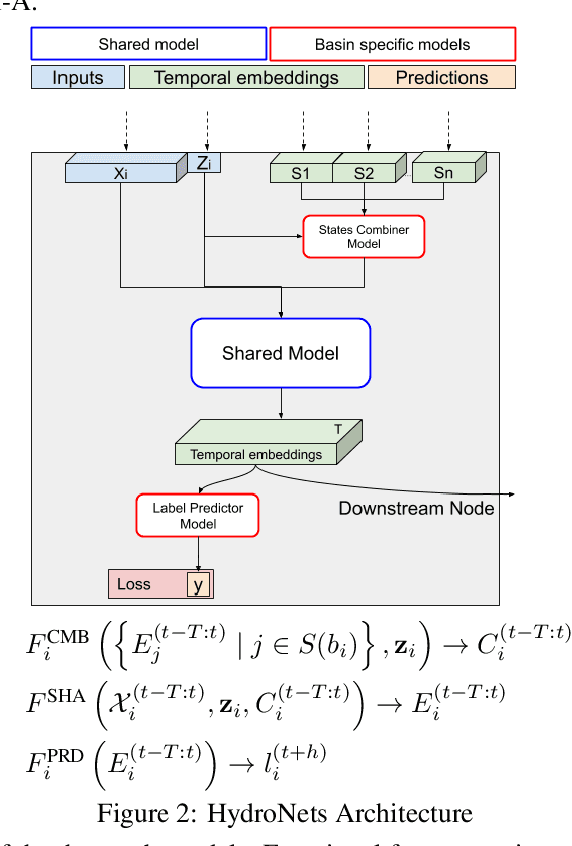

Accurate and scalable hydrologic models are essential building blocks of several important applications, from water resource management to timely flood warnings. However, as the climate changes, precipitation and rainfall-runoff pattern variations become more extreme, and accurate training data that can account for the resulting distributional shifts become more scarce. In this work we present a novel family of hydrologic models, called HydroNets, which leverages river network structure. HydroNets are deep neural network models designed to exploit both basin specific rainfall-runoff signals, and upstream network dynamics, which can lead to improved predictions at longer horizons. The injection of the river structure prior knowledge reduces sample complexity and allows for scalable and more accurate hydrologic modeling even with only a few years of data. We present an empirical study over two large basins in India that convincingly support the proposed model and its advantages.
Using LSTMs for climate change assessment studies on droughts and floods
Nov 28, 2019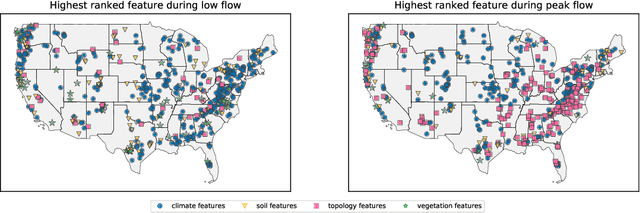
Climate change affects occurrences of floods and droughts worldwide. However, predicting climate impacts over individual watersheds is difficult, primarily because accurate hydrological forecasts require models that are calibrated to past data. In this work we present a large-scale LSTM-based modeling approach that -- by training on large data sets -- learns a diversity of hydrological behaviors. Previous work shows that this model is more accurate than current state-of-the-art models, even when the LSTM-based approach operates out-of-sample and the latter in-sample. In this work, we show how this model can assess the sensitivity of the underlying systems with regard to extreme (high and low) flows in individual watersheds over the continental US.
Accurate Hydrologic Modeling Using Less Information
Nov 21, 2019
Joint models are a common and important tool in the intersection of machine learning and the physical sciences, particularly in contexts where real-world measurements are scarce. Recent developments in rainfall-runoff modeling, one of the prime challenges in hydrology, show the value of a joint model with shared representation in this important context. However, current state-of-the-art models depend on detailed and reliable attributes characterizing each site to help the model differentiate correctly between the behavior of different sites. This dependency can present a challenge in data-poor regions. In this paper, we show that we can replace the need for such location-specific attributes with a completely data-driven learned embedding, and match previous state-of-the-art results with less information.
Benchmarking a Catchment-Aware Long Short-Term Memory Network (LSTM) for Large-Scale Hydrological Modeling
Jul 19, 2019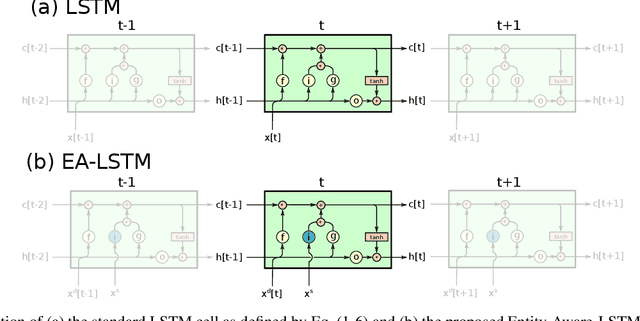



Regional rainfall-runoff modeling is an old but still mostly out-standing problem in Hydrological Sciences. The problem currently is that traditional hydrological models degrade significantly in performance when calibrated for multiple basins together instead of for a single basin alone. In this paper, we propose a novel, data-driven approach using Long Short-Term Memory networks (LSTMs), and demonstrate that under a 'big data' paradigm, this is not necessarily the case. By training a single LSTM model on 531 basins from the CAMELS data set using meteorological time series data and static catchment attributes, we were able to significantly improve performance compared to a set of several different hydrological benchmark models. Our proposed approach not only significantly outperforms hydrological models that were calibrated regionally but also achieves better performance than hydrological models that were calibrated for each basin individually. Furthermore, we propose an adaption to the standard LSTM architecture, which we call an Entity-Aware-LSTM (EA-LSTM), that allows for learning, and embedding as a feature layer in a deep learning model, catchment similarities. We show that this learned catchment similarity corresponds well with what we would expect from prior hydrological understanding.