 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Increases Global Access to Reliable Flood Forecasts
Aug 10, 2023



Floods are one of the most common and impactful natural disasters, with a disproportionate impact in developing countries that often lack dense streamflow monitoring networks. Accurate and timely warnings are critical for mitigating flood risks, but accurate hydrological simulation models typically must be calibrated to long data records in each watershed where they are applied. We developed an Artificial Intelligence (AI) model to predict extreme hydrological events at timescales up to 7 days in advance. This model significantly outperforms current state of the art global hydrology models (the Copernicus Emergency Management Service Global Flood Awareness System) across all continents, lead times, and return periods. AI is especially effective at forecasting in ungauged basins, which is important because only a few percent of the world's watersheds have stream gauges, with a disproportionate number of ungauged basins in developing countries that are especially vulnerable to the human impacts of flooding. We produce forecasts of extreme events in South America and Africa that achieve reliability approaching the current state of the art in Europe and North America, and we achieve reliability at between 4 and 6-day lead times that are similar to current state of the art nowcasts (0-day lead time). Additionally, we achieve accuracies over 10-year return period events that are similar to current accuracies over 2-year return period events, meaning that AI can provide warnings earlier and over larger and more impactful events. The model that we develop in this paper has been incorporated into an operational early warning system that produces publicly available (free and open) forecasts in real time in over 80 countries. This work using AI and open data highlights a need for increasing the availability of hydrological data to continue to improve global access to reliable flood warnings.
Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning
Jul 25, 2022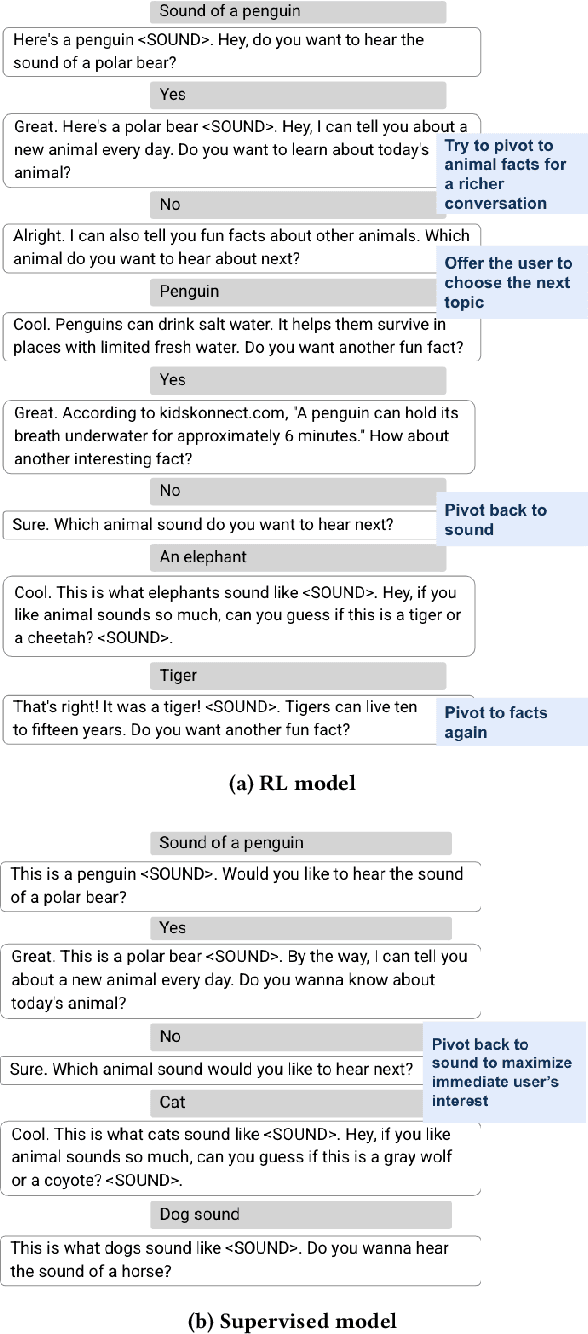
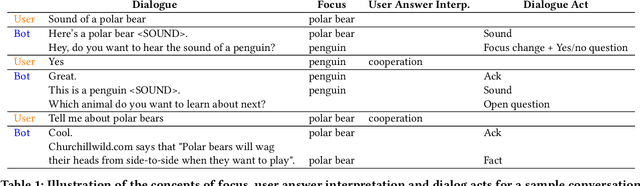

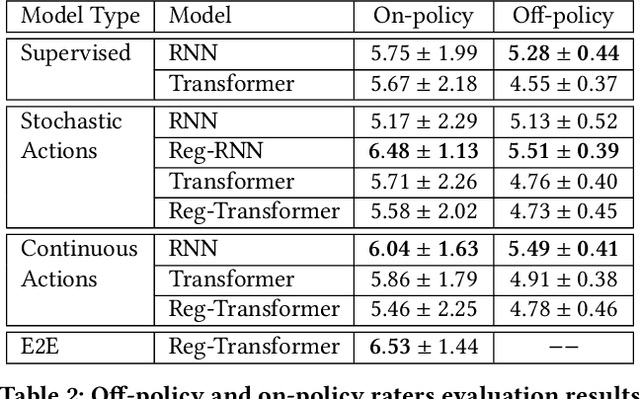
Despite recent advances in natural language understanding and generation, and decades of research on the development of conversational bots, building automated agents that can carry on rich open-ended conversations with humans "in the wild" remains a formidable challenge. In this work we develop a real-time, open-ended dialogue system that uses reinforcement learning (RL) to power a bot's conversational skill at scale. Our work pairs the succinct embedding of the conversation state generated using SOTA (supervised) language models with RL techniques that are particularly suited to a dynamic action space that changes as the conversation progresses. Trained using crowd-sourced data, our novel system is able to substantially exceeds the (strong) baseline supervised model with respect to several metrics of interest in a live experiment with real users of the Google Assistant.
