 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBézierFlow: Learning Bézier Stochastic Interpolant Schedulers for Few-Step Generation
Dec 28, 2025We introduce BézierFlow, a lightweight training approach for few-step generation with pretrained diffusion and flow models. BézierFlow achieves a 2-3x performance improvement for sampling with $\leq$ 10 NFEs while requiring only 15 minutes of training. Recent lightweight training approaches have shown promise by learning optimal timesteps, but their scope remains restricted to ODE discretizations. To broaden this scope, we propose learning the optimal transformation of the sampling trajectory by parameterizing stochastic interpolant (SI) schedulers. The main challenge lies in designing a parameterization that satisfies critical desiderata, including boundary conditions, differentiability, and monotonicity of the SNR. To effectively meet these requirements, we represent scheduler functions as Bézier functions, where control points naturally enforce these properties. This reduces the problem to learning an ordered set of points in the time range, while the interpretation of the points changes from ODE timesteps to Bézier control points. Across a range of pretrained diffusion and flow models, BézierFlow consistently outperforms prior timestep-learning methods, demonstrating the effectiveness of expanding the search space from discrete timesteps to Bézier-based trajectory transformations.
BézierFlow: Bézier Stochastic Interpolant Schedulers for Few-Step Generation
Dec 15, 2025We introduce BézierFlow, a lightweight training approach for few-step generation with pretrained diffusion and flow models. BézierFlow achieves a 2-3x performance improvement for sampling with $\leq$ 10 NFEs while requiring only 15 minutes of training. Recent lightweight training approaches have shown promise by learning optimal timesteps, but their scope remains restricted to ODE discretizations. To broaden this scope, we propose learning the optimal transformation of the sampling trajectory by parameterizing stochastic interpolant (SI) schedulers. The main challenge lies in designing a parameterization that satisfies critical desiderata, including boundary conditions, differentiability, and monotonicity of the SNR. To effectively meet these requirements, we represent scheduler functions as Bézier functions, where control points naturally enforce these properties. This reduces the problem to learning an ordered set of points in the time range, while the interpretation of the points changes from ODE timesteps to Bézier control points. Across a range of pretrained diffusion and flow models, BézierFlow consistently outperforms prior timestep-learning methods, demonstrating the effectiveness of expanding the search space from discrete timesteps to Bézier-based trajectory transformations.
Toward Ambulatory Vision: Learning Visually-Grounded Active View Selection
Dec 15, 2025Vision Language Models (VLMs) excel at visual question answering (VQA) but remain limited to snapshot vision, reasoning from static images. In contrast, embodied agents require ambulatory vision, actively moving to obtain more informative views. We introduce Visually Grounded Active View Selection (VG-AVS), a task that selects the most informative next viewpoint using only the visual information in the current image, without relying on scene memory or external knowledge. To support this task, we construct a synthetic dataset with automatically generated paired query-target views and question-answer prompts. We also propose a framework that fine-tunes pretrained VLMs through supervised fine-tuning (SFT) followed by RL-based policy optimization. Our approach achieves strong question answering performance based on viewpoint selection and generalizes robustly to unseen synthetic and real scenes. Furthermore, incorporating our learned VG-AVS framework into existing scene-exploration-based EQA systems improves downstream question-answering accuracy.
VideoHandles: Editing 3D Object Compositions in Videos Using Video Generative Priors
Mar 03, 2025Generative methods for image and video editing use generative models as priors to perform edits despite incomplete information, such as changing the composition of 3D objects shown in a single image. Recent methods have shown promising composition editing results in the image setting, but in the video setting, editing methods have focused on editing object's appearance and motion, or camera motion, and as a result, methods to edit object composition in videos are still missing. We propose \name as a method for editing 3D object compositions in videos of static scenes with camera motion. Our approach allows editing the 3D position of a 3D object across all frames of a video in a temporally consistent manner. This is achieved by lifting intermediate features of a generative model to a 3D reconstruction that is shared between all frames, editing the reconstruction, and projecting the features on the edited reconstruction back to each frame. To the best of our knowledge, this is the first generative approach to edit object compositions in videos. Our approach is simple and training-free, while outperforming state-of-the-art image editing baselines.
Neural Pose Representation Learning for Generating and Transferring Non-Rigid Object Poses
Jun 14, 2024



