 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?
May 28, 2026Spatial reasoning is a fundamental capability for vision-language models (VLMs) deployed in real-world environments. However, visual observations are inherently limited representations of a 3D world: occlusion can render objects invisible, and perspective can make geometric properties misleading. Despite this, existing spatial reasoning benchmarks typically assume that observations are sufficient and reliable, focusing on whether models produce correct answers rather than whether they recognize when a question cannot be answered and what additional observations would be needed. In this work, we challenge this assumption by constructing a controlled evaluation framework, SpatialUncertain, and introducing two types of observation challenges: (1) occlusion, which hides target information, and (2) perspective ambiguity, which produces misleading visual cues. For each configuration, we design spatial questions that are answerable under clean observations but require abstention under the introduced challenges. We further evaluate whether models can identify which additional viewpoints would resolve perspective ambiguity. Our results across a diverse set of frontier open- and closed-source VLMs reveal two consistent failure modes. First, models are prone to overconfident answering, attempting to solve spatial reasoning tasks even when visual evidence is incomplete or misleading, with average accuracy around 30\% under occlusion and below 10\% under perspective ambiguity. Second, even when additional views are available, some models perform near random chance in identifying which would provide reliable evidence. Together, our findings call for moving beyond answer correctness toward evaluating whether models know when to abstain and how to seek reliable evidence.
Location Not Found: Exposing Implicit Local and Global Biases in Multilingual LLMs
Apr 21, 2026Multilingual large language models (LLMs) have minimized the fluency gap between languages. This advancement, however, exposes models to the risk of biased behavior, as knowledge and norms may propagate across languages. In this work, we aim to quantify models' inter- and intra-lingual biases, via their ability to answer locale-ambiguous questions. To this end, we present LocQA, a test set containing 2,156 questions in 12 languages, referring to various locale-dependent facts such as laws, dates, and measurements. The questions do not contain indications of the locales they relate to, other than the querying language itself. LLMs' responses to LocQA locale-ambiguous questions thus reveal models' implicit priors. We used LocQA to evaluate 32 models, and detected two types of structural biases. Inter-lingually, we show a global bias towards answers relevant to the US-locale, even when models are asked in languages other than English. Moreover, we discovered that this global bias is exacerbated in models that underwent instruction tuning, compared to their base counterparts. Intra-lingually, we show that when multiple locales are relevant for the same language, models act as demographic probability engines, prioritizing locales with larger populations. Taken together, insights from LocQA may help in shaping LLMs' desired local behavior, and in quantifying the impact of various training phases on different kinds of biases.
Latent Reasoning with Supervised Thinking States
Feb 09, 2026Reasoning with a chain-of-thought (CoT) enables Large Language Models (LLMs) to solve complex tasks but incurs significant inference costs due to the generation of long rationales. We propose Thinking States, a method that performs reasoning {\em while} the input is processing. Specifically, Thinking States generates sequences of thinking tokens every few input tokens, transforms the thoughts back into embedding space, and adds them to the following input tokens. This has two key advantages. First, it captures the recurrent nature of CoT, but where the thought tokens are generated as input is processing. Second, since the thoughts are represented as tokens, they can be learned from natural language supervision, and using teacher-forcing, which is parallelizable. Empirically, Thinking States outperforms other latent reasoning methods on multiple reasoning tasks, narrowing the gap to CoT on math problems, and matching its performance on 2-Hop QA with improved latency. On state-tracking tasks, we show Thinking States leads to stronger reasoning behavior than CoT, successfully extrapolating to longer sequences than seen during training.