Unambiguous Delay-Doppler Recovery from Random Phase Coded Pulses
Dec 22, 2020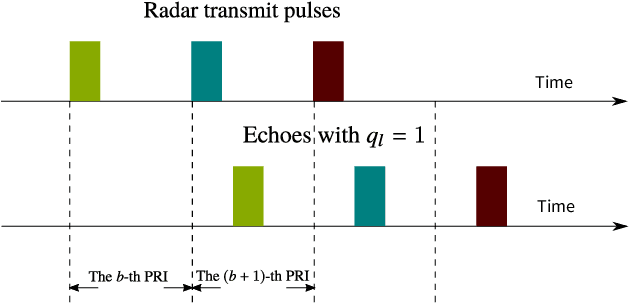
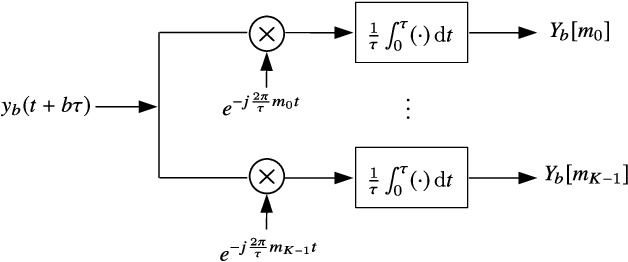
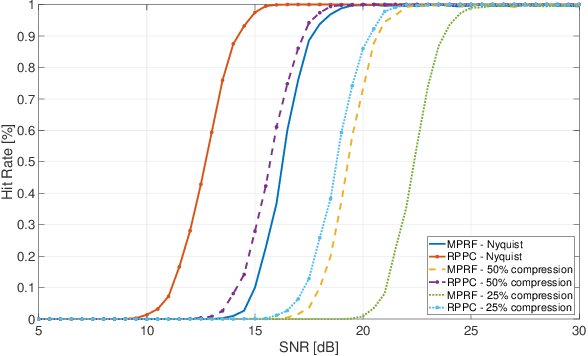
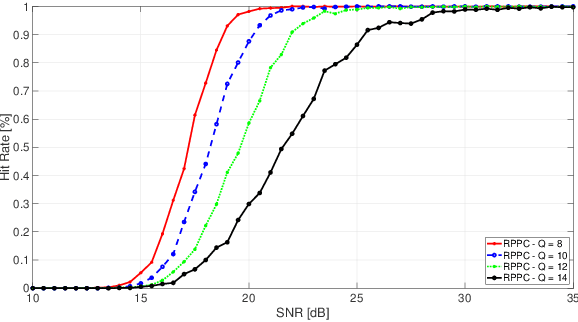
Pulse Doppler radars suffer from range-Doppler ambiguity that translates into a trade-off between maximal unambiguous range and velocity. Several techniques, like the multiple PRFs (MPRF) method, have been proposed to mitigate this problem. The drawback of the MPRF method is that the received samples are not processed jointly, decreasing signal to noise ratio (SNR). To overcome the drawbacks of MPRF, we employ a random pulse phase coding approach to increase the unambiguous range region while preserving the unambiguous Doppler region. Our method encodes each pulse with a random phase, varying from pulse to pulse, and then processes the received samples jointly to resolve the range ambiguity. This technique increases the SNR through joint processing without the parameter matching procedures required in the MPRF method. The recovery algorithm is designed based on orthogonal matching pursuit so that it can be directly applied to either Nyquist or sub-Nyquist samples. The unambiguous delay-Doppler recovery condition is derived with compressed sensing theory in noiseless settings. In particular, an upper bound to the number of targets is given, with respect to the number of samples in each pulse repetition interval and the number of transmit pulses. Simulations show that in both regimes of Nyquist and sub-Nyquist samples our method outperforms the popular MPRF approach in terms of hit rate.
