 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiece it Together: Part-Based Concepting with IP-Priors
Mar 13, 2025Advanced generative models excel at synthesizing images but often rely on text-based conditioning. Visual designers, however, often work beyond language, directly drawing inspiration from existing visual elements. In many cases, these elements represent only fragments of a potential concept-such as an uniquely structured wing, or a specific hairstyle-serving as inspiration for the artist to explore how they can come together creatively into a coherent whole. Recognizing this need, we introduce a generative framework that seamlessly integrates a partial set of user-provided visual components into a coherent composition while simultaneously sampling the missing parts needed to generate a plausible and complete concept. Our approach builds on a strong and underexplored representation space, extracted from IP-Adapter+, on which we train IP-Prior, a lightweight flow-matching model that synthesizes coherent compositions based on domain-specific priors, enabling diverse and context-aware generations. Additionally, we present a LoRA-based fine-tuning strategy that significantly improves prompt adherence in IP-Adapter+ for a given task, addressing its common trade-off between reconstruction quality and prompt adherence.
NeuralSVG: An Implicit Representation for Text-to-Vector Generation
Jan 07, 2025Vector graphics are essential in design, providing artists with a versatile medium for creating resolution-independent and highly editable visual content. Recent advancements in vision-language and diffusion models have fueled interest in text-to-vector graphics generation. However, existing approaches often suffer from over-parameterized outputs or treat the layered structure - a core feature of vector graphics - as a secondary goal, diminishing their practical use. Recognizing the importance of layered SVG representations, we propose NeuralSVG, an implicit neural representation for generating vector graphics from text prompts. Inspired by Neural Radiance Fields (NeRFs), NeuralSVG encodes the entire scene into the weights of a small MLP network, optimized using Score Distillation Sampling (SDS). To encourage a layered structure in the generated SVG, we introduce a dropout-based regularization technique that strengthens the standalone meaning of each shape. We additionally demonstrate that utilizing a neural representation provides an added benefit of inference-time control, enabling users to dynamically adapt the generated SVG based on user-provided inputs, all with a single learned representation. Through extensive qualitative and quantitative evaluations, we demonstrate that NeuralSVG outperforms existing methods in generating structured and flexible SVG.
InstantRestore: Single-Step Personalized Face Restoration with Shared-Image Attention
Dec 09, 2024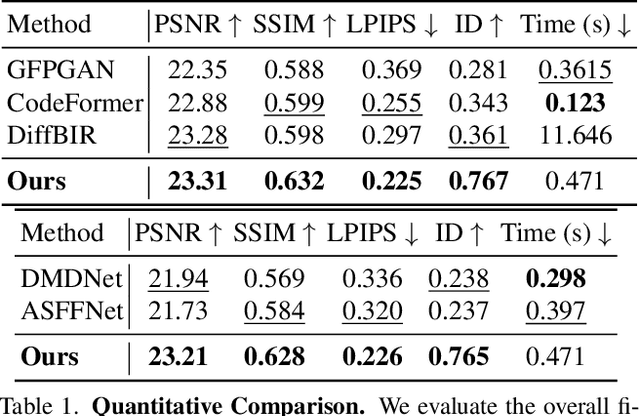
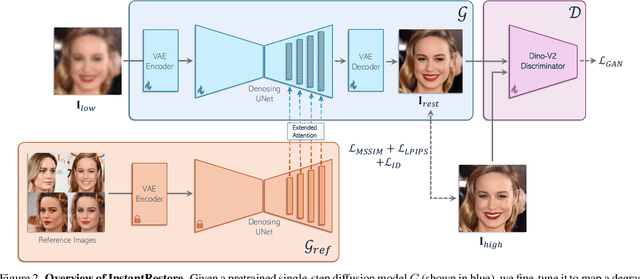
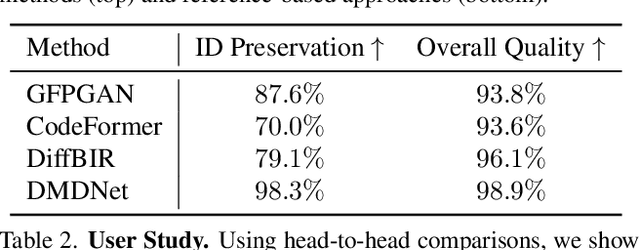
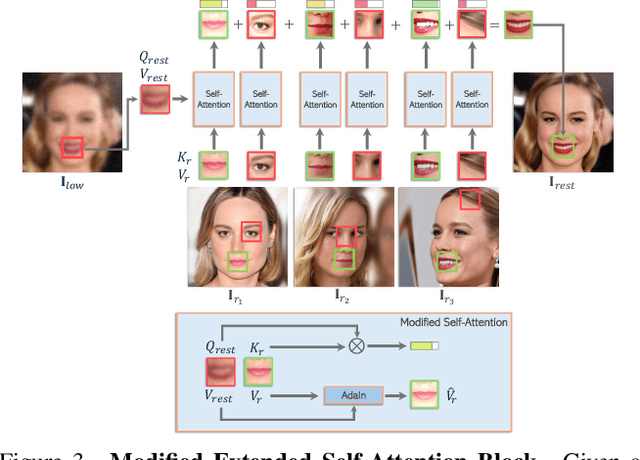
