 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoMo: A Large-Scale, Richly Organized Dataset and Semantic Taxonomy for Human Motion Generation
May 25, 2026Success in generative modeling across language, image, and video demonstrates that large, well-curated datasets are the key driver for building capable models. 3D Human motion, however, has lagged behind, constrained by an unsatisfying choice between small, high-fidelity motion capture datasets and large-scale in-the-wild collections dominated by static or low-quality sequences. We introduce RoMo, a rich, large-scale, carefully curated dataset of in-the-wild human motions that resolves these tradeoffs. To ensure quality, we introduce a taxonomy-aware filtering pipeline that aggressively removes static and artifact-prone sequences. Every sequence is annotated with detailed captions and organized by a novel three-level semantic taxonomy. This hierarchical structure enables fine-grained, per-category evaluation, that reveals model strengths and weaknesses obscured by global metrics. We demonstrate that models trained on RoMo achieve state-of-the-art fidelity and diversity while gaining a superior understanding of complex, subtle text prompts. Finally, we release the Motion Toolbox to standardize metrics, data conversion, and visualization, establishing a foundation for reproducible and interpretable motion generation research.
Express4D: Expressive, Friendly, and Extensible 4D Facial Motion Generation Benchmark
Aug 17, 2025Dynamic facial expression generation from natural language is a crucial task in Computer Graphics, with applications in Animation, Virtual Avatars, and Human-Computer Interaction. However, current generative models suffer from datasets that are either speech-driven or limited to coarse emotion labels, lacking the nuanced, expressive descriptions needed for fine-grained control, and were captured using elaborate and expensive equipment. We hence present a new dataset of facial motion sequences featuring nuanced performances and semantic annotation. The data is easily collected using commodity equipment and LLM-generated natural language instructions, in the popular ARKit blendshape format. This provides riggable motion, rich with expressive performances and labels. We accordingly train two baseline models, and evaluate their performance for future benchmarking. Using our Express4D dataset, the trained models can learn meaningful text-to-expression motion generation and capture the many-to-many mapping of the two modalities. The dataset, code, and video examples are available on our webpage: https://jaron1990.github.io/Express4D/
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Aug 13, 2025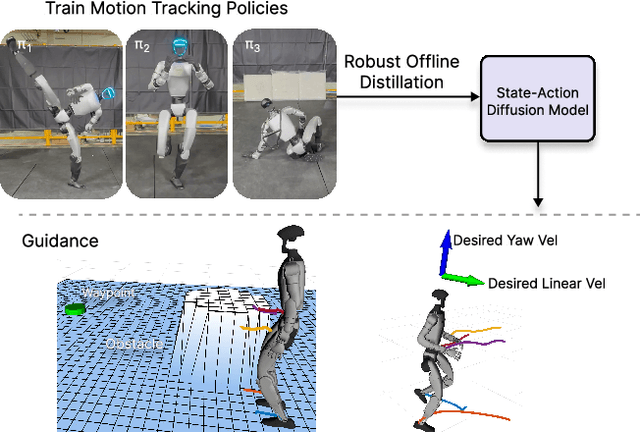



Learning skills from human motions offers a promising path toward generalizable policies for versatile humanoid whole-body control, yet two key cornerstones are missing: (1) a high-quality motion tracking framework that faithfully transforms large-scale kinematic references into robust and extremely dynamic motions on real hardware, and (2) a distillation approach that can effectively learn these motion primitives and compose them to solve downstream tasks. We address these gaps with BeyondMimic, a real-world framework to learn from human motions for versatile and naturalistic humanoid control via guided diffusion. Our framework provides a motion tracking pipeline capable of challenging skills such as jumping spins, sprinting, and cartwheels with state-of-the-art motion quality. Moving beyond simply mimicking existing motions, we further introduce a unified diffusion policy that enables zero-shot task-specific control at test time using simple cost functions. Deployed on hardware, BeyondMimic performs diverse tasks at test time, including waypoint navigation, joystick teleoperation, and obstacle avoidance, bridging sim-to-real motion tracking and flexible synthesis of human motion primitives for whole-body control. https://beyondmimic.github.io/.
