 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealMaster: Lifting Rendered Scenes into Photorealistic Video
Mar 24, 2026State-of-the-art video generation models produce remarkable photorealism, but they lack the precise control required to align generated content with specific scene requirements. Furthermore, without an underlying explicit geometry, these models cannot guarantee 3D consistency. Conversely, 3D engines offer granular control over every scene element and provide native 3D consistency by design, yet their output often remains trapped in the "uncanny valley". Bridging this sim-to-real gap requires both structural precision, where the output must exactly preserve the geometry and dynamics of the input, and global semantic transformation, where materials, lighting, and textures must be holistically transformed to achieve photorealism. We present RealMaster, a method that leverages video diffusion models to lift rendered video into photorealistic video while maintaining full alignment with the output of the 3D engine. To train this model, we generate a paired dataset via an anchor-based propagation strategy, where the first and last frames are enhanced for realism and propagated across the intermediate frames using geometric conditioning cues. We then train an IC-LoRA on these paired videos to distill the high-quality outputs of the pipeline into a model that generalizes beyond the pipeline's constraints, handling objects and characters that appear mid-sequence and enabling inference without requiring anchor frames. Evaluated on complex GTA-V sequences, RealMaster significantly outperforms existing video editing baselines, improving photorealism while preserving the geometry, dynamics, and identity specified by the original 3D control.
PEGAsus: 3D Personalization of Geometry and Appearance
Feb 09, 2026We present PEGAsus, a new framework capable of generating Personalized 3D shapes by learning shape concepts at both Geometry and Appearance levels. First, we formulate 3D shape personalization as extracting reusable, category-agnostic geometric and appearance attributes from reference shapes, and composing these attributes with text to generate novel shapes. Second, we design a progressive optimization strategy to learn shape concepts at both the geometry and appearance levels, decoupling the shape concept learning process. Third, we extend our approach to region-wise concept learning, enabling flexible concept extraction, with context-aware and context-free losses. Extensive experimental results show that PEGAsus is able to effectively extract attributes from a wide range of reference shapes and then flexibly compose these concepts with text to synthesize new shapes. This enables fine-grained control over shape generation and supports the creation of diverse, personalized results, even in challenging cross-category scenarios. Both quantitative and qualitative experiments demonstrate that our approach outperforms existing state-of-the-art solutions.
ShapeUP: Scalable Image-Conditioned 3D Editing
Feb 05, 2026Recent advancements in 3D foundation models have enabled the generation of high-fidelity assets, yet precise 3D manipulation remains a significant challenge. Existing 3D editing frameworks often face a difficult trade-off between visual controllability, geometric consistency, and scalability. Specifically, optimization-based methods are prohibitively slow, multi-view 2D propagation techniques suffer from visual drift, and training-free latent manipulation methods are inherently bound by frozen priors and cannot directly benefit from scaling. In this work, we present ShapeUP, a scalable, image-conditioned 3D editing framework that formulates editing as a supervised latent-to-latent translation within a native 3D representation. This formulation allows ShapeUP to build on a pretrained 3D foundation model, leveraging its strong generative prior while adapting it to editing through supervised training. In practice, ShapeUP is trained on triplets consisting of a source 3D shape, an edited 2D image, and the corresponding edited 3D shape, and learns a direct mapping using a 3D Diffusion Transformer (DiT). This image-as-prompt approach enables fine-grained visual control over both local and global edits and achieves implicit, mask-free localization, while maintaining strict structural consistency with the original asset. Our extensive evaluations demonstrate that ShapeUP consistently outperforms current trained and training-free baselines in both identity preservation and edit fidelity, offering a robust and scalable paradigm for native 3D content creation.
