 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Analysis and Generation via a Semantic Progress Function
Apr 24, 2026Transformations produced by image and video generation models often evolve in a highly non-linear manner: long stretches where the content barely changes are followed by sudden, abrupt semantic jumps. To analyze and correct this behavior, we introduce a Semantic Progress Function, a one-dimensional representation that captures how the meaning of a given sequence evolves over time. For each frame, we compute distances between semantic embeddings and fit a smooth curve that reflects the cumulative semantic shift across the sequence. Departures of this curve from a straight line reveal uneven semantic pacing. Building on this insight, we propose a semantic linearization procedure that reparameterizes (or retimes) the sequence so that semantic change unfolds at a constant rate, yielding smoother and more coherent transitions. Beyond linearization, our framework provides a model-agnostic foundation for identifying temporal irregularities, comparing semantic pacing across different generators, and steering both generated and real-world video sequences toward arbitrary target pacing.
A Neural Space-Time Representation for Text-to-Image Personalization
May 24, 2023A key aspect of text-to-image personalization methods is the manner in which the target concept is represented within the generative process. This choice greatly affects the visual fidelity, downstream editability, and disk space needed to store the learned concept. In this paper, we explore a new text-conditioning space that is dependent on both the denoising process timestep (time) and the denoising U-Net layers (space) and showcase its compelling properties. A single concept in the space-time representation is composed of hundreds of vectors, one for each combination of time and space, making this space challenging to optimize directly. Instead, we propose to implicitly represent a concept in this space by optimizing a small neural mapper that receives the current time and space parameters and outputs the matching token embedding. In doing so, the entire personalized concept is represented by the parameters of the learned mapper, resulting in a compact, yet expressive, representation. Similarly to other personalization methods, the output of our neural mapper resides in the input space of the text encoder. We observe that one can significantly improve the convergence and visual fidelity of the concept by introducing a textual bypass, where our neural mapper additionally outputs a residual that is added to the output of the text encoder. Finally, we show how one can impose an importance-based ordering over our implicit representation, providing users control over the reconstruction and editability of the learned concept using a single trained model. We demonstrate the effectiveness of our approach over a range of concepts and prompts, showing our method's ability to generate high-quality and controllable compositions without fine-tuning any parameters of the generative model itself.
Set-the-Scene: Global-Local Training for Generating Controllable NeRF Scenes
Mar 23, 2023



Recent breakthroughs in text-guided image generation have led to remarkable progress in the field of 3D synthesis from text. By optimizing neural radiance fields (NeRF) directly from text, recent methods are able to produce remarkable results. Yet, these methods are limited in their control of each object's placement or appearance, as they represent the scene as a whole. This can be a major issue in scenarios that require refining or manipulating objects in the scene. To remedy this deficit, we propose a novel GlobalLocal training framework for synthesizing a 3D scene using object proxies. A proxy represents the object's placement in the generated scene and optionally defines its coarse geometry. The key to our approach is to represent each object as an independent NeRF. We alternate between optimizing each NeRF on its own and as part of the full scene. Thus, a complete representation of each object can be learned, while also creating a harmonious scene with style and lighting match. We show that using proxies allows a wide variety of editing options, such as adjusting the placement of each independent object, removing objects from a scene, or refining an object. Our results show that Set-the-Scene offers a powerful solution for scene synthesis and manipulation, filling a crucial gap in controllable text-to-3D synthesis.
