 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Agentic Intelligence for Materials Science
Jan 29, 2026The convergence of artificial intelligence and materials science presents a transformative opportunity, but achieving true acceleration in discovery requires moving beyond task-isolated, fine-tuned models toward agentic systems that plan, act, and learn across the full discovery loop. This survey advances a unique pipeline-centric view that spans from corpus curation and pretraining, through domain adaptation and instruction tuning, to goal-conditioned agents interfacing with simulation and experimental platforms. Unlike prior reviews, we treat the entire process as an end-to-end system to be optimized for tangible discovery outcomes rather than proxy benchmarks. This perspective allows us to trace how upstream design choices-such as data curation and training objectives-can be aligned with downstream experimental success through effective credit assignment. To bridge communities and establish a shared frame of reference, we first present an integrated lens that aligns terminology, evaluation, and workflow stages across AI and materials science. We then analyze the field through two focused lenses: From the AI perspective, the survey details LLM strengths in pattern recognition, predictive analytics, and natural language processing for literature mining, materials characterization, and property prediction; from the materials science perspective, it highlights applications in materials design, process optimization, and the acceleration of computational workflows via integration with external tools (e.g., DFT, robotic labs). Finally, we contrast passive, reactive approaches with agentic design, cataloging current contributions while motivating systems that pursue long-horizon goals with autonomy, memory, and tool use. This survey charts a practical roadmap towards autonomous, safety-aware LLM agents aimed at discovering novel and useful materials.
Survey of Video Diffusion Models: Foundations, Implementations, and Applications
Apr 22, 2025Recent advances in diffusion models have revolutionized video generation, offering superior temporal consistency and visual quality compared to traditional generative adversarial networks-based approaches. While this emerging field shows tremendous promise in applications, it faces significant challenges in motion consistency, computational efficiency, and ethical considerations. This survey provides a comprehensive review of diffusion-based video generation, examining its evolution, technical foundations, and practical applications. We present a systematic taxonomy of current methodologies, analyze architectural innovations and optimization strategies, and investigate applications across low-level vision tasks such as denoising and super-resolution. Additionally, we explore the synergies between diffusionbased video generation and related domains, including video representation learning, question answering, and retrieval. Compared to the existing surveys (Lei et al., 2024a;b; Melnik et al., 2024; Cao et al., 2023; Xing et al., 2024c) which focus on specific aspects of video generation, such as human video synthesis (Lei et al., 2024a) or long-form content generation (Lei et al., 2024b), our work provides a broader, more updated, and more fine-grained perspective on diffusion-based approaches with a special section for evaluation metrics, industry solutions, and training engineering techniques in video generation. This survey serves as a foundational resource for researchers and practitioners working at the intersection of diffusion models and video generation, providing insights into both the theoretical frameworks and practical implementations that drive this rapidly evolving field. A structured list of related works involved in this survey is also available on https://github.com/Eyeline-Research/Survey-Video-Diffusion.
HAConvGNN: Hierarchical Attention Based Convolutional Graph Neural Network for Code Documentation Generation in Jupyter Notebooks
Mar 31, 2021

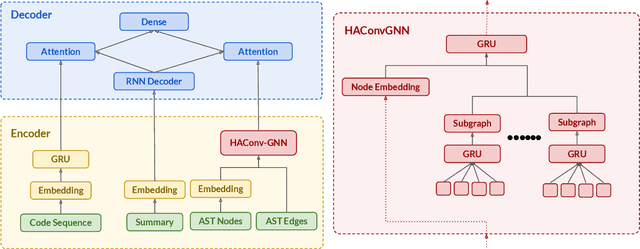
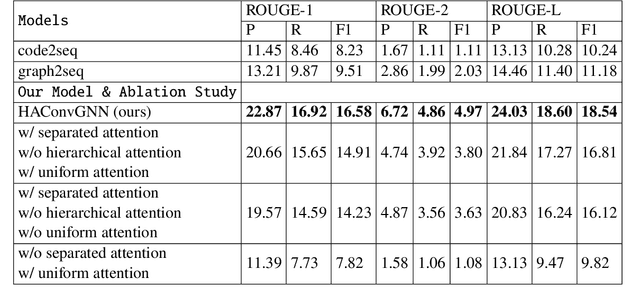
Many data scientists use Jupyter notebook to experiment code, visualize results, and document rationales or interpretations. The code documentation generation CDG task in notebooks is related but different from the code summarization task in software engineering, as one documentation (markdown cell) may consist of a text (informative summary or indicative rationale) for multiple code cells. Our work aims to solve the CDG task by encoding the multiple code cells as separated AST graph structures, for which we propose a hierarchical attention-based ConvGNN component to augment the Seq2Seq network. We build a dataset with publicly available Kaggle notebooks and evaluate our model (HAConvGNN) against baseline models (e.g., Code2Seq or Graph2Seq).