 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlenderGym: Benchmarking Foundational Model Systems for Graphics Editing
Apr 02, 2025



3D graphics editing is crucial in applications like movie production and game design, yet it remains a time-consuming process that demands highly specialized domain expertise. Automating this process is challenging because graphical editing requires performing a variety of tasks, each requiring distinct skill sets. Recently, vision-language models (VLMs) have emerged as a powerful framework for automating the editing process, but their development and evaluation are bottlenecked by the lack of a comprehensive benchmark that requires human-level perception and presents real-world editing complexity. In this work, we present BlenderGym, the first comprehensive VLM system benchmark for 3D graphics editing. BlenderGym evaluates VLM systems through code-based 3D reconstruction tasks. We evaluate closed- and open-source VLM systems and observe that even the state-of-the-art VLM system struggles with tasks relatively easy for human Blender users. Enabled by BlenderGym, we study how inference scaling techniques impact VLM's performance on graphics editing tasks. Notably, our findings reveal that the verifier used to guide the scaling of generation can itself be improved through inference scaling, complementing recent insights on inference scaling of LLM generation in coding and math tasks. We further show that inference compute is not uniformly effective and can be optimized by strategically distributing it between generation and verification.
FirePlace: Geometric Refinements of LLM Common Sense Reasoning for 3D Object Placement
Mar 06, 2025Scene generation with 3D assets presents a complex challenge, requiring both high-level semantic understanding and low-level geometric reasoning. While Multimodal Large Language Models (MLLMs) excel at semantic tasks, their application to 3D scene generation is hindered by their limited grounding on 3D geometry. In this paper, we investigate how to best work with MLLMs in an object placement task. Towards this goal, we introduce a novel framework, FirePlace, that applies existing MLLMs in (1) 3D geometric reasoning and the extraction of relevant geometric details from the 3D scene, (2) constructing and solving geometric constraints on the extracted low-level geometry, and (3) pruning for final placements that conform to common sense. By combining geometric reasoning with real-world understanding of MLLMs, our method can propose object placements that satisfy both geometric constraints as well as high-level semantic common-sense considerations. Our experiments show that these capabilities allow our method to place objects more effectively in complex scenes with intricate geometry, surpassing the quality of prior work.
BlenderAlchemy: Editing 3D Graphics with Vision-Language Models
Apr 26, 2024



Graphics design is important for various applications, including movie production and game design. To create a high-quality scene, designers usually need to spend hours in software like Blender, in which they might need to interleave and repeat operations, such as connecting material nodes, hundreds of times. Moreover, slightly different design goals may require completely different sequences, making automation difficult. In this paper, we propose a system that leverages Vision-Language Models (VLMs), like GPT-4V, to intelligently search the design action space to arrive at an answer that can satisfy a user's intent. Specifically, we design a vision-based edit generator and state evaluator to work together to find the correct sequence of actions to achieve the goal. Inspired by the role of visual imagination in the human design process, we supplement the visual reasoning capabilities of VLMs with "imagined" reference images from image-generation models, providing visual grounding of abstract language descriptions. In this paper, we provide empirical evidence suggesting our system can produce simple but tedious Blender editing sequences for tasks such as editing procedural materials from text and/or reference images, as well as adjusting lighting configurations for product renderings in complex scenes.
CAD: Photorealistic 3D Generation via Adversarial Distillation
Dec 11, 2023



The increased demand for 3D data in AR/VR, robotics and gaming applications, gave rise to powerful generative pipelines capable of synthesizing high-quality 3D objects. Most of these models rely on the Score Distillation Sampling (SDS) algorithm to optimize a 3D representation such that the rendered image maintains a high likelihood as evaluated by a pre-trained diffusion model. However, finding a correct mode in the high-dimensional distribution produced by the diffusion model is challenging and often leads to issues such as over-saturation, over-smoothing, and Janus-like artifacts. In this paper, we propose a novel learning paradigm for 3D synthesis that utilizes pre-trained diffusion models. Instead of focusing on mode-seeking, our method directly models the distribution discrepancy between multi-view renderings and diffusion priors in an adversarial manner, which unlocks the generation of high-fidelity and photorealistic 3D content, conditioned on a single image and prompt. Moreover, by harnessing the latent space of GANs and expressive diffusion model priors, our method facilitates a wide variety of 3D applications including single-view reconstruction, high diversity generation and continuous 3D interpolation in the open domain. The experiments demonstrate the superiority of our pipeline compared to previous works in terms of generation quality and diversity.
