 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Increases Global Access to Reliable Flood Forecasts
Aug 10, 2023



Floods are one of the most common and impactful natural disasters, with a disproportionate impact in developing countries that often lack dense streamflow monitoring networks. Accurate and timely warnings are critical for mitigating flood risks, but accurate hydrological simulation models typically must be calibrated to long data records in each watershed where they are applied. We developed an Artificial Intelligence (AI) model to predict extreme hydrological events at timescales up to 7 days in advance. This model significantly outperforms current state of the art global hydrology models (the Copernicus Emergency Management Service Global Flood Awareness System) across all continents, lead times, and return periods. AI is especially effective at forecasting in ungauged basins, which is important because only a few percent of the world's watersheds have stream gauges, with a disproportionate number of ungauged basins in developing countries that are especially vulnerable to the human impacts of flooding. We produce forecasts of extreme events in South America and Africa that achieve reliability approaching the current state of the art in Europe and North America, and we achieve reliability at between 4 and 6-day lead times that are similar to current state of the art nowcasts (0-day lead time). Additionally, we achieve accuracies over 10-year return period events that are similar to current accuracies over 2-year return period events, meaning that AI can provide warnings earlier and over larger and more impactful events. The model that we develop in this paper has been incorporated into an operational early warning system that produces publicly available (free and open) forecasts in real time in over 80 countries. This work using AI and open data highlights a need for increasing the availability of hydrological data to continue to improve global access to reliable flood warnings.
Flood forecasting with machine learning models in an operational framework
Nov 04, 2021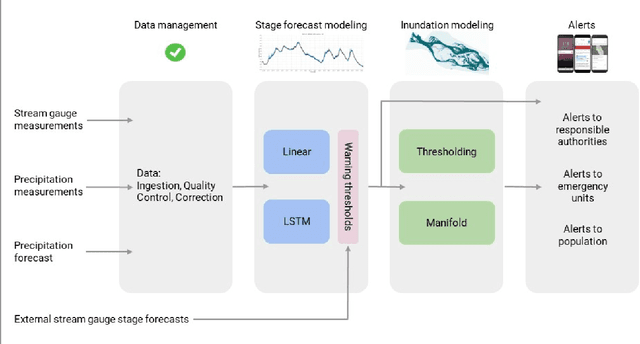
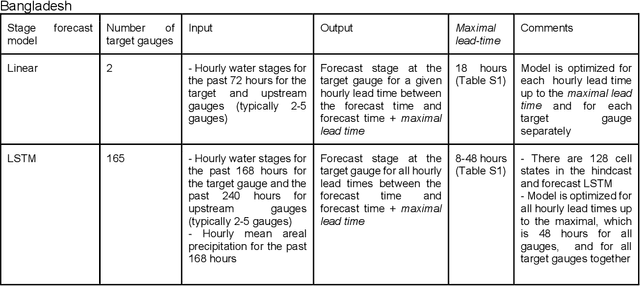
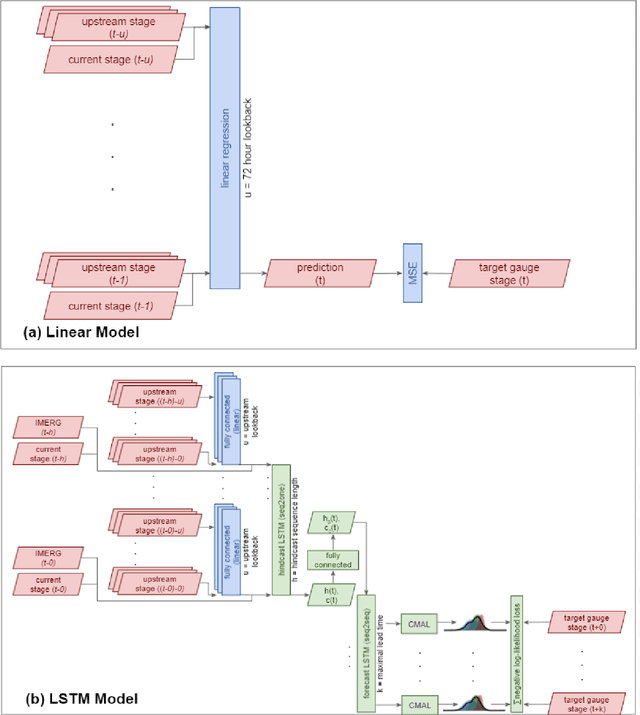
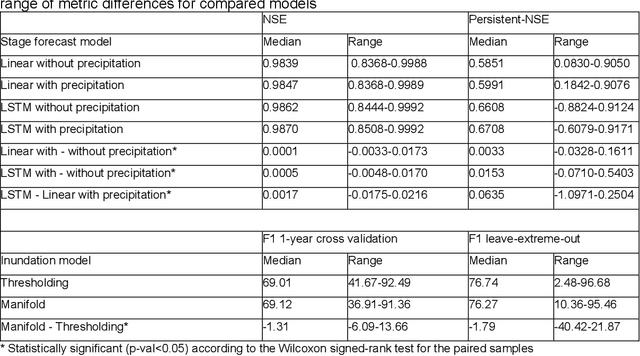
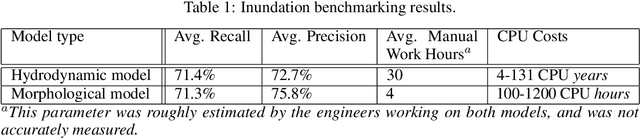
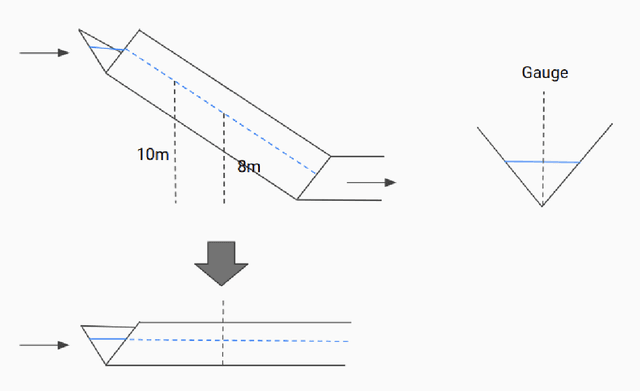
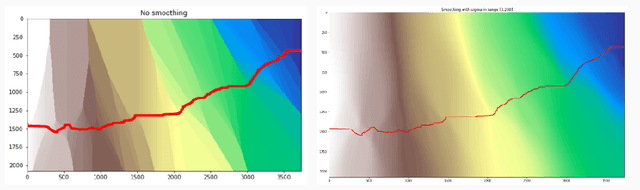
The operational flood forecasting system by Google was developed to provide accurate real-time flood warnings to agencies and the public, with a focus on riverine floods in large, gauged rivers. It became operational in 2018 and has since expanded geographically. This forecasting system consists of four subsystems: data validation, stage forecasting, inundation modeling, and alert distribution. Machine learning is used for two of the subsystems. Stage forecasting is modeled with the