HOIDiNi: Human-Object Interaction through Diffusion Noise Optimization
Jun 18, 2025We present HOIDiNi, a text-driven diffusion framework for synthesizing realistic and plausible human-object interaction (HOI). HOI generation is extremely challenging since it induces strict contact accuracies alongside a diverse motion manifold. While current literature trades off between realism and physical correctness, HOIDiNi optimizes directly in the noise space of a pretrained diffusion model using Diffusion Noise Optimization (DNO), achieving both. This is made feasible thanks to our observation that the problem can be separated into two phases: an object-centric phase, primarily making discrete choices of hand-object contact locations, and a human-centric phase that refines the full-body motion to realize this blueprint. This structured approach allows for precise hand-object contact without compromising motion naturalness. Quantitative, qualitative, and subjective evaluations on the GRAB dataset alone clearly indicate HOIDiNi outperforms prior works and baselines in contact accuracy, physical validity, and overall quality. Our results demonstrate the ability to generate complex, controllable interactions, including grasping, placing, and full-body coordination, driven solely by textual prompts. https://hoidini.github.io.
Dance Like a Chicken: Low-Rank Stylization for Human Motion Diffusion
Mar 25, 2025Text-to-motion generative models span a wide range of 3D human actions but struggle with nuanced stylistic attributes such as a "Chicken" style. Due to the scarcity of style-specific data, existing approaches pull the generative prior towards a reference style, which often results in out-of-distribution low quality generations. In this work, we introduce LoRA-MDM, a lightweight framework for motion stylization that generalizes to complex actions while maintaining editability. Our key insight is that adapting the generative prior to include the style, while preserving its overall distribution, is more effective than modifying each individual motion during generation. Building on this idea, LoRA-MDM learns to adapt the prior to include the reference style using only a few samples. The style can then be used in the context of different textual prompts for generation. The low-rank adaptation shifts the motion manifold in a semantically meaningful way, enabling realistic style infusion even for actions not present in the reference samples. Moreover, preserving the distribution structure enables advanced operations such as style blending and motion editing. We compare LoRA-MDM to state-of-the-art stylized motion generation methods and demonstrate a favorable balance between text fidelity and style consistency.
AnyTop: Character Animation Diffusion with Any Topology
Feb 24, 2025Generating motion for arbitrary skeletons is a longstanding challenge in computer graphics, remaining largely unexplored due to the scarcity of diverse datasets and the irregular nature of the data. In this work, we introduce AnyTop, a diffusion model that generates motions for diverse characters with distinct motion dynamics, using only their skeletal structure as input. Our work features a transformer-based denoising network, tailored for arbitrary skeleton learning, integrating topology information into the traditional attention mechanism. Additionally, by incorporating textual joint descriptions into the latent feature representation, AnyTop learns semantic correspondences between joints across diverse skeletons. Our evaluation demonstrates that AnyTop generalizes well, even with as few as three training examples per topology, and can produce motions for unseen skeletons as well. Furthermore, our model's latent space is highly informative, enabling downstream tasks such as joint correspondence, temporal segmentation and motion editing. Our webpage, https://anytop2025.github.io/Anytop-page, includes links to videos and code.