Untwisting RoPE: Frequency Control for Shared Attention in DiTs
Feb 04, 2026Positional encodings are essential to transformer-based generative models, yet their behavior in multimodal and attention-sharing settings is not fully understood. In this work, we present a principled analysis of Rotary Positional Embeddings (RoPE), showing that RoPE naturally decomposes into frequency components with distinct positional sensitivities. We demonstrate that this frequency structure explains why shared-attention mechanisms, where a target image is generated while attending to tokens from a reference image, can lead to reference copying, in which the model reproduces content from the reference instead of extracting only its stylistic cues. Our analysis reveals that the high-frequency components of RoPE dominate the attention computation, forcing queries to attend mainly to spatially aligned reference tokens and thereby inducing this unintended copying behavior. Building on these insights, we introduce a method for selectively modulating RoPE frequency bands so that attention reflects semantic similarity rather than strict positional alignment. Applied to modern transformer-based diffusion architectures, where all tokens share attention, this modulation restores stable and meaningful shared attention. As a result, it enables effective control over the degree of style transfer versus content copying, yielding a proper style-aligned generation process in which stylistic attributes are transferred without duplicating reference content.
JUST-DUB-IT: Video Dubbing via Joint Audio-Visual Diffusion
Jan 29, 2026Audio-Visual Foundation Models, which are pretrained to jointly generate sound and visual content, have recently shown an unprecedented ability to model multi-modal generation and editing, opening new opportunities for downstream tasks. Among these tasks, video dubbing could greatly benefit from such priors, yet most existing solutions still rely on complex, task-specific pipelines that struggle in real-world settings. In this work, we introduce a single-model approach that adapts a foundational audio-video diffusion model for video-to-video dubbing via a lightweight LoRA. The LoRA enables the model to condition on an input audio-video while jointly generating translated audio and synchronized facial motion. To train this LoRA, we leverage the generative model itself to synthesize paired multilingual videos of the same speaker. Specifically, we generate multilingual videos with language switches within a single clip, and then inpaint the face and audio in each half to match the language of the other half. By leveraging the rich generative prior of the audio-visual model, our approach preserves speaker identity and lip synchronization while remaining robust to complex motion and real-world dynamics. We demonstrate that our approach produces high-quality dubbed videos with improved visual fidelity, lip synchronization, and robustness compared to existing dubbing pipelines.
Visual Diffusion Models are Geometric Solvers
Oct 24, 2025In this paper we show that visual diffusion models can serve as effective geometric solvers: they can directly reason about geometric problems by working in pixel space. We first demonstrate this on the Inscribed Square Problem, a long-standing problem in geometry that asks whether every Jordan curve contains four points forming a square. We then extend the approach to two other well-known hard geometric problems: the Steiner Tree Problem and the Simple Polygon Problem. Our method treats each problem instance as an image and trains a standard visual diffusion model that transforms Gaussian noise into an image representing a valid approximate solution that closely matches the exact one. The model learns to transform noisy geometric structures into correct configurations, effectively recasting geometric reasoning as image generation. Unlike prior work that necessitates specialized architectures and domain-specific adaptations when applying diffusion to parametric geometric representations, we employ a standard visual diffusion model that operates on the visual representation of the problem. This simplicity highlights a surprising bridge between generative modeling and geometric problem solving. Beyond the specific problems studied here, our results point toward a broader paradigm: operating in image space provides a general and practical framework for approximating notoriously hard problems, and opens the door to tackling a far wider class of challenging geometric tasks.
SAEdit: Token-level control for continuous image editing via Sparse AutoEncoder
Oct 06, 2025Large-scale text-to-image diffusion models have become the backbone of modern image editing, yet text prompts alone do not offer adequate control over the editing process. Two properties are especially desirable: disentanglement, where changing one attribute does not unintentionally alter others, and continuous control, where the strength of an edit can be smoothly adjusted. We introduce a method for disentangled and continuous editing through token-level manipulation of text embeddings. The edits are applied by manipulating the embeddings along carefully chosen directions, which control the strength of the target attribute. To identify such directions, we employ a Sparse Autoencoder (SAE), whose sparse latent space exposes semantically isolated dimensions. Our method operates directly on text embeddings without modifying the diffusion process, making it model agnostic and broadly applicable to various image synthesis backbones. Experiments show that it enables intuitive and efficient manipulations with continuous control across diverse attributes and domains.