Face image restoration aims to enhance degraded facial images while addressing challenges such as diverse degradation types, real-time processing demands, and, most crucially, the preservation of identity-specific features. Existing methods often struggle with slow processing times and suboptimal restoration, especially under severe degradation, failing to accurately reconstruct finer-level identity details. To address these issues, we introduce InstantRestore, a novel framework that leverages a single-step image diffusion model and an attention-sharing mechanism for fast and personalized face restoration. Additionally, InstantRestore incorporates a novel landmark attention loss, aligning key facial landmarks to refine the attention maps, enhancing identity preservation. At inference time, given a degraded input and a small (~4) set of reference images, InstantRestore performs a single forward pass through the network to achieve near real-time performance. Unlike prior approaches that rely on full diffusion processes or per-identity model tuning, InstantRestore offers a scalable solution suitable for large-scale applications. Extensive experiments demonstrate that InstantRestore outperforms existing methods in quality and speed, making it an appealing choice for identity-preserving face restoration.
ComfyGen: Prompt-Adaptive Workflows for Text-to-Image Generation
Oct 02, 2024



The practical use of text-to-image generation has evolved from simple, monolithic models to complex workflows that combine multiple specialized components. While workflow-based approaches can lead to improved image quality, crafting effective workflows requires significant expertise, owing to the large number of available components, their complex inter-dependence, and their dependence on the generation prompt. Here, we introduce the novel task of prompt-adaptive workflow generation, where the goal is to automatically tailor a workflow to each user prompt. We propose two LLM-based approaches to tackle this task: a tuning-based method that learns from user-preference data, and a training-free method that uses the LLM to select existing flows. Both approaches lead to improved image quality when compared to monolithic models or generic, prompt-independent workflows. Our work shows that prompt-dependent flow prediction offers a new pathway to improving text-to-image generation quality, complementing existing research directions in the field.
pOps: Photo-Inspired Diffusion Operators
Jun 03, 2024Text-guided image generation enables the creation of visual content from textual descriptions. However, certain visual concepts cannot be effectively conveyed through language alone. This has sparked a renewed interest in utilizing the CLIP image embedding space for more visually-oriented tasks through methods such as IP-Adapter. Interestingly, the CLIP image embedding space has been shown to be semantically meaningful, where linear operations within this space yield semantically meaningful results. Yet, the specific meaning of these operations can vary unpredictably across different images. To harness this potential, we introduce pOps, a framework that trains specific semantic operators directly on CLIP image embeddings. Each pOps operator is built upon a pretrained Diffusion Prior model. While the Diffusion Prior model was originally trained to map between text embeddings and image embeddings, we demonstrate that it can be tuned to accommodate new input conditions, resulting in a diffusion operator. Working directly over image embeddings not only improves our ability to learn semantic operations but also allows us to directly use a textual CLIP loss as an additional supervision when needed. We show that pOps can be used to learn a variety of photo-inspired operators with distinct semantic meanings, highlighting the semantic diversity and potential of our proposed approach.