TEXTure: Text-Guided Texturing of 3D Shapes
Feb 03, 2023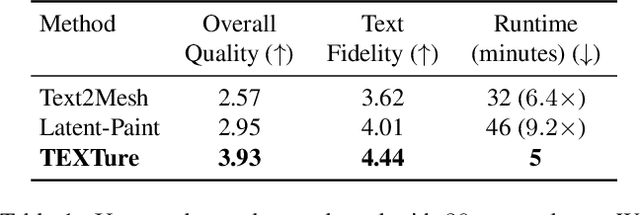


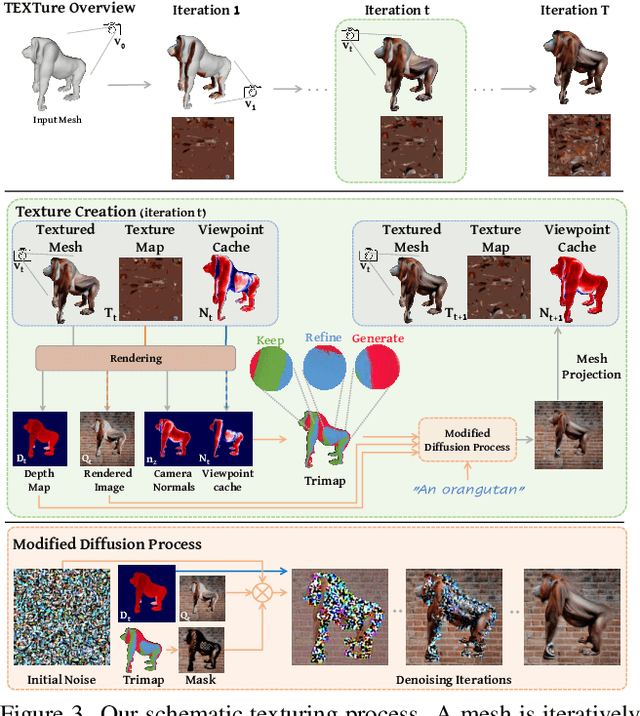
In this paper, we present TEXTure, a novel method for text-guided generation, editing, and transfer of textures for 3D shapes. Leveraging a pretrained depth-to-image diffusion model, TEXTure applies an iterative scheme that paints a 3D model from different viewpoints. Yet, while depth-to-image models can create plausible textures from a single viewpoint, the stochastic nature of the generation process can cause many inconsistencies when texturing an entire 3D object. To tackle these problems, we dynamically define a trimap partitioning of the rendered image into three progression states, and present a novel elaborated diffusion sampling process that uses this trimap representation to generate seamless textures from different views. We then show that one can transfer the generated texture maps to new 3D geometries without requiring explicit surface-to-surface mapping, as well as extract semantic textures from a set of images without requiring any explicit reconstruction. Finally, we show that TEXTure can be used to not only generate new textures but also edit and refine existing textures using either a text prompt or user-provided scribbles. We demonstrate that our TEXTuring method excels at generating, transferring, and editing textures through extensive evaluation, and further close the gap between 2D image generation and 3D texturing.
Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures
Nov 14, 2022Text-guided image generation has progressed rapidly in recent years, inspiring major breakthroughs in text-guided shape generation. Recently, it has been shown that using score distillation, one can successfully text-guide a NeRF model to generate a 3D object. We adapt the score distillation to the publicly available, and computationally efficient, Latent Diffusion Models, which apply the entire diffusion process in a compact latent space of a pretrained autoencoder. As NeRFs operate in image space, a naive solution for guiding them with latent score distillation would require encoding to the latent space at each guidance step. Instead, we propose to bring the NeRF to the latent space, resulting in a Latent-NeRF. Analyzing our Latent-NeRF, we show that while Text-to-3D models can generate impressive results, they are inherently unconstrained and may lack the ability to guide or enforce a specific 3D structure. To assist and direct the 3D generation, we propose to guide our Latent-NeRF using a Sketch-Shape: an abstract geometry that defines the coarse structure of the desired object. Then, we present means to integrate such a constraint directly into a Latent-NeRF. This unique combination of text and shape guidance allows for increased control over the generation process. We also show that latent score distillation can be successfully applied directly on 3D meshes. This allows for generating high-quality textures on a given geometry. Our experiments validate the power of our different forms of guidance and the efficiency of using latent rendering. Implementation is available at https://github.com/eladrich/latent-nerf
TetGAN: A Convolutional Neural Network for Tetrahedral Mesh Generation
Oct 11, 2022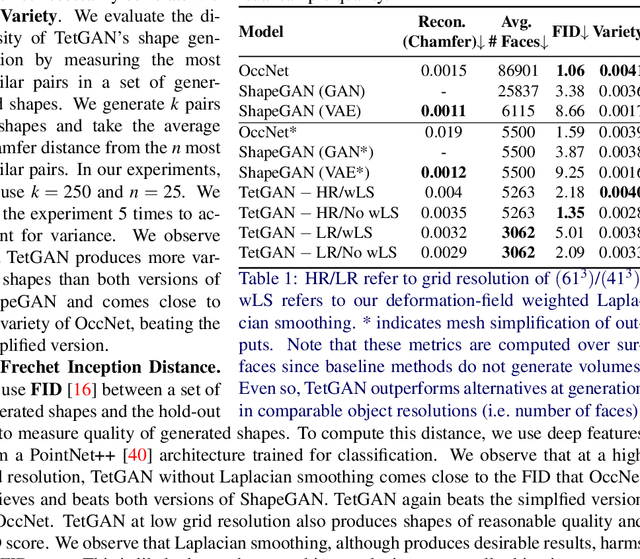

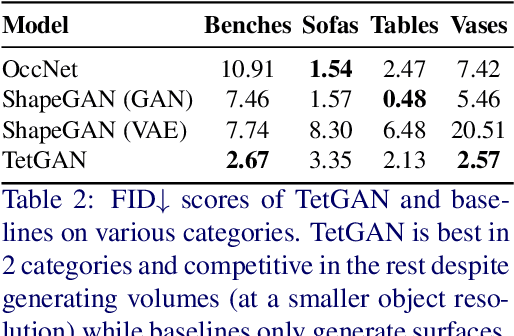

We present TetGAN, a convolutional neural network designed to generate tetrahedral meshes. We represent shapes using an irregular tetrahedral grid which encodes an occupancy and displacement field. Our formulation enables defining tetrahedral convolution, pooling, and upsampling operations to synthesize explicit mesh connectivity with variable topological genus. The proposed neural network layers learn deep features over each tetrahedron and learn to extract patterns within spatial regions across multiple scales. We illustrate the capabilities of our technique to encode tetrahedral meshes into a semantically meaningful latent-space which can be used for shape editing and synthesis. Our project page is at https://threedle.github.io/tetGAN/.