Aladdin: Zero-Shot Hallucination of Stylized 3D Assets from Abstract Scene Descriptions
Jun 09, 2023
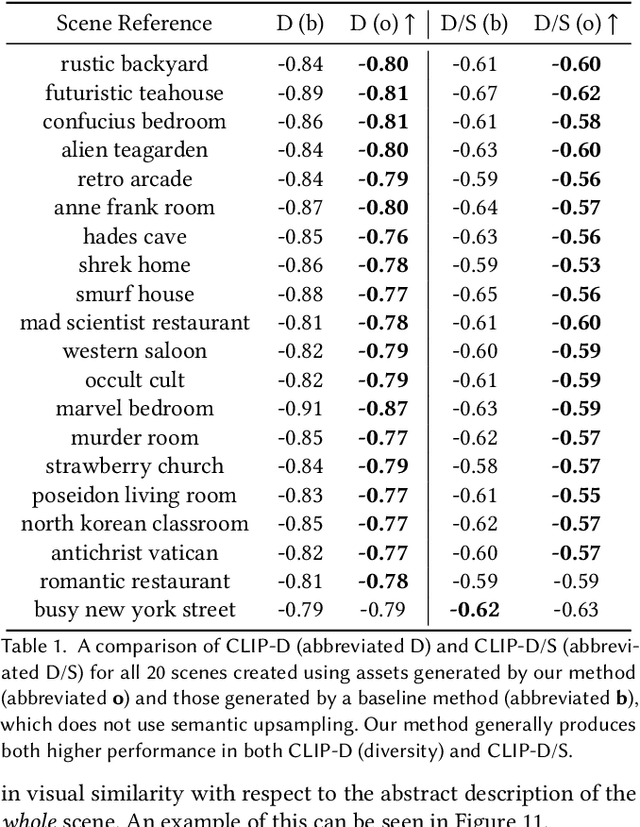
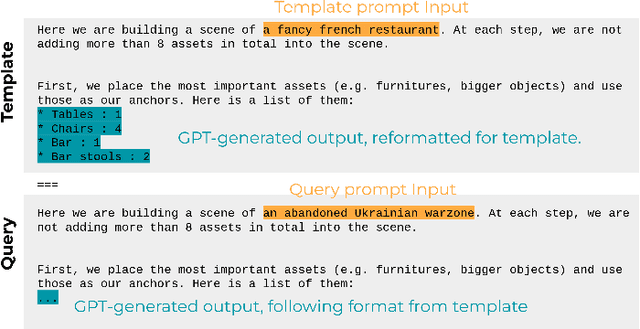
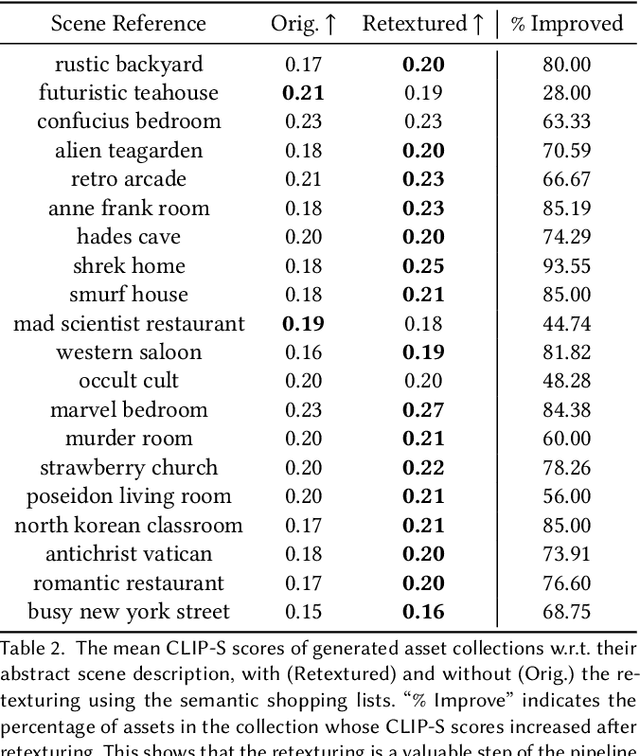
What constitutes the "vibe" of a particular scene? What should one find in "a busy, dirty city street", "an idyllic countryside", or "a crime scene in an abandoned living room"? The translation from abstract scene descriptions to stylized scene elements cannot be done with any generality by extant systems trained on rigid and limited indoor datasets. In this paper, we propose to leverage the knowledge captured by foundation models to accomplish this translation. We present a system that can serve as a tool to generate stylized assets for 3D scenes described by a short phrase, without the need to enumerate the objects to be found within the scene or give instructions on their appearance. Additionally, it is robust to open-world concepts in a way that traditional methods trained on limited data are not, affording more creative freedom to the 3D artist. Our system demonstrates this using a foundation model "team" composed of a large language model, a vision-language model and several image diffusion models, which communicate using an interpretable and user-editable intermediate representation, thus allowing for more versatile and controllable stylized asset generation for 3D artists. We introduce novel metrics for this task, and show through human evaluations that in 91% of the cases, our system outputs are judged more faithful to the semantics of the input scene description than the baseline, thus highlighting the potential of this approach to radically accelerate the 3D content creation process for 3D artists.
