 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Attention: From Pairwise Affinities to Functional Correspondences
May 29, 2026Learning mappings between infinite-dimensional function spaces, or operator learning, is essential for many machine learning applications. Although transformer-based operators are popular, they often rely on token-wise attention. These methods treat continuous fields as discrete tokens and usually ignore the global functional structure. We introduce \emph{Functional Attention}, which reinterprets attention as a functional correspondence between adaptive bases. Inspired by geometric functional maps, our method replaces softmax affinities with structured linear operators. This yields a compact, generalizable, resolution-invariant representation that explicitly captures global dependencies. Experiments demonstrate that \emph{Functional Attention} can match state-of-the-art performance in many operator learning tasks, including solving PDEs, 3D segmentation, and regression, while remaining robust to varying discretizations. Project page is available at https://github.com/xjffff/FUNCATTN.
Towards Vision-Language-Garment Models For Web Knowledge Garment Understanding and Generation
Jun 05, 2025

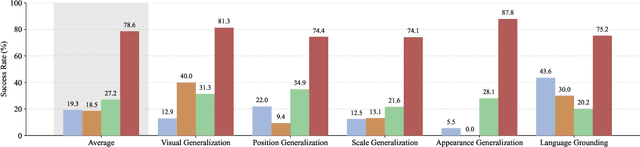

Multimodal foundation models have demonstrated strong generalization, yet their ability to transfer knowledge to specialized domains such as garment generation remains underexplored. We introduce VLG, a vision-language-garment model that synthesizes garments from textual descriptions and visual imagery. Our experiments assess VLG's zero-shot generalization, investigating its ability to transfer web-scale reasoning to unseen garment styles and prompts. Preliminary results indicate promising transfer capabilities, highlighting the potential for multimodal foundation models to adapt effectively to specialized domains like fashion design.
Animal Pose Labeling Using General-Purpose Point Trackers
Jun 04, 2025Automatically estimating animal poses from videos is important for studying animal behaviors. Existing methods do not perform reliably since they are trained on datasets that are not comprehensive enough to capture all necessary animal behaviors. However, it is very challenging to collect such datasets due to the large variations in animal morphology. In this paper, we propose an animal pose labeling pipeline that follows a different strategy, i.e. test time optimization. Given a video, we fine-tune a lightweight appearance embedding inside a pre-trained general-purpose point tracker on a sparse set of annotated frames. These annotations can be obtained from human labelers or off-the-shelf pose detectors. The fine-tuned model is then applied to the rest of the frames for automatic labeling. Our method achieves state-of-the-art performance at a reasonable annotation cost. We believe our pipeline offers a valuable tool for the automatic quantification of animal behavior. Visit our project webpage at https://zhuoyang-pan.github.io/animal-labeling.
FlashDepth: Real-time Streaming Video Depth Estimation at 2K Resolution
Apr 09, 2025A versatile video depth estimation model should (1) be accurate and consistent across frames, (2) produce high-resolution depth maps, and (3) support real-time streaming. We propose FlashDepth, a method that satisfies all three requirements, performing depth estimation on a 2044x1148 streaming video at 24 FPS. We show that, with careful modifications to pretrained single-image depth models, these capabilities are enabled with relatively little data and training. We evaluate our approach across multiple unseen datasets against state-of-the-art depth models, and find that ours outperforms them in terms of boundary sharpness and speed by a significant margin, while maintaining competitive accuracy. We hope our model will enable various applications that require high-resolution depth, such as video editing, and online decision-making, such as robotics.
BlenderGym: Benchmarking Foundational Model Systems for Graphics Editing
Apr 02, 2025



3D graphics editing is crucial in applications like movie production and game design, yet it remains a time-consuming process that demands highly specialized domain expertise. Automating this process is challenging because graphical editing requires performing a variety of tasks, each requiring distinct skill sets. Recently, vision-language models (VLMs) have emerged as a powerful framework for automating the editing process, but their development and evaluation are bottlenecked by the lack of a comprehensive benchmark that requires human-level perception and presents real-world editing complexity. In this work, we present BlenderGym, the first comprehensive VLM system benchmark for 3D graphics editing. BlenderGym evaluates VLM systems through code-based 3D reconstruction tasks. We evaluate closed- and open-source VLM systems and observe that even the state-of-the-art VLM system struggles with tasks relatively easy for human Blender users. Enabled by BlenderGym, we study how inference scaling techniques impact VLM's performance on graphics editing tasks. Notably, our findings reveal that the verifier used to guide the scaling of generation can itself be improved through inference scaling, complementing recent insights on inference scaling of LLM generation in coding and math tasks. We further show that inference compute is not uniformly effective and can be optimized by strategically distributing it between generation and verification.