DeepMLS: Geometry-Aware Control Point Deformation
Jan 05, 2022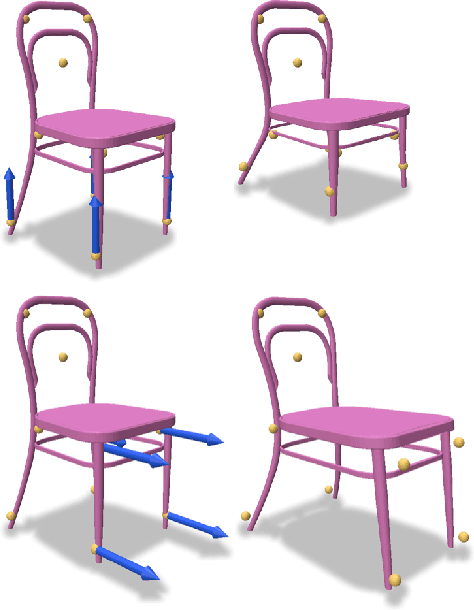
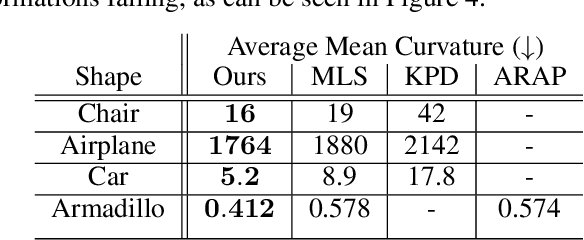
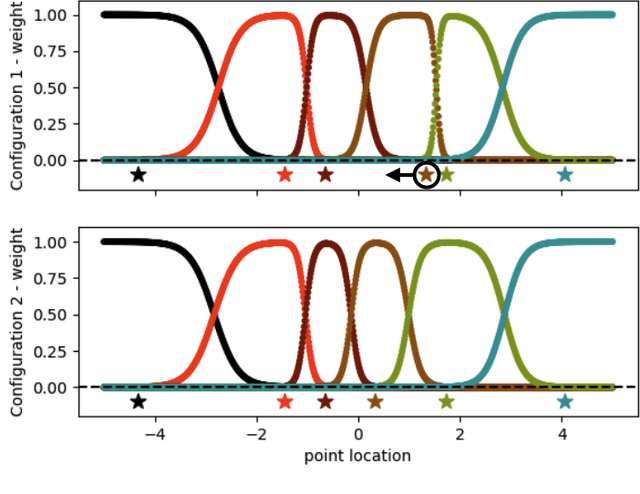

We introduce DeepMLS, a space-based deformation technique, guided by a set of displaced control points. We leverage the power of neural networks to inject the underlying shape geometry into the deformation parameters. The goal of our technique is to enable a realistic and intuitive shape deformation. Our method is built upon moving least-squares (MLS), since it minimizes a weighted sum of the given control point displacements. Traditionally, the influence of each control point on every point in space (i.e., the weighting function) is defined using inverse distance heuristics. In this work, we opt to learn the weighting function, by training a neural network on the control points from a single input shape, and exploit the innate smoothness of neural networks. Our geometry-aware control point deformation is agnostic to the surface representation and quality; it can be applied to point clouds or meshes, including non-manifold and disconnected surface soups. We show that our technique facilitates intuitive piecewise smooth deformations, which are well suited for manufactured objects. We show the advantages of our approach compared to existing surface and space-based deformation techniques, both quantitatively and qualitatively.