Action Assembly: Sparse Imitation Learning for Text Based Games with Combinatorial Action Spaces
May 23, 2019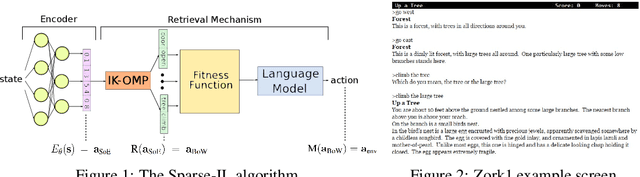
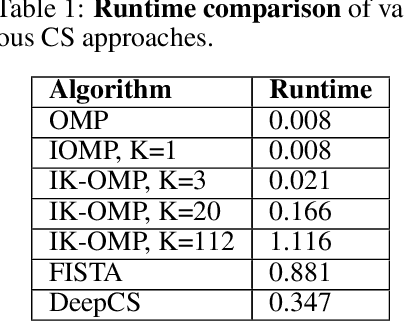
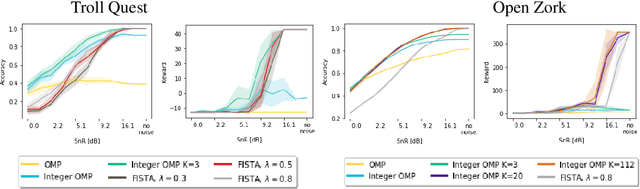
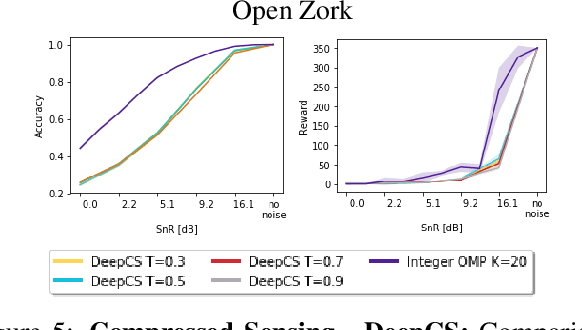
We propose a computationally efficient algorithm that combines compressed sensing with imitation learning to solve sequential decision making text-based games with combinatorial action spaces. We propose a variation of the compressed sensing algorithm Orthogonal Matching Pursuit (OMP), that we call IK-OMP, and show that it can recover a bag-of-words from a sum of the individual word embeddings, even in the presence of noise. We incorporate IK-OMP into a supervised imitation learning setting and show that this algorithm, called Sparse Imitation Learning (Sparse-IL), solves the entire text-based game of Zork1 with an action space of approximately 10 million actions using imperfect, noisy demonstrations.
Learning with Rules
May 22, 2018
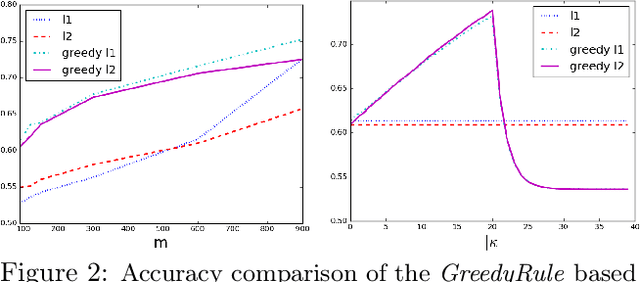
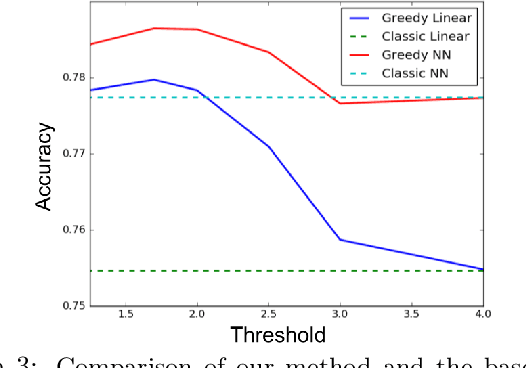

Complex classifiers may exhibit "embarassing" failures in cases where a human can easily provide a justified classification. Avoiding such failures is obviously of key importance. In this work, we focus on one such setting, where a label is perfectly predictable if the input contains certain features, and otherwise it is predictable by a linear classifier. We define a hypothesis class that captures this notion and determine its sample complexity. We also give evidence that efficient algorithms cannot achieve this sample complexity. We then derive a simple and efficient algorithm and give evidence that its sample complexity is optimal, among efficient algorithms. Experiments on synthetic and sentiment analysis data demonstrate the efficacy of the method, both in terms of accuracy and interpretability.