 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnblocking Fine-Grained Evaluation of Detailed Captions: An Explaining AutoRater and Critic-and-Revise Pipeline
Jun 09, 2025Large Vision-Language Models (VLMs) now generate highly detailed, paragraphlength image captions, yet evaluating their factual accuracy remains challenging. Current methods often miss fine-grained errors, being designed for shorter texts or lacking datasets with verified inaccuracies. We introduce DOCCI-Critique, a benchmark with 1,400 VLM-generated paragraph captions (100 images, 14 VLMs) featuring over 10,216 sentence-level human annotations of factual correctness and explanatory rationales for errors, all within paragraph context. Building on this, we develop VNLI-Critique, a model for automated sentence-level factuality classification and critique generation. We highlight three key applications: (1) VNLI-Critique demonstrates robust generalization, validated by state-of-the-art performance on the M-HalDetect benchmark and strong results in CHOCOLATE claim verification. (2) The VNLI-Critique driven AutoRater for DOCCI-Critique provides reliable VLM rankings, showing excellent alignment with human factuality judgments (e.g., 0.98 Spearman). (3) An innovative Critic-and-Revise pipeline, where critiques from VNLI-Critique guide LLM-based corrections, achieves substantial improvements in caption factuality (e.g., a 46% gain on DetailCaps-4870). Our work offers a crucial benchmark alongside practical tools, designed to significantly elevate the standards for fine-grained evaluation and foster the improvement of VLM image understanding. Project page: https://google.github.io/unblocking-detail-caption
RefVNLI: Towards Scalable Evaluation of Subject-driven Text-to-image Generation
Apr 24, 2025Subject-driven text-to-image (T2I) generation aims to produce images that align with a given textual description, while preserving the visual identity from a referenced subject image. Despite its broad downstream applicability -- ranging from enhanced personalization in image generation to consistent character representation in video rendering -- progress in this field is limited by the lack of reliable automatic evaluation. Existing methods either assess only one aspect of the task (i.e., textual alignment or subject preservation), misalign with human judgments, or rely on costly API-based evaluation. To address this, we introduce RefVNLI, a cost-effective metric that evaluates both textual alignment and subject preservation in a single prediction. Trained on a large-scale dataset derived from video-reasoning benchmarks and image perturbations, RefVNLI outperforms or matches existing baselines across multiple benchmarks and subject categories (e.g., \emph{Animal}, \emph{Object}), achieving up to 6.4-point gains in textual alignment and 8.5-point gains in subject consistency. It also excels with lesser-known concepts, aligning with human preferences at over 87\% accuracy.