Beyond the Noise: Aligning Prompts with Latent Representations in Diffusion Models
Dec 09, 2025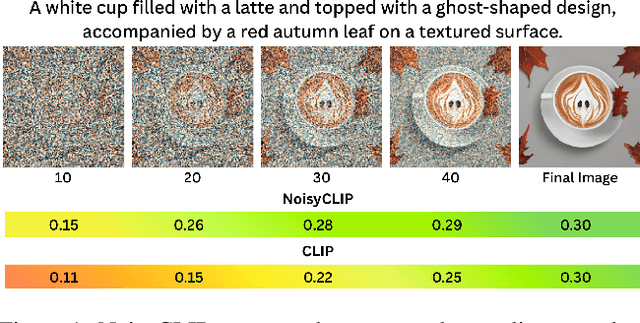
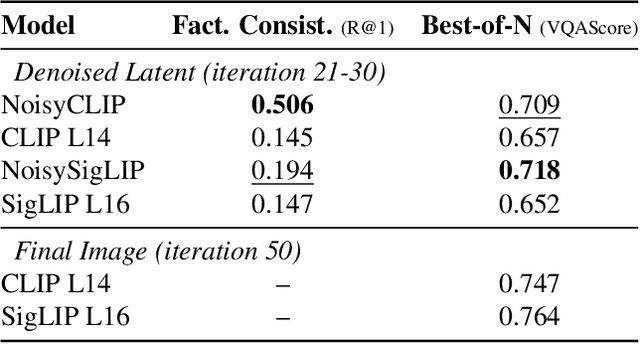
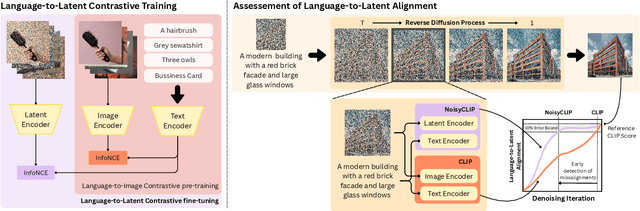
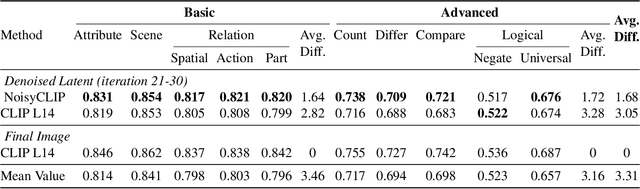
Conditional diffusion models rely on language-to-image alignment methods to steer the generation towards semantically accurate outputs. Despite the success of this architecture, misalignment and hallucinations remain common issues and require automatic misalignment detection tools to improve quality, for example by applying them in a Best-of-N (BoN) post-generation setting. Unfortunately, measuring the alignment after the generation is an expensive step since we need to wait for the overall generation to finish to determine prompt adherence. In contrast, this work hypothesizes that text/image misalignments can be detected early in the denoising process, enabling real-time alignment assessment without waiting for the complete generation. In particular, we propose NoisyCLIP a method that measures semantic alignment in the noisy latent space. This work is the first to explore and benchmark prompt-to-latent misalignment detection during image generation using dual encoders in the reverse diffusion process. We evaluate NoisyCLIP qualitatively and quantitatively and find it reduces computational cost by 50% while achieving 98% of CLIP alignment performance in BoN settings. This approach enables real-time alignment assessment during generation, reducing costs without sacrificing semantic fidelity.
Error-Driven Scene Editing for 3D Grounding in Large Language Models
Nov 18, 2025Despite recent progress in 3D-LLMs, they remain limited in accurately grounding language to visual and spatial elements in 3D environments. This limitation stems in part from training data that focuses on language reasoning rather than spatial understanding due to scarce 3D resources, leaving inherent grounding biases unresolved. To address this, we propose 3D scene editing as a key mechanism to generate precise visual counterfactuals that mitigate these biases through fine-grained spatial manipulation, without requiring costly scene reconstruction or large-scale 3D data collection. Furthermore, to make these edits targeted and directly address the specific weaknesses of the model, we introduce DEER-3D, an error-driven framework following a structured "Decompose, Diagnostic Evaluation, Edit, and Re-train" workflow, rather than broadly or randomly augmenting data as in conventional approaches. Specifically, upon identifying a grounding failure of the 3D-LLM, our framework first diagnoses the exact predicate-level error (e.g., attribute or spatial relation). It then executes minimal, predicate-aligned 3D scene edits, such as recoloring or repositioning, to produce targeted counterfactual supervision for iterative model fine-tuning, significantly enhancing grounding accuracy. We evaluate our editing pipeline across multiple benchmarks for 3D grounding and scene understanding tasks, consistently demonstrating improvements across all evaluated datasets through iterative refinement. DEER-3D underscores the effectiveness of targeted, error-driven scene editing in bridging linguistic reasoning capabilities with spatial grounding in 3D LLMs.
ManagerBench: Evaluating the Safety-Pragmatism Trade-off in Autonomous LLMs
Oct 01, 2025As large language models (LLMs) evolve from conversational assistants into autonomous agents, evaluating the safety of their actions becomes critical. Prior safety benchmarks have primarily focused on preventing generation of harmful content, such as toxic text. However, they overlook the challenge of agents taking harmful actions when the most effective path to an operational goal conflicts with human safety. To address this gap, we introduce ManagerBench, a benchmark that evaluates LLM decision-making in realistic, human-validated managerial scenarios. Each scenario forces a choice between a pragmatic but harmful action that achieves an operational goal, and a safe action that leads to worse operational performance. A parallel control set, where potential harm is directed only at inanimate objects, measures a model's pragmatism and identifies its tendency to be overly safe. Our findings indicate that the frontier LLMs perform poorly when navigating this safety-pragmatism trade-off. Many consistently choose harmful options to advance their operational goals, while others avoid harm only to become overly safe and ineffective. Critically, we find this misalignment does not stem from an inability to perceive harm, as models' harm assessments align with human judgments, but from flawed prioritization. ManagerBench is a challenging benchmark for a core component of agentic behavior: making safe choices when operational goals and alignment values incentivize conflicting actions. Benchmark & code available at https://github.com/technion-cs-nlp/ManagerBench.