We propose a novel method for learning representations of poses for 3D deformable objects, which specializes in 1) disentangling pose information from the object's identity, 2) facilitating the learning of pose variations, and 3) transferring pose information to other object identities. Based on these properties, our method enables the generation of 3D deformable objects with diversity in both identities and poses, using variations of a single object. It does not require explicit shape parameterization such as skeletons or joints, point-level or shape-level correspondence supervision, or variations of the target object for pose transfer. To achieve pose disentanglement, compactness for generative models, and transferability, we first design the pose extractor to represent the pose as a keypoint-based hybrid representation and the pose applier to learn an implicit deformation field. To better distill pose information from the object's geometry, we propose the implicit pose applier to output an intrinsic mesh property, the face Jacobian. Once the extracted pose information is transferred to the target object, the pose applier is fine-tuned in a self-supervised manner to better describe the target object's shapes with pose variations. The extracted poses are also used to train a cascaded diffusion model to enable the generation of novel poses. Our experiments with the DeformThings4D and Human datasets demonstrate state-of-the-art performance in pose transfer and the ability to generate diverse deformed shapes with various objects and poses.
SyncTweedies: A General Generative Framework Based on Synchronized Diffusions
Mar 22, 2024



We introduce a general framework for generating diverse visual content, including ambiguous images, panorama images, mesh textures, and Gaussian splat textures, by synchronizing multiple diffusion processes. We present exhaustive investigation into all possible scenarios for synchronizing multiple diffusion processes through a canonical space and analyze their characteristics across applications. In doing so, we reveal a previously unexplored case: averaging the outputs of Tweedie's formula while conducting denoising in multiple instance spaces. This case also provides the best quality with the widest applicability to downstream tasks. We name this case SyncTweedies. In our experiments generating visual content aforementioned, we demonstrate the superior quality of generation by SyncTweedies compared to other synchronization methods, optimization-based and iterative-update-based methods.
Posterior Distillation Sampling
Nov 23, 2023



We introduce Posterior Distillation Sampling (PDS), a novel optimization method for parametric image editing based on diffusion models. Existing optimization-based methods, which leverage the powerful 2D prior of diffusion models to handle various parametric images, have mainly focused on generation. Unlike generation, editing requires a balance between conforming to the target attribute and preserving the identity of the source content. Recent 2D image editing methods have achieved this balance by leveraging the stochastic latent encoded in the generative process of diffusion models. To extend the editing capabilities of diffusion models shown in pixel space to parameter space, we reformulate the 2D image editing method into an optimization form named PDS. PDS matches the stochastic latents of the source and the target, enabling the sampling of targets in diverse parameter spaces that align with a desired attribute while maintaining the source's identity. We demonstrate that this optimization resembles running a generative process with the target attribute, but aligning this process with the trajectory of the source's generative process. Extensive editing results in Neural Radiance Fields and Scalable Vector Graphics representations demonstrate that PDS is capable of sampling targets to fulfill the aforementioned balance across various parameter spaces.
SALAD: Part-Level Latent Diffusion for 3D Shape Generation and Manipulation
Mar 21, 2023We present a cascaded diffusion model based on a part-level implicit 3D representation. Our model achieves state-of-the-art generation quality and also enables part-level shape editing and manipulation without any additional training in conditional setup. Diffusion models have demonstrated impressive capabilities in data generation as well as zero-shot completion and editing via a guided reverse process. Recent research on 3D diffusion models has focused on improving their generation capabilities with various data representations, while the absence of structural information has limited their capability in completion and editing tasks. We thus propose our novel diffusion model using a part-level implicit representation. To effectively learn diffusion with high-dimensional embedding vectors of parts, we propose a cascaded framework, learning diffusion first on a low-dimensional subspace encoding extrinsic parameters of parts and then on the other high-dimensional subspace encoding intrinsic attributes. In the experiments, we demonstrate the outperformance of our method compared with the previous ones both in generation and part-level completion and manipulation tasks.
PartGlot: Learning Shape Part Segmentation from Language Reference Games
Dec 13, 2021
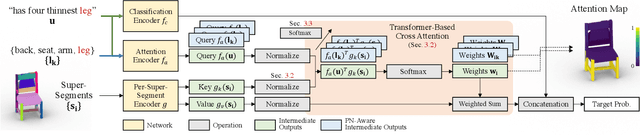


We introduce PartGlot, a neural framework and associated architectures for learning semantic part segmentation of 3D shape geometry, based solely on part referential language. We exploit the fact that linguistic descriptions of a shape can provide priors on the shape's parts -- as natural language has evolved to reflect human perception of the compositional structure of objects, essential to their recognition and use. For training, we use the paired geometry / language data collected in the ShapeGlot work for their reference game, where a speaker creates an utterance to differentiate a target shape from two distractors and the listener has to find the target based on this utterance. Our network is designed to solve this target discrimination problem, carefully incorporating a Transformer-based attention module so that the output attention can precisely highlight the semantic part or parts described in the language. Furthermore, the network operates without any direct supervision on the 3D geometry itself. Surprisingly, we further demonstrate that the learned part information is generalizable to shape classes unseen during training. Our approach opens the possibility of learning 3D shape parts from language alone, without the need for large-scale part geometry annotations, thus facilitating annotation acquisition.