 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLighting in Motion: Spatiotemporal HDR Lighting Estimation
Dec 15, 2025We present Lighting in Motion (LiMo), a diffusion-based approach to spatiotemporal lighting estimation. LiMo targets both realistic high-frequency detail prediction and accurate illuminance estimation. To account for both, we propose generating a set of mirrored and diffuse spheres at different exposures, based on their 3D positions in the input. Making use of diffusion priors, we fine-tune powerful existing diffusion models on a large-scale customized dataset of indoor and outdoor scenes, paired with spatiotemporal light probes. For accurate spatial conditioning, we demonstrate that depth alone is insufficient and we introduce a new geometric condition to provide the relative position of the scene to the target 3D position. Finally, we combine diffuse and mirror predictions at different exposures into a single HDRI map leveraging differentiable rendering. We thoroughly evaluate our method and design choices to establish LiMo as state-of-the-art for both spatial control and prediction accuracy.
Virtually Being: Customizing Camera-Controllable Video Diffusion Models with Multi-View Performance Captures
Oct 16, 2025We introduce a framework that enables both multi-view character consistency and 3D camera control in video diffusion models through a novel customization data pipeline. We train the character consistency component with recorded volumetric capture performances re-rendered with diverse camera trajectories via 4D Gaussian Splatting (4DGS), lighting variability obtained with a video relighting model. We fine-tune state-of-the-art open-source video diffusion models on this data to provide strong multi-view identity preservation, precise camera control, and lighting adaptability. Our framework also supports core capabilities for virtual production, including multi-subject generation using two approaches: joint training and noise blending, the latter enabling efficient composition of independently customized models at inference time; it also achieves scene and real-life video customization as well as control over motion and spatial layout during customization. Extensive experiments show improved video quality, higher personalization accuracy, and enhanced camera control and lighting adaptability, advancing the integration of video generation into virtual production. Our project page is available at: https://eyeline-labs.github.io/Virtually-Being.
VChain: Chain-of-Visual-Thought for Reasoning in Video Generation
Oct 06, 2025Recent video generation models can produce smooth and visually appealing clips, but they often struggle to synthesize complex dynamics with a coherent chain of consequences. Accurately modeling visual outcomes and state transitions over time remains a core challenge. In contrast, large language and multimodal models (e.g., GPT-4o) exhibit strong visual state reasoning and future prediction capabilities. To bridge these strengths, we introduce VChain, a novel inference-time chain-of-visual-thought framework that injects visual reasoning signals from multimodal models into video generation. Specifically, VChain contains a dedicated pipeline that leverages large multimodal models to generate a sparse set of critical keyframes as snapshots, which are then used to guide the sparse inference-time tuning of a pre-trained video generator only at these key moments. Our approach is tuning-efficient, introduces minimal overhead and avoids dense supervision. Extensive experiments on complex, multi-step scenarios show that VChain significantly enhances the quality of generated videos.
MAViS: A Multi-Agent Framework for Long-Sequence Video Storytelling
Aug 11, 2025Despite recent advances, long-sequence video generation frameworks still suffer from significant limitations: poor assistive capability, suboptimal visual quality, and limited expressiveness. To mitigate these limitations, we propose MAViS, an end-to-end multi-agent collaborative framework for long-sequence video storytelling. MAViS orchestrates specialized agents across multiple stages, including script writing, shot designing, character modeling, keyframe generation, video animation, and audio generation. In each stage, agents operate under the 3E Principle -- Explore, Examine, and Enhance -- to ensure the completeness of intermediate outputs. Considering the capability limitations of current generative models, we propose the Script Writing Guidelines to optimize compatibility between scripts and generative tools. Experimental results demonstrate that MAViS achieves state-of-the-art performance in assistive capability, visual quality, and video expressiveness. Its modular framework further enables scalability with diverse generative models and tools. With just a brief user prompt, MAViS is capable of producing high-quality, expressive long-sequence video storytelling, enriching inspirations and creativity for users. To the best of our knowledge, MAViS is the only framework that provides multimodal design output -- videos with narratives and background music.