Self-Calibrating Gaussian Splatting for Large Field of View Reconstruction
Feb 13, 2025
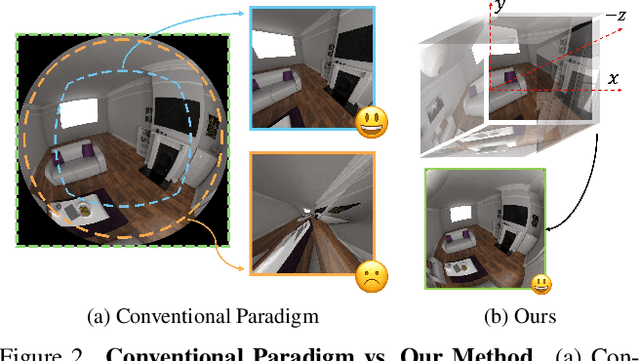
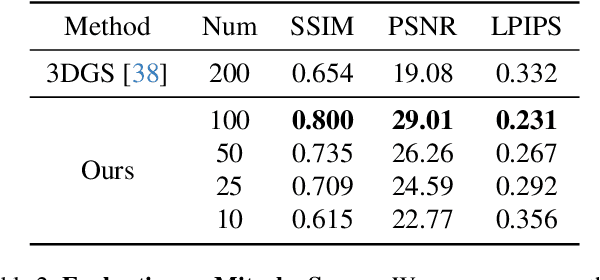
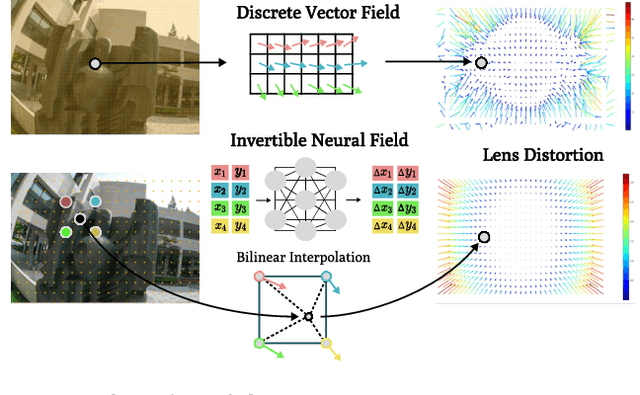
In this paper, we present a self-calibrating framework that jointly optimizes camera parameters, lens distortion and 3D Gaussian representations, enabling accurate and efficient scene reconstruction. In particular, our technique enables high-quality scene reconstruction from Large field-of-view (FOV) imagery taken with wide-angle lenses, allowing the scene to be modeled from a smaller number of images. Our approach introduces a novel method for modeling complex lens distortions using a hybrid network that combines invertible residual networks with explicit grids. This design effectively regularizes the optimization process, achieving greater accuracy than conventional camera models. Additionally, we propose a cubemap-based resampling strategy to support large FOV images without sacrificing resolution or introducing distortion artifacts. Our method is compatible with the fast rasterization of Gaussian Splatting, adaptable to a wide variety of camera lens distortion, and demonstrates state-of-the-art performance on both synthetic and real-world datasets.