MyVLM: Personalizing VLMs for User-Specific Queries
Mar 21, 2024



Recent large-scale vision-language models (VLMs) have demonstrated remarkable capabilities in understanding and generating textual descriptions for visual content. However, these models lack an understanding of user-specific concepts. In this work, we take a first step toward the personalization of VLMs, enabling them to learn and reason over user-provided concepts. For example, we explore whether these models can learn to recognize you in an image and communicate what you are doing, tailoring the model to reflect your personal experiences and relationships. To effectively recognize a variety of user-specific concepts, we augment the VLM with external concept heads that function as toggles for the model, enabling the VLM to identify the presence of specific target concepts in a given image. Having recognized the concept, we learn a new concept embedding in the intermediate feature space of the VLM. This embedding is tasked with guiding the language model to naturally integrate the target concept in its generated response. We apply our technique to BLIP-2 and LLaVA for personalized image captioning and further show its applicability for personalized visual question-answering. Our experiments demonstrate our ability to generalize to unseen images of learned concepts while preserving the model behavior on unrelated inputs.
Breathing Life Into Sketches Using Text-to-Video Priors
Nov 21, 2023
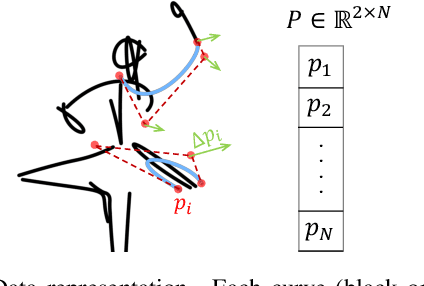
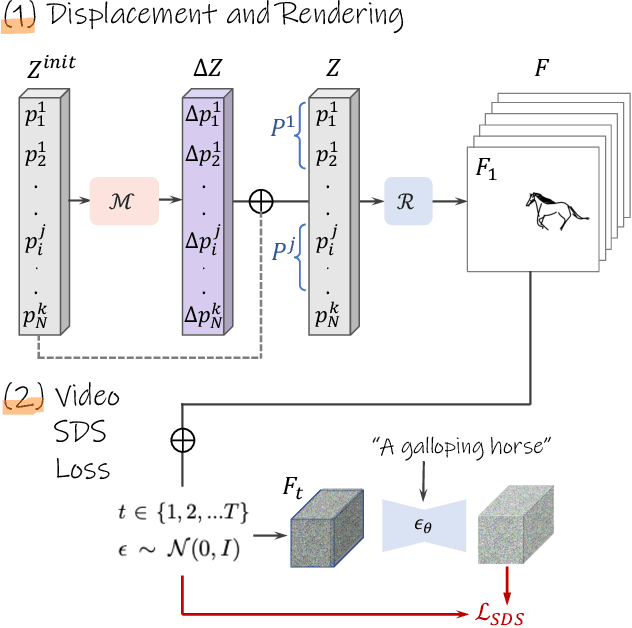
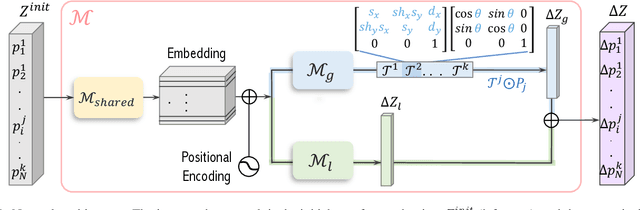
A sketch is one of the most intuitive and versatile tools humans use to convey their ideas visually. An animated sketch opens another dimension to the expression of ideas and is widely used by designers for a variety of purposes. Animating sketches is a laborious process, requiring extensive experience and professional design skills. In this work, we present a method that automatically adds motion to a single-subject sketch (hence, "breathing life into it"), merely by providing a text prompt indicating the desired motion. The output is a short animation provided in vector representation, which can be easily edited. Our method does not require extensive training, but instead leverages the motion prior of a large pretrained text-to-video diffusion model using a score-distillation loss to guide the placement of strokes. To promote natural and smooth motion and to better preserve the sketch's appearance, we model the learned motion through two components. The first governs small local deformations and the second controls global affine transformations. Surprisingly, we find that even models that struggle to generate sketch videos on their own can still serve as a useful backbone for animating abstract representations.