Survey of Video Diffusion Models: Foundations, Implementations, and Applications
Apr 22, 2025Recent advances in diffusion models have revolutionized video generation, offering superior temporal consistency and visual quality compared to traditional generative adversarial networks-based approaches. While this emerging field shows tremendous promise in applications, it faces significant challenges in motion consistency, computational efficiency, and ethical considerations. This survey provides a comprehensive review of diffusion-based video generation, examining its evolution, technical foundations, and practical applications. We present a systematic taxonomy of current methodologies, analyze architectural innovations and optimization strategies, and investigate applications across low-level vision tasks such as denoising and super-resolution. Additionally, we explore the synergies between diffusionbased video generation and related domains, including video representation learning, question answering, and retrieval. Compared to the existing surveys (Lei et al., 2024a;b; Melnik et al., 2024; Cao et al., 2023; Xing et al., 2024c) which focus on specific aspects of video generation, such as human video synthesis (Lei et al., 2024a) or long-form content generation (Lei et al., 2024b), our work provides a broader, more updated, and more fine-grained perspective on diffusion-based approaches with a special section for evaluation metrics, industry solutions, and training engineering techniques in video generation. This survey serves as a foundational resource for researchers and practitioners working at the intersection of diffusion models and video generation, providing insights into both the theoretical frameworks and practical implementations that drive this rapidly evolving field. A structured list of related works involved in this survey is also available on https://github.com/Eyeline-Research/Survey-Video-Diffusion.
FlashDepth: Real-time Streaming Video Depth Estimation at 2K Resolution
Apr 09, 2025A versatile video depth estimation model should (1) be accurate and consistent across frames, (2) produce high-resolution depth maps, and (3) support real-time streaming. We propose FlashDepth, a method that satisfies all three requirements, performing depth estimation on a 2044x1148 streaming video at 24 FPS. We show that, with careful modifications to pretrained single-image depth models, these capabilities are enabled with relatively little data and training. We evaluate our approach across multiple unseen datasets against state-of-the-art depth models, and find that ours outperforms them in terms of boundary sharpness and speed by a significant margin, while maintaining competitive accuracy. We hope our model will enable various applications that require high-resolution depth, such as video editing, and online decision-making, such as robotics.
Lux Post Facto: Learning Portrait Performance Relighting with Conditional Video Diffusion and a Hybrid Dataset
Mar 18, 2025Video portrait relighting remains challenging because the results need to be both photorealistic and temporally stable. This typically requires a strong model design that can capture complex facial reflections as well as intensive training on a high-quality paired video dataset, such as dynamic one-light-at-a-time (OLAT). In this work, we introduce Lux Post Facto, a novel portrait video relighting method that produces both photorealistic and temporally consistent lighting effects. From the model side, we design a new conditional video diffusion model built upon state-of-the-art pre-trained video diffusion model, alongside a new lighting injection mechanism to enable precise control. This way we leverage strong spatial and temporal generative capability to generate plausible solutions to the ill-posed relighting problem. Our technique uses a hybrid dataset consisting of static expression OLAT data and in-the-wild portrait performance videos to jointly learn relighting and temporal modeling. This avoids the need to acquire paired video data in different lighting conditions. Our extensive experiments show that our model produces state-of-the-art results both in terms of photorealism and temporal consistency.