FiVA: Fine-grained Visual Attribute Dataset for Text-to-Image Diffusion Models
Dec 10, 2024



Recent advances in text-to-image generation have enabled the creation of high-quality images with diverse applications. However, accurately describing desired visual attributes can be challenging, especially for non-experts in art and photography. An intuitive solution involves adopting favorable attributes from the source images. Current methods attempt to distill identity and style from source images. However, "style" is a broad concept that includes texture, color, and artistic elements, but does not cover other important attributes such as lighting and dynamics. Additionally, a simplified "style" adaptation prevents combining multiple attributes from different sources into one generated image. In this work, we formulate a more effective approach to decompose the aesthetics of a picture into specific visual attributes, allowing users to apply characteristics such as lighting, texture, and dynamics from different images. To achieve this goal, we constructed the first fine-grained visual attributes dataset (FiVA) to the best of our knowledge. This FiVA dataset features a well-organized taxonomy for visual attributes and includes around 1 M high-quality generated images with visual attribute annotations. Leveraging this dataset, we propose a fine-grained visual attribute adaptation framework (FiVA-Adapter), which decouples and adapts visual attributes from one or more source images into a generated one. This approach enhances user-friendly customization, allowing users to selectively apply desired attributes to create images that meet their unique preferences and specific content requirements.
AIpparel: A Large Multimodal Generative Model for Digital Garments
Dec 05, 2024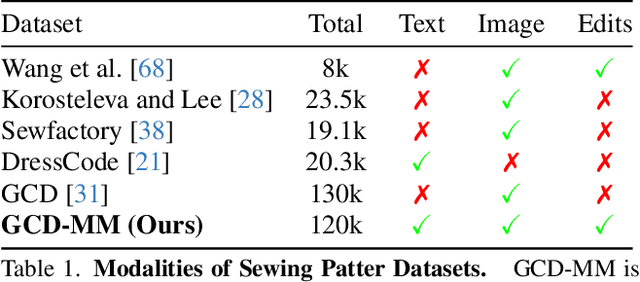
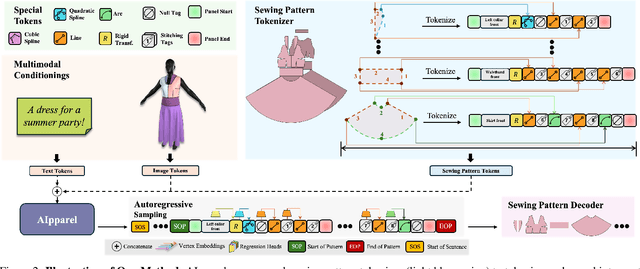

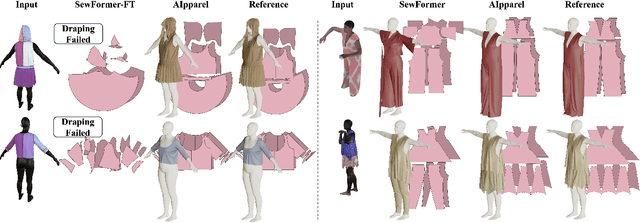
Apparel is essential to human life, offering protection, mirroring cultural identities, and showcasing personal style. Yet, the creation of garments remains a time-consuming process, largely due to the manual work involved in designing them. To simplify this process, we introduce AIpparel, a large multimodal model for generating and editing sewing patterns. Our model fine-tunes state-of-the-art large multimodal models (LMMs) on a custom-curated large-scale dataset of over 120,000 unique garments, each with multimodal annotations including text, images, and sewing patterns. Additionally, we propose a novel tokenization scheme that concisely encodes these complex sewing patterns so that LLMs can learn to predict them efficiently. \methodname achieves state-of-the-art performance in single-modal tasks, including text-to-garment and image-to-garment prediction, and enables novel multimodal garment generation applications such as interactive garment editing. The project website is at georgenakayama.github.io/AIpparel/.