CLoSD: Closing the Loop between Simulation and Diffusion for multi-task character control
Oct 04, 2024



Motion diffusion models and Reinforcement Learning (RL) based control for physics-based simulations have complementary strengths for human motion generation. The former is capable of generating a wide variety of motions, adhering to intuitive control such as text, while the latter offers physically plausible motion and direct interaction with the environment. In this work, we present a method that combines their respective strengths. CLoSD is a text-driven RL physics-based controller, guided by diffusion generation for various tasks. Our key insight is that motion diffusion can serve as an on-the-fly universal planner for a robust RL controller. To this end, CLoSD maintains a closed-loop interaction between two modules -- a Diffusion Planner (DiP), and a tracking controller. DiP is a fast-responding autoregressive diffusion model, controlled by textual prompts and target locations, and the controller is a simple and robust motion imitator that continuously receives motion plans from DiP and provides feedback from the environment. CLoSD is capable of seamlessly performing a sequence of different tasks, including navigation to a goal location, striking an object with a hand or foot as specified in a text prompt, sitting down, and getting up. https://guytevet.github.io/CLoSD-page/
Monkey See, Monkey Do: Harnessing Self-attention in Motion Diffusion for Zero-shot Motion Transfer
Jun 10, 2024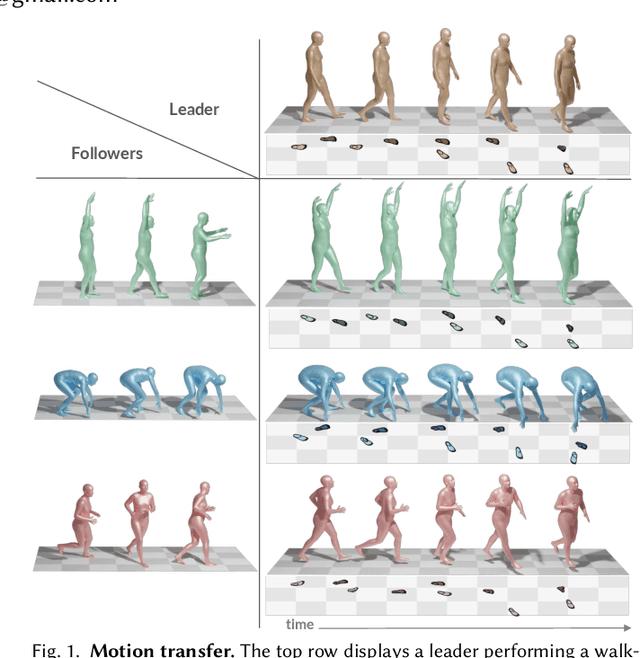
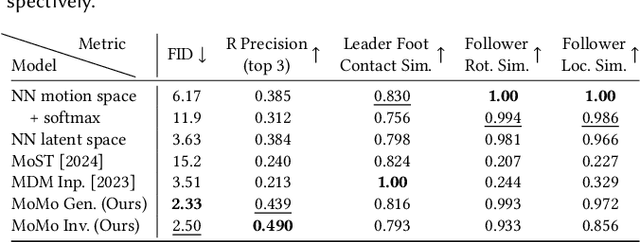
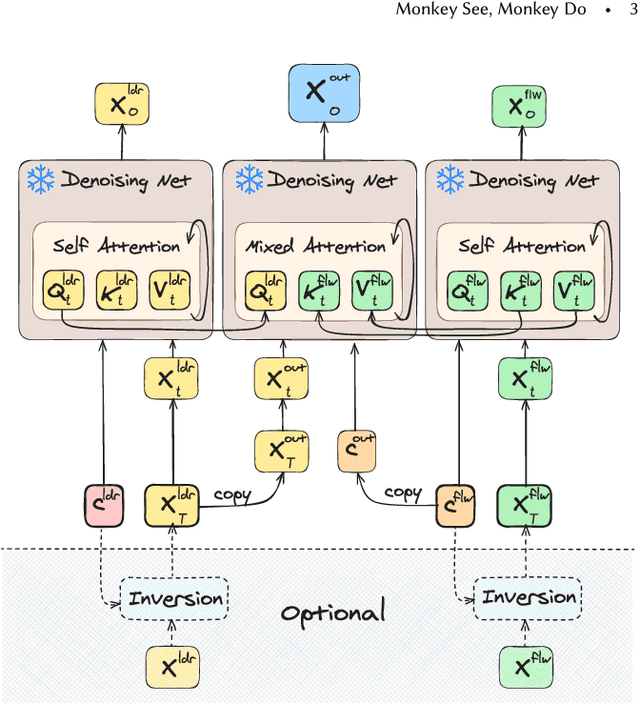
Given the remarkable results of motion synthesis with diffusion models, a natural question arises: how can we effectively leverage these models for motion editing? Existing diffusion-based motion editing methods overlook the profound potential of the prior embedded within the weights of pre-trained models, which enables manipulating the latent feature space; hence, they primarily center on handling the motion space. In this work, we explore the attention mechanism of pre-trained motion diffusion models. We uncover the roles and interactions of attention elements in capturing and representing intricate human motion patterns, and carefully integrate these elements to transfer a leader motion to a follower one while maintaining the nuanced characteristics of the follower, resulting in zero-shot motion transfer. Editing features associated with selected motions allows us to confront a challenge observed in prior motion diffusion approaches, which use general directives (e.g., text, music) for editing, ultimately failing to convey subtle nuances effectively. Our work is inspired by how a monkey closely imitates what it sees while maintaining its unique motion patterns; hence we call it Monkey See, Monkey Do, and dub it MoMo. Employing our technique enables accomplishing tasks such as synthesizing out-of-distribution motions, style transfer, and spatial editing. Furthermore, diffusion inversion is seldom employed for motions; as a result, editing efforts focus on generated motions, limiting the editability of real ones. MoMo harnesses motion inversion, extending its application to both real and generated motions. Experimental results show the advantage of our approach over the current art. In particular, unlike methods tailored for specific applications through training, our approach is applied at inference time, requiring no training. Our webpage is at https://monkeyseedocg.github.io.
