 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Junior to Senior: Allocating Agency and Navigating Professional Growth in Agentic AI-Mediated Software Engineering
Jan 31, 2026Juniors enter as AI-natives, seniors adapted mid-career. AI is not just changing how engineers code-it is reshaping who holds agency across work and professional growth. We contribute junior-senior accounts on their usage of agentic AI through a three-phase mixed-methods study: ACTA combined with a Delphi process with 5 seniors, an AI-assisted debugging task with 10 juniors, and blind reviews of junior prompt histories by 5 more seniors. We found that agency in software engineering is primarily constrained by organizational policies rather than individual preferences, with experienced developers maintaining control through detailed delegation while novices struggle between over-reliance and cautious avoidance. Seniors leverage pre-AI foundational instincts to steer modern tools and possess valuable perspectives for mentoring juniors in their early AI-encouraged career development. From synthesis of results, we suggest three practices that focus on preserving agency in software engineering for coding, learning, and mentorship, especially as AI grows increasingly autonomous.
TetGAN: A Convolutional Neural Network for Tetrahedral Mesh Generation
Oct 11, 2022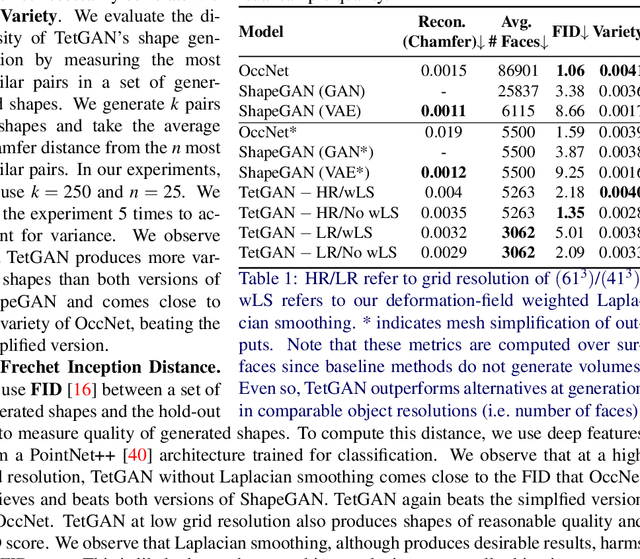

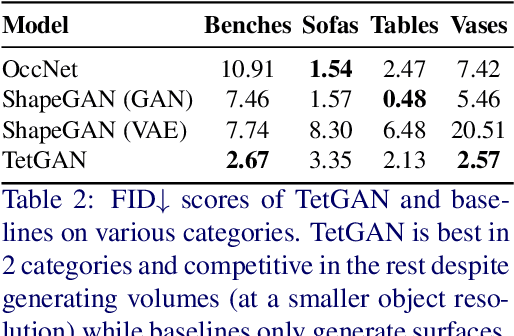

We present TetGAN, a convolutional neural network designed to generate tetrahedral meshes. We represent shapes using an irregular tetrahedral grid which encodes an occupancy and displacement field. Our formulation enables defining tetrahedral convolution, pooling, and upsampling operations to synthesize explicit mesh connectivity with variable topological genus. The proposed neural network layers learn deep features over each tetrahedron and learn to extract patterns within spatial regions across multiple scales. We illustrate the capabilities of our technique to encode tetrahedral meshes into a semantically meaningful latent-space which can be used for shape editing and synthesis. Our project page is at https://threedle.github.io/tetGAN/.
HAConvGNN: Hierarchical Attention Based Convolutional Graph Neural Network for Code Documentation Generation in Jupyter Notebooks
Mar 31, 2021

