 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAS: Multi-view Ancestral Sampling for 3D motion generation using 2D diffusion
Oct 23, 2023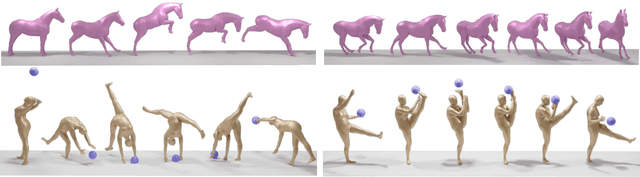


We introduce Multi-view Ancestral Sampling (MAS), a method for generating consistent multi-view 2D samples of a motion sequence, enabling the creation of its 3D counterpart. MAS leverages a diffusion model trained solely on 2D data, opening opportunities to exciting and diverse fields of motion previously under-explored as 3D data is scarce and hard to collect. MAS works by simultaneously denoising multiple 2D motion sequences representing the same motion from different angles. Our consistency block ensures consistency across all views at each diffusion step by combining the individual generations into a unified 3D sequence, and projecting it back to the original views for the next iteration. We demonstrate MAS on 2D pose data acquired from videos depicting professional basketball maneuvers, rhythmic gymnastic performances featuring a ball apparatus, and horse obstacle course races. In each of these domains, 3D motion capture is arduous, and yet, MAS generates diverse and realistic 3D sequences without textual conditioning. As we demonstrate, our ancestral sampling-based approach offers a more natural integration with the diffusion framework compared to popular denoising optimization-based approaches, and avoids common issues such as out-of-domain sampling, lack of details and mode-collapse. https://guytevet.github.io/mas-page/
Human Motion Diffusion as a Generative Prior
Mar 02, 2023

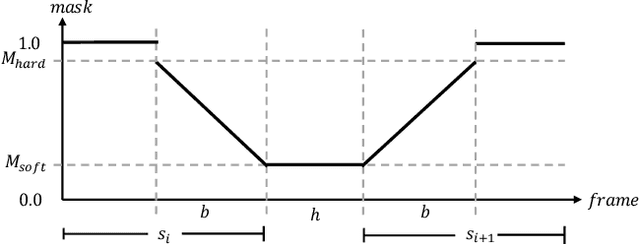
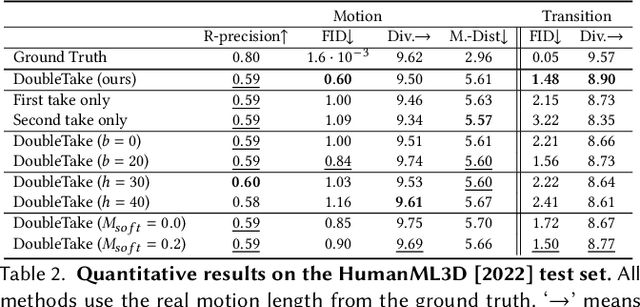
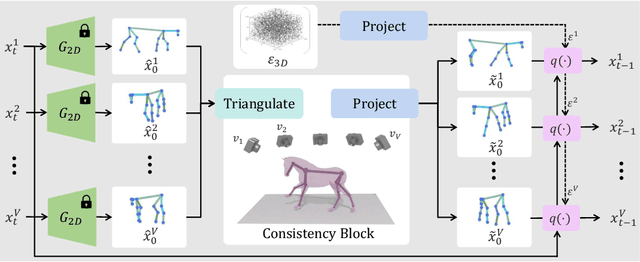
In recent months, we witness a leap forward as denoising diffusion models were introduced to Motion Generation. Yet, the main gap in this field remains the low availability of data. Furthermore, the expensive acquisition process of motion biases the already modest data towards short single-person sequences. With such a shortage, more elaborate generative tasks are left behind. In this paper, we show that this gap can be mitigated using a pre-trained diffusion-based model as a generative prior. We demonstrate the prior is effective for fine-tuning, in a few-, and even a zero-shot manner. For the zero-shot setting, we tackle the challenge of long sequence generation. We introduce DoubleTake, an inference-time method with which we demonstrate up to 10-minute long animations of prompted intervals and their meaningful and controlled transition, using the prior that was trained for 10-second generations. For the few-shot setting, we consider two-person generation. Using two fixed priors and as few as a dozen training examples, we learn a slim communication block, ComMDM, to infuse interaction between the two resulting motions. Finally, using fine-tuning, we train the prior to semantically complete motions from a single prescribed joint. Then, we use our DiffusionBlending to blend a few such models into a single one that responds well to the combination of the individual control signals, enabling fine-grained joint- and trajectory-level control and editing. Using an off-the-shelf state-of-the-art (SOTA) motion diffusion model as a prior, we evaluate our approach for the three mentioned cases and show that we consistently outperform SOTA models that were designed and trained for those tasks.