Z2P: Instant Rendering of Point Clouds
May 30, 2021

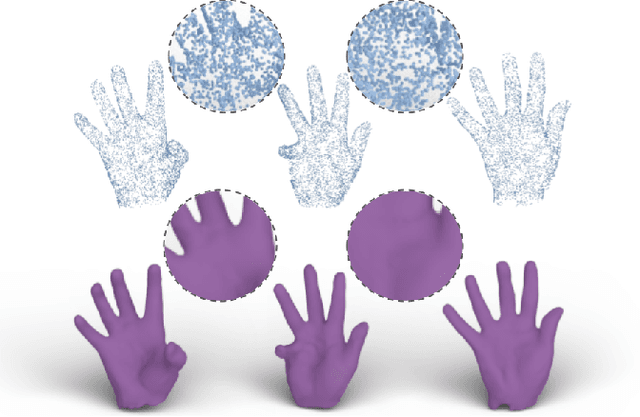
We present a technique for rendering point clouds using a neural network. Existing point rendering techniques either use splatting, or first reconstruct a surface mesh that can then be rendered. Both of these techniques require solving for global point normal orientation, which is a challenging problem on its own. Furthermore, splatting techniques result in holes and overlaps, whereas mesh reconstruction is particularly challenging, especially in the cases of thin surfaces and sheets. We cast the rendering problem as a conditional image-to-image translation problem. In our formulation, Z2P, i.e., depth-augmented point features as viewed from target camera view, are directly translated by a neural network to rendered images, conditioned on control variables (e.g., color, light). We avoid inevitable issues with splatting (i.e., holes and overlaps), and bypass solving the notoriously challenging surface reconstruction problem or estimating oriented normals. Yet, our approach results in a rendered image as if a surface mesh was reconstructed. We demonstrate that our framework produces a plausible image, and can effectively handle noise, non-uniform sampling, thin surfaces / sheets, and is fast.
Orienting Point Clouds with Dipole Propagation
May 04, 2021
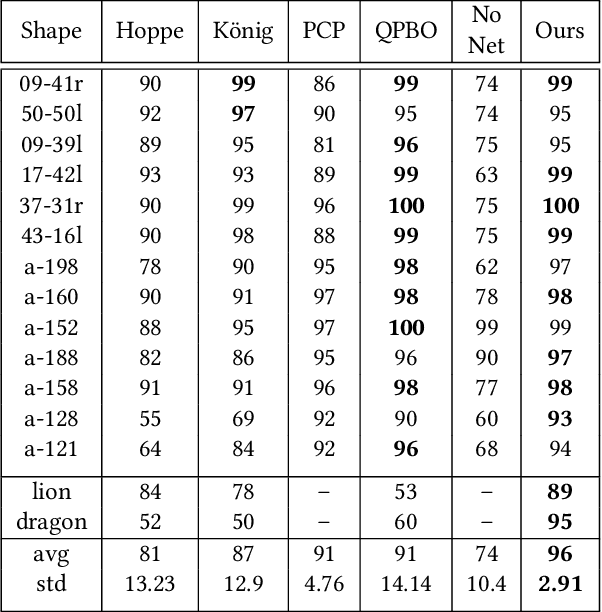
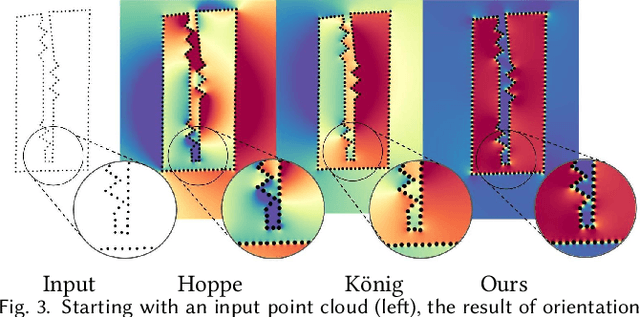
Establishing a consistent normal orientation for point clouds is a notoriously difficult problem in geometry processing, requiring attention to both local and global shape characteristics. The normal direction of a point is a function of the local surface neighborhood; yet, point clouds do not disclose the full underlying surface structure. Even assuming known geodesic proximity, calculating a consistent normal orientation requires the global context. In this work, we introduce a novel approach for establishing a globally consistent normal orientation for point clouds. Our solution separates the local and global components into two different sub-problems. In the local phase, we train a neural network to learn a coherent normal direction per patch (i.e., consistently oriented normals within a single patch). In the global phase, we propagate the orientation across all coherent patches using a dipole propagation. Our dipole propagation decides to orient each patch using the electric field defined by all previously orientated patches. This gives rise to a global propagation that is stable, as well as being robust to nearby surfaces, holes, sharp features and noise.