Self-Calibrating Gaussian Splatting for Large Field of View Reconstruction
Feb 13, 2025
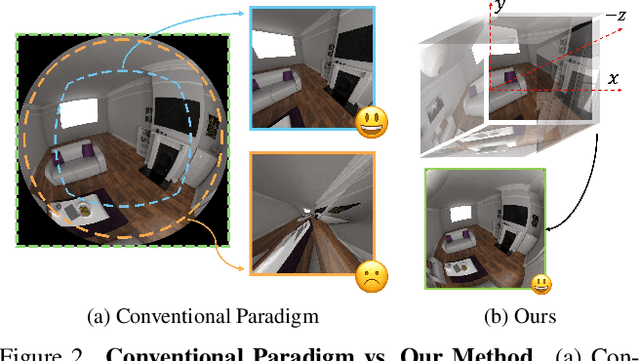
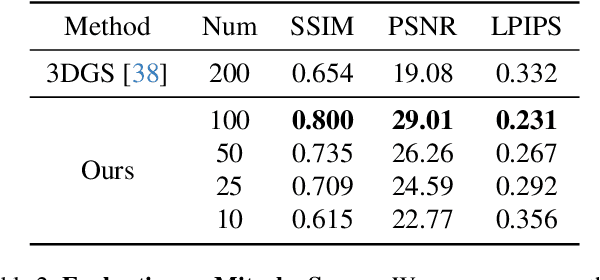
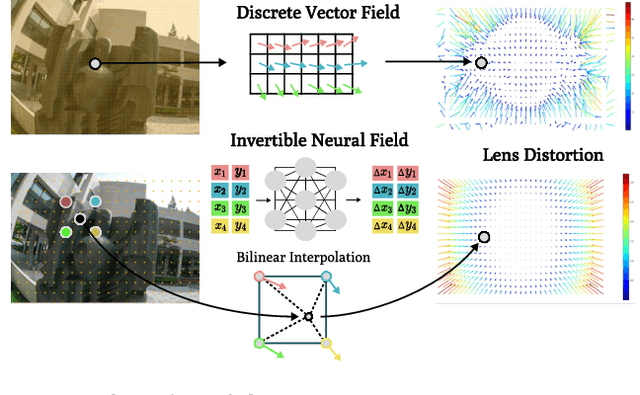
In this paper, we present a self-calibrating framework that jointly optimizes camera parameters, lens distortion and 3D Gaussian representations, enabling accurate and efficient scene reconstruction. In particular, our technique enables high-quality scene reconstruction from Large field-of-view (FOV) imagery taken with wide-angle lenses, allowing the scene to be modeled from a smaller number of images. Our approach introduces a novel method for modeling complex lens distortions using a hybrid network that combines invertible residual networks with explicit grids. This design effectively regularizes the optimization process, achieving greater accuracy than conventional camera models. Additionally, we propose a cubemap-based resampling strategy to support large FOV images without sacrificing resolution or introducing distortion artifacts. Our method is compatible with the fast rasterization of Gaussian Splatting, adaptable to a wide variety of camera lens distortion, and demonstrates state-of-the-art performance on both synthetic and real-world datasets.
Go-with-the-Flow: Motion-Controllable Video Diffusion Models Using Real-Time Warped Noise
Jan 16, 2025



Generative modeling aims to transform random noise into structured outputs. In this work, we enhance video diffusion models by allowing motion control via structured latent noise sampling. This is achieved by just a change in data: we pre-process training videos to yield structured noise. Consequently, our method is agnostic to diffusion model design, requiring no changes to model architectures or training pipelines. Specifically, we propose a novel noise warping algorithm, fast enough to run in real time, that replaces random temporal Gaussianity with correlated warped noise derived from optical flow fields, while preserving the spatial Gaussianity. The efficiency of our algorithm enables us to fine-tune modern video diffusion base models using warped noise with minimal overhead, and provide a one-stop solution for a wide range of user-friendly motion control: local object motion control, global camera movement control, and motion transfer. The harmonization between temporal coherence and spatial Gaussianity in our warped noise leads to effective motion control while maintaining per-frame pixel quality. Extensive experiments and user studies demonstrate the advantages of our method, making it a robust and scalable approach for controlling motion in video diffusion models. Video results are available on our webpage: https://vgenai-netflix-eyeline-research.github.io/Go-with-the-Flow. Source code and model checkpoints are available on GitHub: https://github.com/VGenAI-Netflix-Eyeline-Research/Go-with-the-Flow.
Fitting Spherical Gaussians to Dynamic HDRI Sequences
Dec 09, 2024We present a technique for fitting high dynamic range illumination (HDRI) sequences using anisotropic spherical Gaussians (ASGs) while preserving temporal consistency in the compressed HDRI maps. Our approach begins with an optimization network that iteratively minimizes a composite loss function, which includes both reconstruction and diffuse losses. This allows us to represent all-frequency signals with a small number of ASGs, optimizing their directions, sharpness, and intensity simultaneously for an individual HDRI. To extend this optimization into the temporal domain, we introduce a temporal consistency loss, ensuring a consistent approximation across the entire HDRI sequence.