Mismatch Quest: Visual and Textual Feedback for Image-Text Misalignment
Dec 05, 2023



While existing image-text alignment models reach high quality binary assessments, they fall short of pinpointing the exact source of misalignment. In this paper, we present a method to provide detailed textual and visual explanation of detected misalignments between text-image pairs. We leverage large language models and visual grounding models to automatically construct a training set that holds plausible misaligned captions for a given image and corresponding textual explanations and visual indicators. We also publish a new human curated test set comprising ground-truth textual and visual misalignment annotations. Empirical results show that fine-tuning vision language models on our training set enables them to articulate misalignments and visually indicate them within images, outperforming strong baselines both on the binary alignment classification and the explanation generation tasks. Our method code and human curated test set are available at: https://mismatch-quest.github.io/
Human Motion Diffusion Model
Oct 03, 2022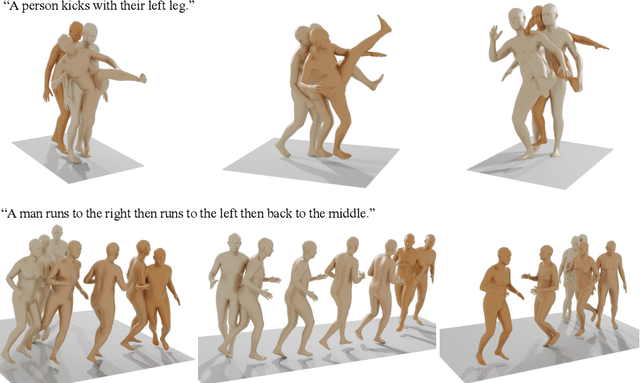
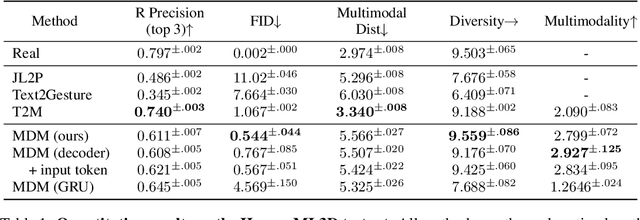
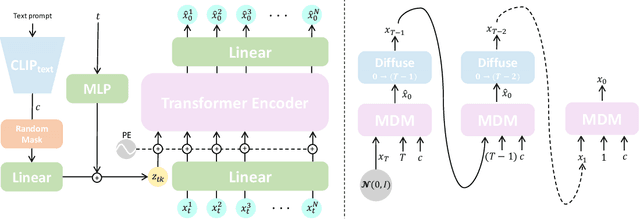
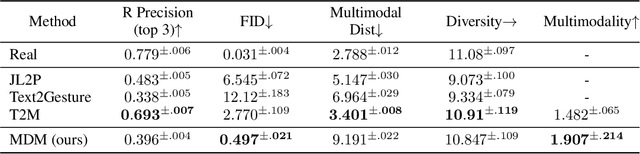
Natural and expressive human motion generation is the holy grail of computer animation. It is a challenging task, due to the diversity of possible motion, human perceptual sensitivity to it, and the difficulty of accurately describing it. Therefore, current generative solutions are either low-quality or limited in expressiveness. Diffusion models, which have already shown remarkable generative capabilities in other domains, are promising candidates for human motion due to their many-to-many nature, but they tend to be resource hungry and hard to control. In this paper, we introduce Motion Diffusion Model (MDM), a carefully adapted classifier-free diffusion-based generative model for the human motion domain. MDM is transformer-based, combining insights from motion generation literature. A notable design-choice is the prediction of the sample, rather than the noise, in each diffusion step. This facilitates the use of established geometric losses on the locations and velocities of the motion, such as the foot contact loss. As we demonstrate, MDM is a generic approach, enabling different modes of conditioning, and different generation tasks. We show that our model is trained with lightweight resources and yet achieves state-of-the-art results on leading benchmarks for text-to-motion and action-to-motion. https://guytevet.github.io/mdm-page/ .
MotionCLIP: Exposing Human Motion Generation to CLIP Space
Mar 15, 2022
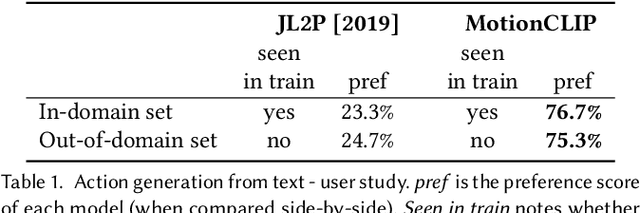
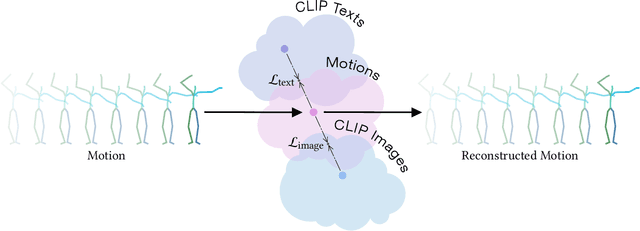
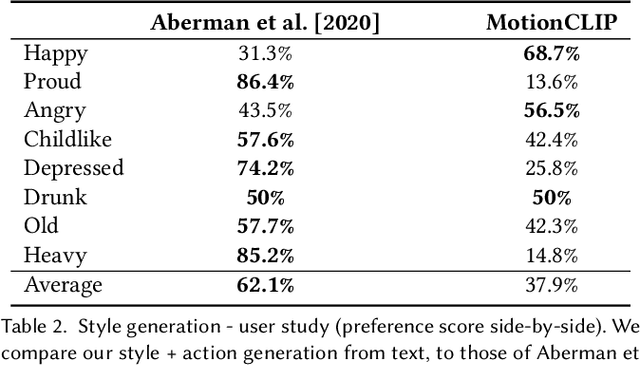