Self-Sampling for Neural Point Cloud Consolidation
Aug 14, 2020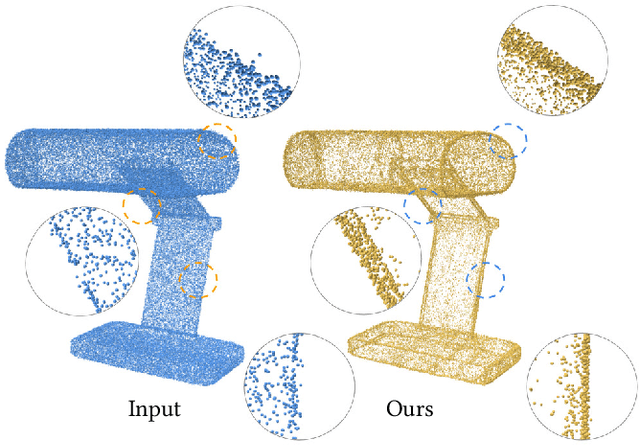
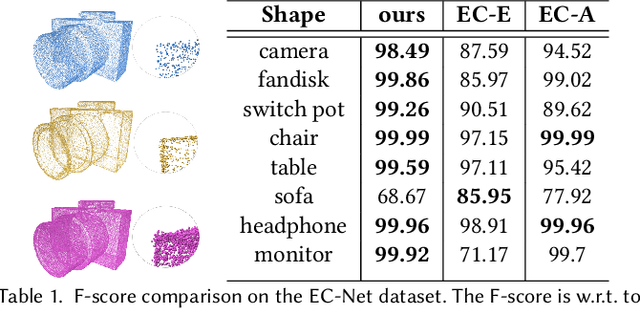
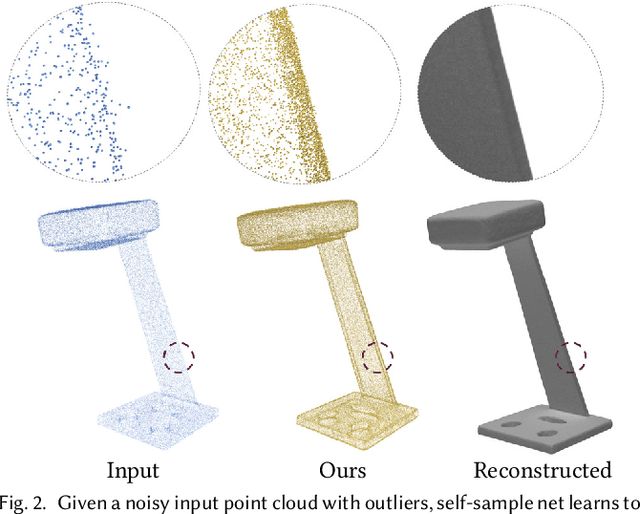
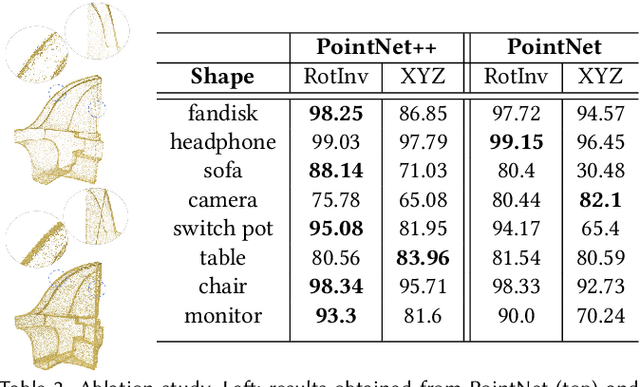
In this paper, we introduce a deep learning technique for consolidating and sharp feature generation of point clouds using only the input point cloud itself. Rather than explicitly define a prior that describes typical shape characteristics (i.e., piecewise-smoothness), or a heuristic policy for generating novel sharp points, we opt to learn both using a neural network with shared-weights. Instead of relying on a large collection of manually annotated data, we use the self-supervision present within a single shape, i.e., self-prior, to train the network, and learn the underlying distribution of sharp features specific to the given input point cloud. By learning to map a low-curvature subset of the input point cloud to a disjoint high-curvature subset, the network formalizes the shape-specific characteristics and infers how to generate sharp points. During test time, the network is repeatedly fed a random subset of points from the input and displaces them to generate an arbitrarily large set of novel sharp feature points. The local shared weights are optimized over the entire shape, learning non-local statistics and exploiting the recurrence of local-scale geometries. We demonstrate the ability to generate coherent sets of sharp feature points on a variety of shapes, while eliminating outliers and noise.