DiffusionPDE: Generative PDE-Solving Under Partial Observation
Jun 25, 2024
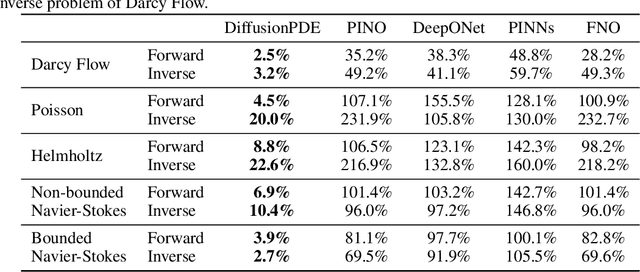
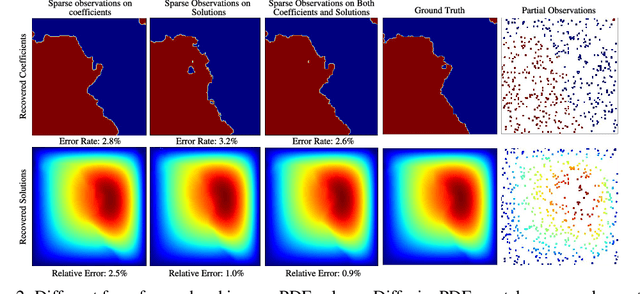

We introduce a general framework for solving partial differential equations (PDEs) using generative diffusion models. In particular, we focus on the scenarios where we do not have the full knowledge of the scene necessary to apply classical solvers. Most existing forward or inverse PDE approaches perform poorly when the observations on the data or the underlying coefficients are incomplete, which is a common assumption for real-world measurements. In this work, we propose DiffusionPDE that can simultaneously fill in the missing information and solve a PDE by modeling the joint distribution of the solution and coefficient spaces. We show that the learned generative priors lead to a versatile framework for accurately solving a wide range of PDEs under partial observation, significantly outperforming the state-of-the-art methods for both forward and inverse directions.
MegaScenes: Scene-Level View Synthesis at Scale
Jun 17, 2024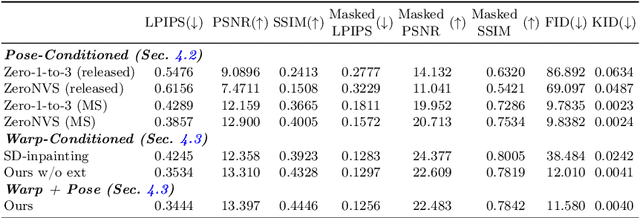
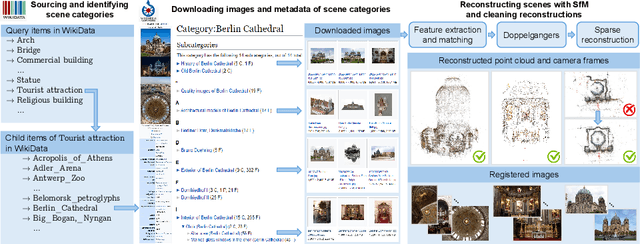
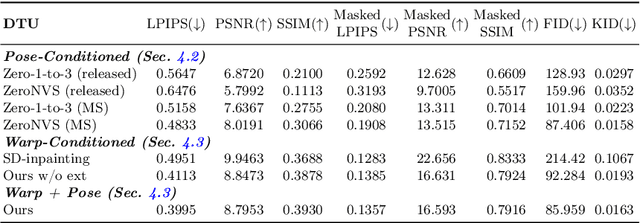
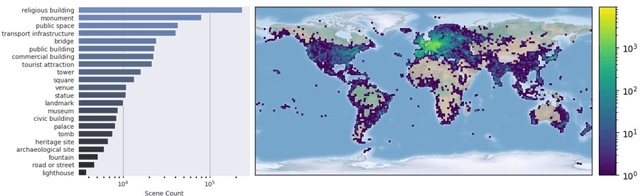
Scene-level novel view synthesis (NVS) is fundamental to many vision and graphics applications. Recently, pose-conditioned diffusion models have led to significant progress by extracting 3D information from 2D foundation models, but these methods are limited by the lack of scene-level training data. Common dataset choices either consist of isolated objects (Objaverse), or of object-centric scenes with limited pose distributions (DTU, CO3D). In this paper, we create a large-scale scene-level dataset from Internet photo collections, called MegaScenes, which contains over 100K structure from motion (SfM) reconstructions from around the world. Internet photos represent a scalable data source but come with challenges such as lighting and transient objects. We address these issues to further create a subset suitable for the task of NVS. Additionally, we analyze failure cases of state-of-the-art NVS methods and significantly improve generation consistency. Through extensive experiments, we validate the effectiveness of both our dataset and method on generating in-the-wild scenes. For details on the dataset and code, see our project page at https://megascenes.github.io .