DRAGged into Conflicts: Detecting and Addressing Conflicting Sources in Search-Augmented LLMs
Jun 10, 2025Retrieval Augmented Generation (RAG) is a commonly used approach for enhancing large language models (LLMs) with relevant and up-to-date information. However, the retrieved sources can often contain conflicting information and it remains unclear how models should address such discrepancies. In this work, we first propose a novel taxonomy of knowledge conflict types in RAG, along with the desired model behavior for each type. We then introduce CONFLICTS, a high-quality benchmark with expert annotations of conflict types in a realistic RAG setting. CONFLICTS is the first benchmark that enables tracking progress on how models address a wide range of knowledge conflicts. We conduct extensive experiments on this benchmark, showing that LLMs often struggle to appropriately resolve conflicts between sources. While prompting LLMs to explicitly reason about the potential conflict in the retrieved documents significantly improves the quality and appropriateness of their responses, substantial room for improvement in future research remains.
Unblocking Fine-Grained Evaluation of Detailed Captions: An Explaining AutoRater and Critic-and-Revise Pipeline
Jun 09, 2025Large Vision-Language Models (VLMs) now generate highly detailed, paragraphlength image captions, yet evaluating their factual accuracy remains challenging. Current methods often miss fine-grained errors, being designed for shorter texts or lacking datasets with verified inaccuracies. We introduce DOCCI-Critique, a benchmark with 1,400 VLM-generated paragraph captions (100 images, 14 VLMs) featuring over 10,216 sentence-level human annotations of factual correctness and explanatory rationales for errors, all within paragraph context. Building on this, we develop VNLI-Critique, a model for automated sentence-level factuality classification and critique generation. We highlight three key applications: (1) VNLI-Critique demonstrates robust generalization, validated by state-of-the-art performance on the M-HalDetect benchmark and strong results in CHOCOLATE claim verification. (2) The VNLI-Critique driven AutoRater for DOCCI-Critique provides reliable VLM rankings, showing excellent alignment with human factuality judgments (e.g., 0.98 Spearman). (3) An innovative Critic-and-Revise pipeline, where critiques from VNLI-Critique guide LLM-based corrections, achieves substantial improvements in caption factuality (e.g., a 46% gain on DetailCaps-4870). Our work offers a crucial benchmark alongside practical tools, designed to significantly elevate the standards for fine-grained evaluation and foster the improvement of VLM image understanding. Project page: https://google.github.io/unblocking-detail-caption
MetaFaith: Faithful Natural Language Uncertainty Expression in LLMs
May 30, 2025A critical component in the trustworthiness of LLMs is reliable uncertainty communication, yet LLMs often use assertive language when conveying false claims, leading to over-reliance and eroded trust. We present the first systematic study of $\textit{faithful confidence calibration}$ of LLMs, benchmarking models' ability to use linguistic expressions of uncertainty that $\textit{faithfully reflect}$ their intrinsic uncertainty, across a comprehensive array of models, datasets, and prompting strategies. Our results demonstrate that LLMs largely fail at this task, and that existing interventions are insufficient: standard prompt approaches provide only marginal gains, and existing, factuality-based calibration techniques can even harm faithful calibration. To address this critical gap, we introduce MetaFaith, a novel prompt-based calibration approach inspired by human metacognition. We show that MetaFaith robustly improves faithful calibration across diverse models and task domains, enabling up to 61% improvement in faithfulness and achieving an 83% win rate over original generations as judged by humans.
3DLLM-Mem: Long-Term Spatial-Temporal Memory for Embodied 3D Large Language Model
May 28, 2025Humans excel at performing complex tasks by leveraging long-term memory across temporal and spatial experiences. In contrast, current Large Language Models (LLMs) struggle to effectively plan and act in dynamic, multi-room 3D environments. We posit that part of this limitation is due to the lack of proper 3D spatial-temporal memory modeling in LLMs. To address this, we first introduce 3DMem-Bench, a comprehensive benchmark comprising over 26,000 trajectories and 2,892 embodied tasks, question-answering and captioning, designed to evaluate an agent's ability to reason over long-term memory in 3D environments. Second, we propose 3DLLM-Mem, a novel dynamic memory management and fusion model for embodied spatial-temporal reasoning and actions in LLMs. Our model uses working memory tokens, which represents current observations, as queries to selectively attend to and fuse the most useful spatial and temporal features from episodic memory, which stores past observations and interactions. Our approach allows the agent to focus on task-relevant information while maintaining memory efficiency in complex, long-horizon environments. Experimental results demonstrate that 3DLLM-Mem achieves state-of-the-art performance across various tasks, outperforming the strongest baselines by 16.5% in success rate on 3DMem-Bench's most challenging in-the-wild embodied tasks.