 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpress4D: Expressive, Friendly, and Extensible 4D Facial Motion Generation Benchmark
Aug 17, 2025Dynamic facial expression generation from natural language is a crucial task in Computer Graphics, with applications in Animation, Virtual Avatars, and Human-Computer Interaction. However, current generative models suffer from datasets that are either speech-driven or limited to coarse emotion labels, lacking the nuanced, expressive descriptions needed for fine-grained control, and were captured using elaborate and expensive equipment. We hence present a new dataset of facial motion sequences featuring nuanced performances and semantic annotation. The data is easily collected using commodity equipment and LLM-generated natural language instructions, in the popular ARKit blendshape format. This provides riggable motion, rich with expressive performances and labels. We accordingly train two baseline models, and evaluate their performance for future benchmarking. Using our Express4D dataset, the trained models can learn meaningful text-to-expression motion generation and capture the many-to-many mapping of the two modalities. The dataset, code, and video examples are available on our webpage: https://jaron1990.github.io/Express4D/
Mismatch Quest: Visual and Textual Feedback for Image-Text Misalignment
Dec 05, 2023



While existing image-text alignment models reach high quality binary assessments, they fall short of pinpointing the exact source of misalignment. In this paper, we present a method to provide detailed textual and visual explanation of detected misalignments between text-image pairs. We leverage large language models and visual grounding models to automatically construct a training set that holds plausible misaligned captions for a given image and corresponding textual explanations and visual indicators. We also publish a new human curated test set comprising ground-truth textual and visual misalignment annotations. Empirical results show that fine-tuning vision language models on our training set enables them to articulate misalignments and visually indicate them within images, outperforming strong baselines both on the binary alignment classification and the explanation generation tasks. Our method code and human curated test set are available at: https://mismatch-quest.github.io/
Human Motion Diffusion as a Generative Prior
Mar 02, 2023

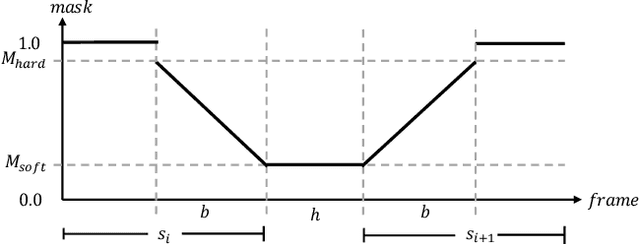
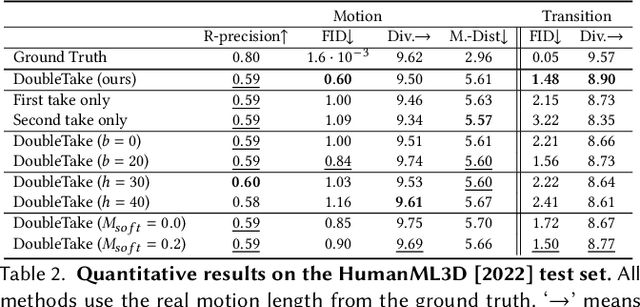
In recent months, we witness a leap forward as denoising diffusion models were introduced to Motion Generation. Yet, the main gap in this field remains the low availability of data. Furthermore, the expensive acquisition process of motion biases the already modest data towards short single-person sequences. With such a shortage, more elaborate generative tasks are left behind. In this paper, we show that this gap can be mitigated using a pre-trained diffusion-based model as a generative prior. We demonstrate the prior is effective for fine-tuning, in a few-, and even a zero-shot manner. For the zero-shot setting, we tackle the challenge of long sequence generation. We introduce DoubleTake, an inference-time method with which we demonstrate up to 10-minute long animations of prompted intervals and their meaningful and controlled transition, using the prior that was trained for 10-second generations. For the few-shot setting, we consider two-person generation. Using two fixed priors and as few as a dozen training examples, we learn a slim communication block, ComMDM, to infuse interaction between the two resulting motions. Finally, using fine-tuning, we train the prior to semantically complete motions from a single prescribed joint. Then, we use our DiffusionBlending to blend a few such models into a single one that responds well to the combination of the individual control signals, enabling fine-grained joint- and trajectory-level control and editing. Using an off-the-shelf state-of-the-art (SOTA) motion diffusion model as a prior, we evaluate our approach for the three mentioned cases and show that we consistently outperform SOTA models that were designed and trained for those tasks.
Human Motion Diffusion Model
Oct 03, 2022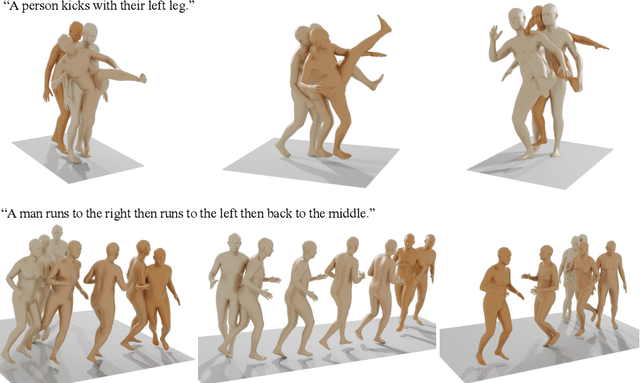
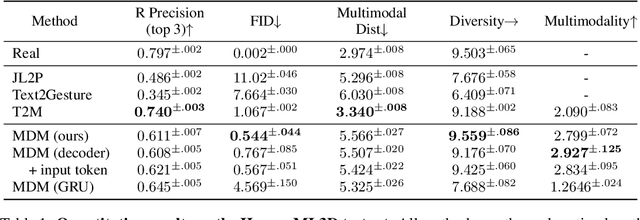
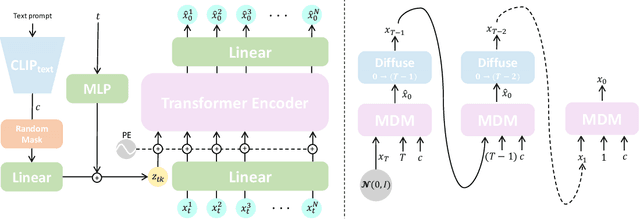
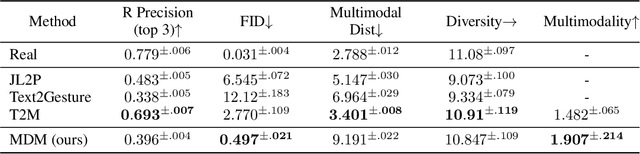
Natural and expressive human motion generation is the holy grail of computer animation. It is a challenging task, due to the diversity of possible motion, human perceptual sensitivity to it, and the difficulty of accurately describing it. Therefore, current generative solutions are either low-quality or limited in expressiveness. Diffusion models, which have already shown remarkable generative capabilities in other domains, are promising candidates for human motion due to their many-to-many nature, but they tend to be resource hungry and hard to control. In this paper, we introduce Motion Diffusion Model (MDM), a carefully adapted classifier-free diffusion-based generative model for the human motion domain. MDM is transformer-based, combining insights from motion generation literature. A notable design-choice is the prediction of the sample, rather than the noise, in each diffusion step. This facilitates the use of established geometric losses on the locations and velocities of the motion, such as the foot contact loss. As we demonstrate, MDM is a generic approach, enabling different modes of conditioning, and different generation tasks. We show that our model is trained with lightweight resources and yet achieves state-of-the-art results on leading benchmarks for text-to-motion and action-to-motion. https://guytevet.github.io/mdm-page/ .