We introduce MotionCLIP, a 3D human motion auto-encoder featuring a latent embedding that is disentangled, well behaved, and supports highly semantic textual descriptions. MotionCLIP gains its unique power by aligning its latent space with that of the Contrastive Language-Image Pre-training (CLIP) model. Aligning the human motion manifold to CLIP space implicitly infuses the extremely rich semantic knowledge of CLIP into the manifold. In particular, it helps continuity by placing semantically similar motions close to one another, and disentanglement, which is inherited from the CLIP-space structure. MotionCLIP comprises a transformer-based motion auto-encoder, trained to reconstruct motion while being aligned to its text label's position in CLIP-space. We further leverage CLIP's unique visual understanding and inject an even stronger signal through aligning motion to rendered frames in a self-supervised manner. We show that although CLIP has never seen the motion domain, MotionCLIP offers unprecedented text-to-motion abilities, allowing out-of-domain actions, disentangled editing, and abstract language specification. For example, the text prompt "couch" is decoded into a sitting down motion, due to lingual similarity, and the prompt "Spiderman" results in a web-swinging-like solution that is far from seen during training. In addition, we show how the introduced latent space can be leveraged for motion interpolation, editing and recognition.
FLEX: Parameter-free Multi-view 3D Human Motion Reconstruction
May 05, 2021

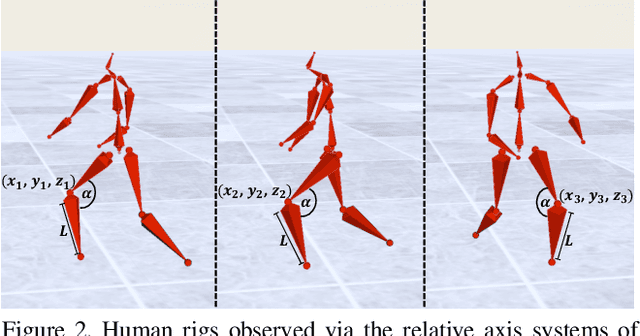
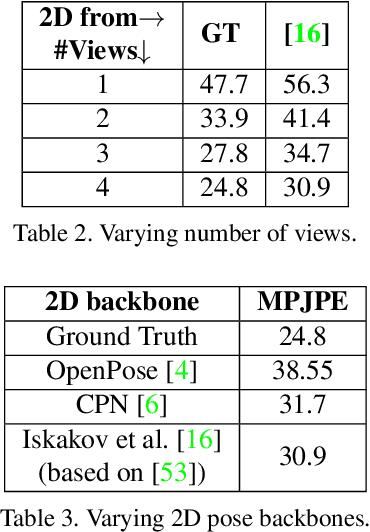
The increasing availability of video recordings made by multiple cameras has offered new means for mitigating occlusion and depth ambiguities in pose and motion reconstruction methods. Yet, multi-view algorithms strongly depend on camera parameters, in particular, the relative positions among the cameras. Such dependency becomes a hurdle once shifting to dynamic capture in uncontrolled settings. We introduce FLEX (Free muLti-view rEconstruXion), an end-to-end parameter-free multi-view model. FLEX is parameter-free in the sense that it does not require any camera parameters, neither intrinsic nor extrinsic. Our key idea is that the 3D angles between skeletal parts, as well as bone lengths, are invariant to the camera position. Hence, learning 3D rotations and bone lengths rather than locations allows predicting common values for all camera views. Our network takes multiple video streams, learns fused deep features through a novel multi-view fusion layer, and reconstructs a single consistent skeleton with temporally coherent joint rotations. We demonstrate quantitative and qualitative results on the Human3.6M and KTH Multi-view Football II datasets. We compare our model to state-of-the-art methods that are not parameter-free and show that in the absence of camera parameters, we outperform them by a large margin while obtaining comparable results when camera parameters are available. Code, trained models, video demonstration, and additional materials will be available on our project page.