Long Short-Term Memory (LSTM) networks and the Linear models. Flood inundation is computed with the Thresholding and the Manifold models, where the former computes inundation extent and the latter computes both inundation extent and depth. The Manifold model, presented here for the first time, provides a machine-learning alternative to hydraulic modeling of flood inundation. When evaluated on historical data, all models achieve sufficiently high-performance metrics for operational use. The LSTM showed higher skills than the Linear model, while the Thresholding and Manifold models achieved similar performance metrics for modeling inundation extent. During the 2021 monsoon season, the flood warning system was operational in India and Bangladesh, covering flood-prone regions around rivers with a total area of 287,000 km2, home to more than 350M people. More than 100M flood alerts were sent to affected populations, to relevant authorities, and to emergency organizations. Current and future work on the system includes extending coverage to additional flood-prone locations, as well as improving modeling capabilities and accuracy.
ML-based Flood Forecasting: Advances in Scale, Accuracy and Reach
Dec 06, 2020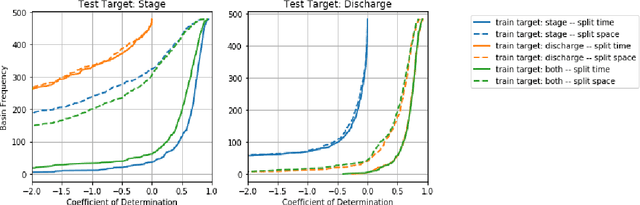
Floods are among the most common and deadly natural disasters in the world, and flood warning systems have been shown to be effective in reducing harm. Yet the majority of the world's vulnerable population does not have access to reliable and actionable warning systems, due to core challenges in scalability, computational costs, and data availability. In this paper we present two components of flood forecasting systems which were developed over the past year, providing access to these critical systems to 75 million people who didn't have this access before.
A Joint Named-Entity Recognizer for Heterogeneous Tag-setsUsing a Tag Hierarchy
May 22, 2019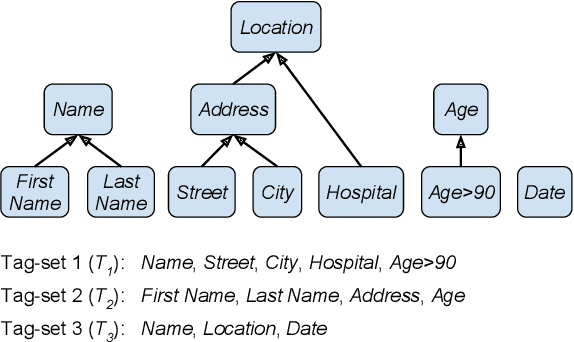
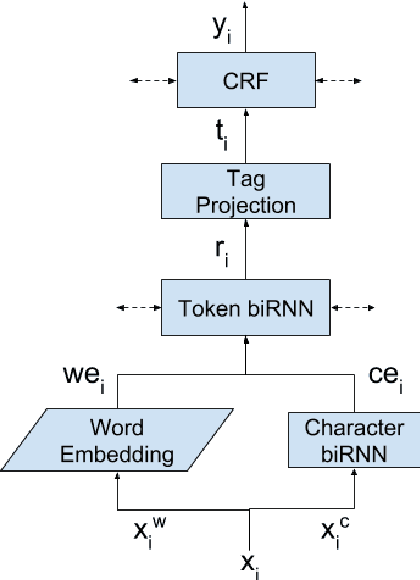

We study a variant of domain adaptation for named-entity recognition where multiple, heterogeneously tagged training sets are available. Furthermore, the test tag-set is not identical to any individual training tag-set. Yet, the relations between all tags are provided in a tag hierarchy, covering the test tags as a combination of training tags. This setting occurs when various datasets are created using different annotation schemes. This is also the case of extending a tag-set with a new tag by annotating only the new tag in a new dataset. We propose to use the given tag hierarchy to jointly learn a neural network that shares its tagging layer among all tag-sets. We compare this model to combining independent models and to a model based on the multitasking approach. Our experiments show the benefit of the tag-hierarchy model, especially when facing non-trivial consolidation of tag-sets.