LADIS: Language Disentanglement for 3D Shape Editing
Dec 09, 2022
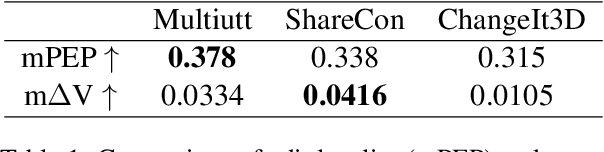
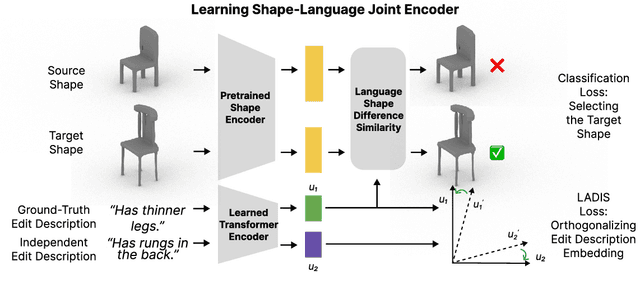
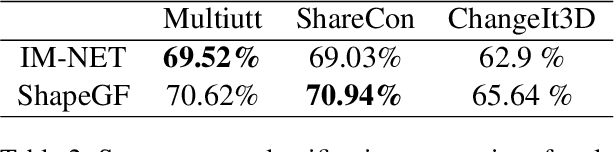
Natural language interaction is a promising direction for democratizing 3D shape design. However, existing methods for text-driven 3D shape editing face challenges in producing decoupled, local edits to 3D shapes. We address this problem by learning disentangled latent representations that ground language in 3D geometry. To this end, we propose a complementary tool set including a novel network architecture, a disentanglement loss, and a new editing procedure. Additionally, to measure edit locality, we define a new metric that we call part-wise edit precision. We show that our method outperforms existing SOTA methods by 20% in terms of edit locality, and up to 6.6% in terms of language reference resolution accuracy. Our work suggests that by solely disentangling language representations, downstream 3D shape editing can become more local to relevant parts, even if the model was never given explicit part-based supervision.
PartGlot: Learning Shape Part Segmentation from Language Reference Games
Dec 13, 2021
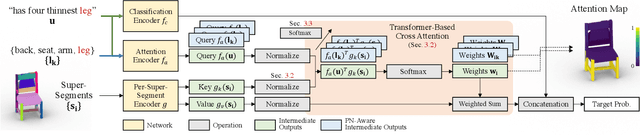


We introduce PartGlot, a neural framework and associated architectures for learning semantic part segmentation of 3D shape geometry, based solely on part referential language. We exploit the fact that linguistic descriptions of a shape can provide priors on the shape's parts -- as natural language has evolved to reflect human perception of the compositional structure of objects, essential to their recognition and use. For training, we use the paired geometry / language data collected in the ShapeGlot work for their reference game, where a speaker creates an utterance to differentiate a target shape from two distractors and the listener has to find the target based on this utterance. Our network is designed to solve this target discrimination problem, carefully incorporating a Transformer-based attention module so that the output attention can precisely highlight the semantic part or parts described in the language. Furthermore, the network operates without any direct supervision on the 3D geometry itself. Surprisingly, we further demonstrate that the learned part information is generalizable to shape classes unseen during training. Our approach opens the possibility of learning 3D shape parts from language alone, without the need for large-scale part geometry annotations, thus facilitating annotation acquisition.