Zero-Shot Dynamic Concept Personalization with Grid-Based LoRA
Jul 23, 2025
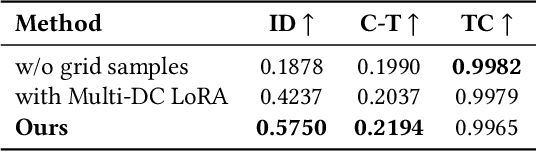
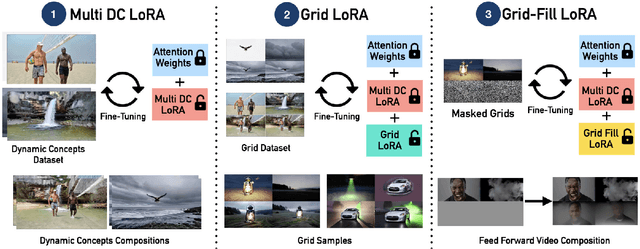
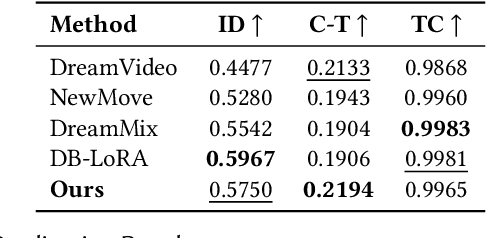
Recent advances in text-to-video generation have enabled high-quality synthesis from text and image prompts. While the personalization of dynamic concepts, which capture subject-specific appearance and motion from a single video, is now feasible, most existing methods require per-instance fine-tuning, limiting scalability. We introduce a fully zero-shot framework for dynamic concept personalization in text-to-video models. Our method leverages structured 2x2 video grids that spatially organize input and output pairs, enabling the training of lightweight Grid-LoRA adapters for editing and composition within these grids. At inference, a dedicated Grid Fill module completes partially observed layouts, producing temporally coherent and identity preserving outputs. Once trained, the entire system operates in a single forward pass, generalizing to previously unseen dynamic concepts without any test-time optimization. Extensive experiments demonstrate high-quality and consistent results across a wide range of subjects beyond trained concepts and editing scenarios.
EditP23: 3D Editing via Propagation of Image Prompts to Multi-View
Jun 25, 2025We present EditP23, a method for mask-free 3D editing that propagates 2D image edits to multi-view representations in a 3D-consistent manner. In contrast to traditional approaches that rely on text-based prompting or explicit spatial masks, EditP23 enables intuitive edits by conditioning on a pair of images: an original view and its user-edited counterpart. These image prompts are used to guide an edit-aware flow in the latent space of a pre-trained multi-view diffusion model, allowing the edit to be coherently propagated across views. Our method operates in a feed-forward manner, without optimization, and preserves the identity of the original object, in both structure and appearance. We demonstrate its effectiveness across a range of object categories and editing scenarios, achieving high fidelity to the source while requiring no manual masks.
Unblocking Fine-Grained Evaluation of Detailed Captions: An Explaining AutoRater and Critic-and-Revise Pipeline
Jun 09, 2025Large Vision-Language Models (VLMs) now generate highly detailed, paragraphlength image captions, yet evaluating their factual accuracy remains challenging. Current methods often miss fine-grained errors, being designed for shorter texts or lacking datasets with verified inaccuracies. We introduce DOCCI-Critique, a benchmark with 1,400 VLM-generated paragraph captions (100 images, 14 VLMs) featuring over 10,216 sentence-level human annotations of factual correctness and explanatory rationales for errors, all within paragraph context. Building on this, we develop VNLI-Critique, a model for automated sentence-level factuality classification and critique generation. We highlight three key applications: (1) VNLI-Critique demonstrates robust generalization, validated by state-of-the-art performance on the M-HalDetect benchmark and strong results in CHOCOLATE claim verification. (2) The VNLI-Critique driven AutoRater for DOCCI-Critique provides reliable VLM rankings, showing excellent alignment with human factuality judgments (e.g., 0.98 Spearman). (3) An innovative Critic-and-Revise pipeline, where critiques from VNLI-Critique guide LLM-based corrections, achieves substantial improvements in caption factuality (e.g., a 46% gain on DetailCaps-4870). Our work offers a crucial benchmark alongside practical tools, designed to significantly elevate the standards for fine-grained evaluation and foster the improvement of VLM image understanding. Project page: https://google.github.io/unblocking-detail-caption