Flexible Motion In-betweening with Diffusion Models
May 17, 2024Motion in-betweening, a fundamental task in character animation, consists of generating motion sequences that plausibly interpolate user-provided keyframe constraints. It has long been recognized as a labor-intensive and challenging process. We investigate the potential of diffusion models in generating diverse human motions guided by keyframes. Unlike previous inbetweening methods, we propose a simple unified model capable of generating precise and diverse motions that conform to a flexible range of user-specified spatial constraints, as well as text conditioning. To this end, we propose Conditional Motion Diffusion In-betweening (CondMDI) which allows for arbitrary dense-or-sparse keyframe placement and partial keyframe constraints while generating high-quality motions that are diverse and coherent with the given keyframes. We evaluate the performance of CondMDI on the text-conditioned HumanML3D dataset and demonstrate the versatility and efficacy of diffusion models for keyframe in-betweening. We further explore the use of guidance and imputation-based approaches for inference-time keyframing and compare CondMDI against these methods.
MAS: Multi-view Ancestral Sampling for 3D motion generation using 2D diffusion
Oct 23, 2023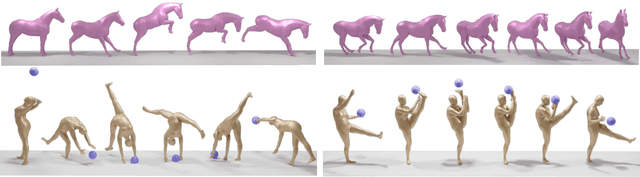

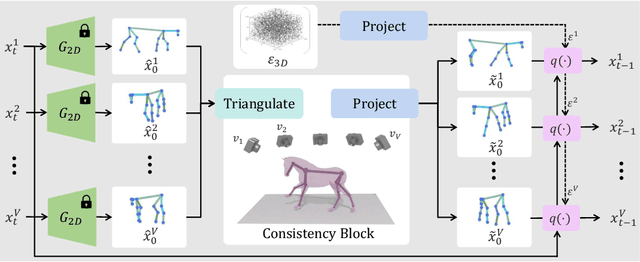

We introduce Multi-view Ancestral Sampling (MAS), a method for generating consistent multi-view 2D samples of a motion sequence, enabling the creation of its 3D counterpart. MAS leverages a diffusion model trained solely on 2D data, opening opportunities to exciting and diverse fields of motion previously under-explored as 3D data is scarce and hard to collect. MAS works by simultaneously denoising multiple 2D motion sequences representing the same motion from different angles. Our consistency block ensures consistency across all views at each diffusion step by combining the individual generations into a unified 3D sequence, and projecting it back to the original views for the next iteration. We demonstrate MAS on 2D pose data acquired from videos depicting professional basketball maneuvers, rhythmic gymnastic performances featuring a ball apparatus, and horse obstacle course races. In each of these domains, 3D motion capture is arduous, and yet, MAS generates diverse and realistic 3D sequences without textual conditioning. As we demonstrate, our ancestral sampling-based approach offers a more natural integration with the diffusion framework compared to popular denoising optimization-based approaches, and avoids common issues such as out-of-domain sampling, lack of details and mode-collapse. https://guytevet.github.io/mas-page/