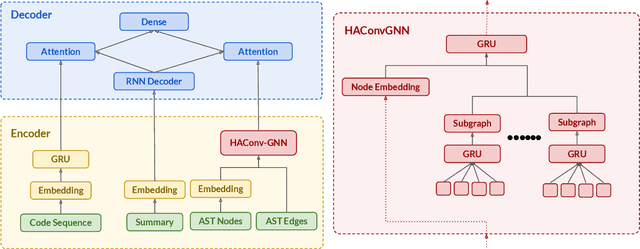
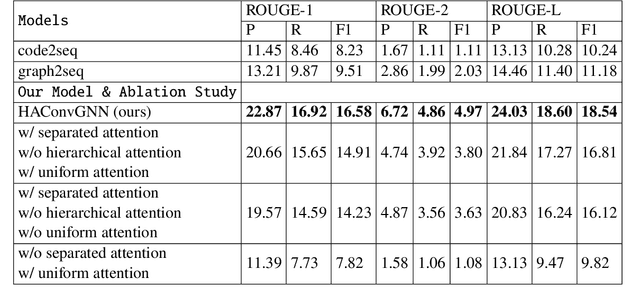
Many data scientists use Jupyter notebook to experiment code, visualize results, and document rationales or interpretations. The code documentation generation CDG task in notebooks is related but different from the code summarization task in software engineering, as one documentation (markdown cell) may consist of a text (informative summary or indicative rationale) for multiple code cells. Our work aims to solve the CDG task by encoding the multiple code cells as separated AST graph structures, for which we propose a hierarchical attention-based ConvGNN component to augment the Seq2Seq network. We build a dataset with publicly available Kaggle notebooks and evaluate our model (HAConvGNN) against baseline models (e.g., Code2Seq or Graph2Seq).
Facilitating Knowledge Sharing from Domain Experts to Data Scientists for Building NLP Models
Jan 29, 2021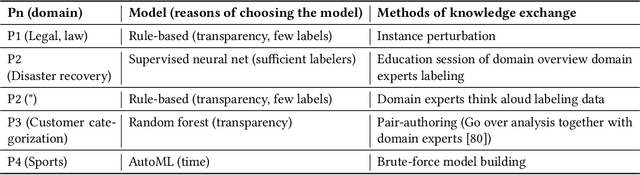

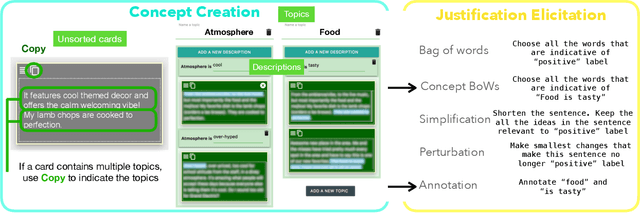
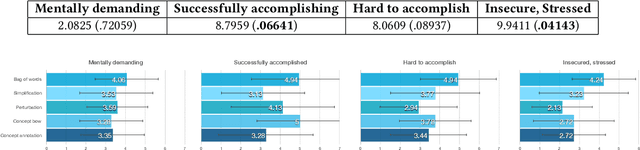
Data scientists face a steep learning curve in understanding a new domain for which they want to build machine learning (ML) models. While input from domain experts could offer valuable help, such input is often limited, expensive, and generally not in a form readily consumable by a model development pipeline. In this paper, we propose Ziva, a framework to guide domain experts in sharing essential domain knowledge to data scientists for building NLP models. With Ziva, experts are able to distill and share their domain knowledge using domain concept extractors and five types of label justification over a representative data sample. The design of Ziva is informed by preliminary interviews with data scientists, in order to understand current practices of domain knowledge acquisition process for ML development projects. To assess our design, we run a mix-method case-study to evaluate how Ziva can facilitate interaction of domain experts and data scientists. Our results highlight that (1) domain experts are able to use Ziva to provide rich domain knowledge, while maintaining low mental load and stress levels; and (2) data scientists find Ziva's output helpful for learning essential information about the domain, offering scalability of information, and lowering the burden on domain experts to share knowledge. We conclude this work by experimenting with building NLP models using the Ziva output by our case study.