Cross-Image Attention for Zero-Shot Appearance Transfer
Nov 06, 2023Recent advancements in text-to-image generative models have demonstrated a remarkable ability to capture a deep semantic understanding of images. In this work, we leverage this semantic knowledge to transfer the visual appearance between objects that share similar semantics but may differ significantly in shape. To achieve this, we build upon the self-attention layers of these generative models and introduce a cross-image attention mechanism that implicitly establishes semantic correspondences across images. Specifically, given a pair of images -- one depicting the target structure and the other specifying the desired appearance -- our cross-image attention combines the queries corresponding to the structure image with the keys and values of the appearance image. This operation, when applied during the denoising process, leverages the established semantic correspondences to generate an image combining the desired structure and appearance. In addition, to improve the output image quality, we harness three mechanisms that either manipulate the noisy latent codes or the model's internal representations throughout the denoising process. Importantly, our approach is zero-shot, requiring no optimization or training. Experiments show that our method is effective across a wide range of object categories and is robust to variations in shape, size, and viewpoint between the two input images.
ConceptLab: Creative Generation using Diffusion Prior Constraints
Aug 03, 2023Recent text-to-image generative models have enabled us to transform our words into vibrant, captivating imagery. The surge of personalization techniques that has followed has also allowed us to imagine unique concepts in new scenes. However, an intriguing question remains: How can we generate a new, imaginary concept that has never been seen before? In this paper, we present the task of creative text-to-image generation, where we seek to generate new members of a broad category (e.g., generating a pet that differs from all existing pets). We leverage the under-studied Diffusion Prior models and show that the creative generation problem can be formulated as an optimization process over the output space of the diffusion prior, resulting in a set of "prior constraints". To keep our generated concept from converging into existing members, we incorporate a question-answering model that adaptively adds new constraints to the optimization problem, encouraging the model to discover increasingly more unique creations. Finally, we show that our prior constraints can also serve as a strong mixing mechanism allowing us to create hybrids between generated concepts, introducing even more flexibility into the creative process.
A Neural Space-Time Representation for Text-to-Image Personalization
May 24, 2023A key aspect of text-to-image personalization methods is the manner in which the target concept is represented within the generative process. This choice greatly affects the visual fidelity, downstream editability, and disk space needed to store the learned concept. In this paper, we explore a new text-conditioning space that is dependent on both the denoising process timestep (time) and the denoising U-Net layers (space) and showcase its compelling properties. A single concept in the space-time representation is composed of hundreds of vectors, one for each combination of time and space, making this space challenging to optimize directly. Instead, we propose to implicitly represent a concept in this space by optimizing a small neural mapper that receives the current time and space parameters and outputs the matching token embedding. In doing so, the entire personalized concept is represented by the parameters of the learned mapper, resulting in a compact, yet expressive, representation. Similarly to other personalization methods, the output of our neural mapper resides in the input space of the text encoder. We observe that one can significantly improve the convergence and visual fidelity of the concept by introducing a textual bypass, where our neural mapper additionally outputs a residual that is added to the output of the text encoder. Finally, we show how one can impose an importance-based ordering over our implicit representation, providing users control over the reconstruction and editability of the learned concept using a single trained model. We demonstrate the effectiveness of our approach over a range of concepts and prompts, showing our method's ability to generate high-quality and controllable compositions without fine-tuning any parameters of the generative model itself.